【Rocksdb实现分析及优化】FileIndexer
leveldb和rocksdb在大于0层中查找某个key,往往都是先在version中对应该层的全局有序的所有sst文件中进行二分查找定位第一个user_key在其key range中的文件,然后开始进行具体sst文件中查找,如果某层sst文件特别多,为了加快二分查找的速度,rocksdb用了FileIndexer,具体什么意思呢,就是假设在Level N的文件A中进行查找没找到,那么可以通过A在FileIndexer中找出其对应的在Level N+1层文件索引的left_bound和right_bound,这个范围往往是Level N+1层所有sst文件的一个子范围,在这里面进行二分查找会更快。
FileIndexer
从Level 1开始到倒数第二层结束,每个sst都会有自己所对应的,下一层文件索引的子范围,具体怎么算的呢,很简单,因为每层全局有序,每个文件内部有序,那么通过每个文件的smallest_key和largest_key就可以算出来啦
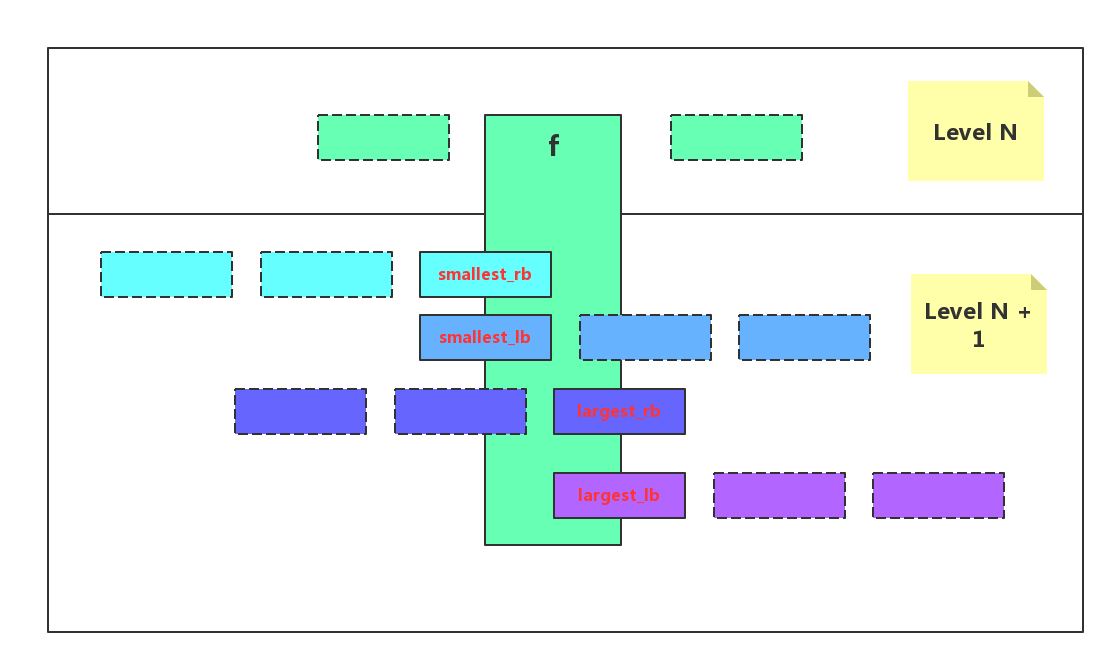
上图有四个关键的值,对于Level N层的文件f,它有自己的smallest_key及largest_key,在Level N+1层需要算出其需要的4个值,分别是:
1. smallest_rb:在Level N+1中满足包含大于smallest_key的key条件最右边的sst文件位置索引
2. smallest_lb:在Level N+1中满足包含大于smallest_key的key条件最左边的sst文件位置索引
3. largest_rb:在Level N+1中满足包含小于largest_key的key条件最右边的sst文件位置索引
4. largest_lb:在Level N+1中满足包含小于largest_key的key条件最左边的sst文件位置索引
有了这4个值,假设此时用户查找一个user_key,level 0全部不命中,开始在Level 1中查找,首先通过二分查找找到Level 1中找到第一个largest_key大于等于user_key的sst文件(注:如果user_key小于Level 1全局最小key,则对应第一个sst文件,如果user_key大于Level 1全局最大key,则对应最后一个文件),假设就是上图的f是在Level 1中第一个满足条件的sst文件,那么此时关于f在Level 2中对应的查找子范围,有以下5中情况:
1. user_key < smallest_key: 如果f是Level 1最左文件,即index = 0,则Level 2的
left_bound = 0,如果index不等于0,则left_bound等于f前一个文件,即index-1对应的
文件的largest_lb,right_bound = f的smallest_rb
2. user_key == smallest_key: left_bound = f的smallest_lb,
right_bound = f的smallest_rb
3. user_key > smallest_key && user_key < largest_key:
left_bound = f的smallest_lb,right_bound = f的largest_rb
4. user_key == largest_key: left_bound = f的largest_lb,
right_bound = f的largest_rb
5. user_key > largest_key: left_bound = f的largest_rb,
right_bound = Level 2最右sst
这样,每次在f不命中的情况下,通过匹配上述5种情况,利用f的smallest_lb,smallest_rb,largest_rb,largest_lb算出在下一个Level进行查找的若干sst文件的left_bound和right_bound,如果f是本层范围符合可查找user_key的最后一个sst文件(注:如果user_key == f的largest_key,那么即使f没命中,也需要继续在f的下一个sst文件中进行查找,而不能直接跳到下一层),此时就可以利用刚才算出的f对应于下一层的left_bound和right_bound直接在下一个Level开始局部二分查找。
FileIndex信息维护
关于每个sst文件对应的4个值是在每一层compaction结束,执行LogAndApply的时候更新的,刚open的时候也会执行一次compaction,所以open之后index信息就已经生成成功。
优化效果
如果db很大,尤其是在最后一层文件超级多的情况下,假设16384个,那么进行全局二分查找的代价差不多是Log2(16384) = 13,而如果有了子范围查询,在倒数第二层没有命中的情况下,根据放大系数max_bytes_for_level_multiplier = 10,差不多在最后一层10个sst文件范围内进行二分查找,代价差不多是Log2(10) = 3,的确可以减少二分查找的次数,总体来看是将比较次数从N^L减少到N,(N是放大系数,L是具体某一层)
但个人认为FileIndex信息的维护同样需要代价,它会一定程度上延长compaction的执行时间,好在此处compaction执行时间稍长并不会严重影响正常的读性能,所以通过这种后台异步预先计算索引的方式,应该是可以提高部分读性能的,具体优化多少还需要后续再测试给出。
总结
这个优化其实没什么精妙之处,我觉得但凡正常用心的人都能想出来,不过这么小的点,想出来是一回事,做出来是另一回事,看看FileIndex.h和.cc的代码行数就知道,rocksdb的确做的很细致,代码值得学习,态度更值得学习^^(为何要给自己灌鸡汤…)