这一篇主要是从TCMalloc最下层的内存管理模块入手,介绍一下PageHeap的实现。TCMalloc无论自己怎么管理内存,这些内存肯定都是要通过向操作系统来申请的,那么什么时候申请呢?申请到的内存该怎么管理呢?什么时候还给操作系统呢?这些就是PageHeap要做的事情啦。我们以32位系统为例,详细介绍一下。
结构
我们知道32位地址对应的最大内存为4G,也就是在最坏情况下,PageHeap要hold住这4G的空间,并且准确的知道哪块内存已经用了,哪块内存没用,哪些连续的内存可以合并成更大的可用内存,该怎么做呢?
对,从内存地址入手!不管怎么着,PageHeap肯定要通过brk或者mmap来向操作系统申请内存,得到的是一个(void*)指针,4个字节,那么4G的内存对应的地址范围就是(0x00000000 ~ 0xFFFFFFFF),我们知道PageHeap定义的1页为8K,也就是地址的低13位是页内偏移,高19位则是页索引,最简单的办法就是用一个一维数组,一共1«19个元素,每个元素指向其对应的1页,不过这样的一维设计有点太简单粗暴,TCMalloc采用的是2级映射,高19位继续分成5位和14位,如下图上半部分所示:
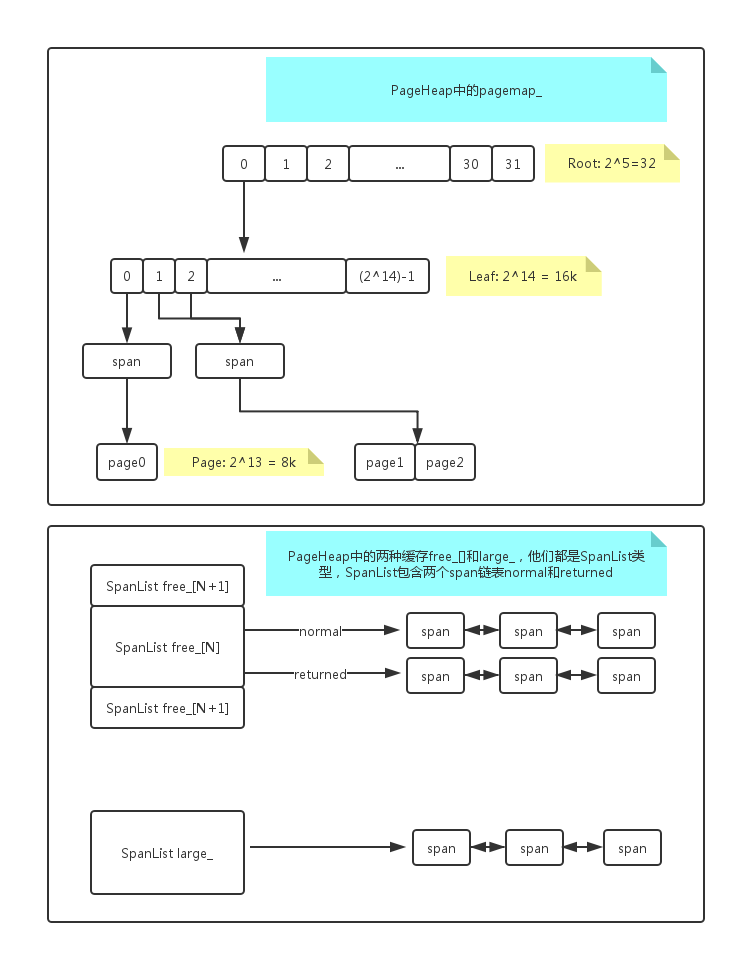
先不管span,这其实就是一个2维数组,定义如下:
template <int BITS>
class TCMalloc_PageMap2 {
private:
// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.
static const int ROOT_BITS = 5;
static const int ROOT_LENGTH = 1 << ROOT_BITS;
static const int LEAF_BITS = BITS - ROOT_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes
root有32个元素,每个元素指向一个leaf,每个leaf有2^14=16k个元素,每个元素其实就是指向一个页,这样通过5->14->13,可以将4G的地址空间准确的定位,这里有一个优化,如果leaf的每个元素都直接指向一个页,那一页一页管理起来很麻烦,所以TCMalloc在中间加入了一层span,顾名思义,就是连续内存的一片范围,定义如下:
struct Span {
PageID start; // Starting page number
Length length; // Number of pages in span
Span* next; // Used when in link list
Span* prev; // Used when in link list
void* objects; // Linked list of free objects
unsigned int refcount : 16; // Number of non-free objects
unsigned int sizeclass : 8; // Size-class for small objects (or 0)
unsigned int location : 2; // Is the span on a freelist, and if so, which?
unsigned int sample : 1; // Sampled object?
#undef SPAN_HISTORY
#ifdef SPAN_HISTORY
// For debugging, we can keep a log events per span
int nexthistory;
char history[64];
int value[64];
#endif
// What freelist the span is on: IN_USE if on none, or normal or returned
enum { IN_USE, ON_NORMAL_FREELIST, ON_RETURNED_FREELIST };
};
来看span主要的成员的,start说白了就是地址的高19位,length就是这个span包含了几页,从上图来看,leaf的第2,3个元素指向同一个span,那么第2,3个元素对应的第2,3个页也就属于该span,start = 0x00000001, length = 2, 看到next和prev就能猜到每个span之间可以穿成一个链表,objects我们上一篇讲到,PageHeap在把页返回给特定central_freelist时,会根据central_freelist的属性把1页划分成多个objects,然后返回一些个objects给central_freelist,所以这里的objects其实就是当前可用的第一个objects的地址,下次要用的时候直接从这拿就好了,每个objects虽然紧挨着,不过这里的实现还是将串成list,类似数组链表的实现方式,refcount其实就是记录已经分配出去的objects的个数,如果为0就代表本span对应的所有页都已经没用了,可以回收。
基本的东西就这些了,下面直接上代码看PageHeap如何New和Delete内存的,代码重要的地方加了注释
//这里看以看到New返回的是一个Span的指针,由这个Span来管理申请的页
Span* PageHeap::New(Length n) {
ASSERT(Check());
ASSERT(n > 0);
//从当前已有的缓存里找有没有合适的,有的话直接分配,返回
Span* result = SearchFreeAndLargeLists(n);
if (result != NULL)
return result;
// Grow the heap and try again.
//缓存不够,需要向系统申请新的
if (!GrowHeap(n)) {
ASSERT(Check());
return NULL;
}
//GrowHeap新申请的内存还是会先放在缓存中,所以这里再从缓存中分配一次
return SearchFreeAndLargeLists(n);
}
Span* PageHeap::SearchFreeAndLargeLists(Length n) {
ASSERT(Check());
ASSERT(n > 0);
// Find first size >= n that has a non-empty list
//对应0~127个页,每一个length都有自己的free_链表,元素是SpanList指针,SpanList包含
//两个span指针的链表,分别叫normal和returned,normal代表已经申请到的目前可用的内存
//,returned代表已经调用fadvise还给操作系统的内存,然后从n开始直到找到第一个合适的
//span,然后分配
for (Length s = n; s < kMaxPages; s++) {
//先找normal
Span* ll = &free_[s].normal;
// If we're lucky, ll is non-empty, meaning it has a suitable span.
if (!DLL_IsEmpty(ll)) {
ASSERT(ll->next->location == Span::ON_NORMAL_FREELIST);
//找到了,切分这个span,其实就是假如我要4个页,但free_[4]已经没有多余可用的了,
//free_[5]有,所以从free_[5]中取出一个span,free_[5]中每个span包含5页,所以修
//改这个span的信息让它包含前4个页,返回,多余1个页重新包一个新的span,插入
//到free_[1]中
return Carve(ll->next, n);
}
// Alternatively, maybe there's a usable returned span.
//在returned查找
ll = &free_[s].returned;
if (!DLL_IsEmpty(ll)) {
ASSERT(ll->next->location == Span::ON_RETURNED_FREELIST);
return Carve(ll->next, n);
}
}
// No luck in free lists, our last chance is in a larger class.
//很不幸,上面都没有,我们尝试从大内存的缓存链表中找,也就是large_链表中找,large_链表
//是没有走`thread_cache`和`central_list`,直接从PageHeap申请的内存用完还回来以后的缓存
//或者是在Delete操作时多个可用的相邻小span拼出一个大的(256k内存)span插入到large_中的,
//如果这里还没有,就返回NULL
return AllocLarge(n); // May be NULL
}
代码逻辑还是很清晰的,下面看看GrowHeap()如何实现:
bool PageHeap::GrowHeap(Length n) {
ASSERT(kMaxPages >= kMinSystemAlloc);
if (n > kMaxValidPages) return false;
//每次向系统申请最少128页
Length ask = (n>kMinSystemAlloc) ? n : static_cast<Length>(kMinSystemAlloc);
size_t actual_size;
void* ptr = TCMalloc_SystemAlloc(ask << kPageShift, &actual_size, kPageSize);
if (ptr == NULL) {
if (n < ask) {
// Try growing just "n" pages
ask = n;
//如果申请失败,则缩小ask成n,再次向系统申请内存
ptr = TCMalloc_SystemAlloc(ask << kPageShift, &actual_size, kPageSize);
}
if (ptr == NULL) return false;
}
ask = actual_size >> kPageShift;
RecordGrowth(ask << kPageShift);
uint64_t old_system_bytes = stats_.system_bytes;
stats_.system_bytes += (ask << kPageShift);
const PageID p = reinterpret_cast<uintptr_t>(ptr) >> kPageShift;
ASSERT(p > 0);
// If we have already a lot of pages allocated, just pre allocate a bunch of
// memory for the page map. This prevents fragmentation by pagemap metadata
// when a program keeps allocating and freeing large blocks.
if (old_system_bytes < kPageMapBigAllocationThreshold
&& stats_.system_bytes >= kPageMapBigAllocationThreshold) {
pagemap_.PreallocateMoreMemory();
}
// Make sure pagemap_ has entries for all of the new pages.
// Plus ensure one before and one after so coalescing code
// does not need bounds-checking.
//Ensure其实就是保证本次申请的一批连续页,它前一个页和后一个页对应的leaf已经生成,方便在
//今后内存归还的时候可以合并成更大的一段连续页
if (pagemap_.Ensure(p-1, ask+2)) {
// Pretend the new area is allocated and then Delete() it to cause
// any necessary coalescing to occur.
//创建一个新的span记录这段内存,span是由PageHeapAllocator来创建的,主要也是一下申请一批
//,一个一个分配,每个span穿成数组链表方便维护,代码挺有意思的,大家可以去看看
Span* span = NewSpan(p, ask);
RecordSpan(span);
//Delete做了挺多事情,其实他就是把这个span挂到对应的free_链表下,这里多做的一个东西就
//是它会先检查一下这个span对应内存左右两边临近内存的span是不是可以合并,如果左右两边
//的内存当前也没有正在使用,就删掉这些span,并合成一个大的span,小span们之前负责的所
//有内存页现在都有这个新的span负责,然后再插入free_或者large_中,视大小而定
Delete(span);
ASSERT(Check());
return true;
} else {
// We could not allocate memory within "pagemap_"
// TODO: Once we can return memory to the system, return the new span
return false;
}
}
细节与疑问
好了,New和Delete的实现差不多就是上面的了,顺便多说一句,New出来的一批页,需要在pagemap_里的对应位置注册一下,就是将对应地址的leaf上对应位置所有的元素都指向New出来的这批页所对应的span上,方便以后查询,具体实现是在RegisterSizeClass里实现的
说完了主体,再说一下边边角角的东西,关于内存归还的策略,这里我代码是看懂了,不过具体策略还是有些不清,我先按我的理解说一下吧:
在每次Delete的最后一步,就是将上层释放出来并插入到缓存(free_或者large_)的页数n,调用一下IncrementalScavenge(n),做一下尝试内存归还的操作,代码如下:
void PageHeap::IncrementalScavenge(Length n) {
// Fast path; not yet time to release memory
scavenge_counter_ -= n;
if (scavenge_counter_ >= 0) return; // Not yet time to scavenge
const double rate = FLAGS_tcmalloc_release_rate;
if (rate <= 1e-6) {
// Tiny release rate means that releasing is disabled.
scavenge_counter_ = kDefaultReleaseDelay;
return;
}
Length released_pages = ReleaseAtLeastNPages(1);
if (released_pages == 0) {
// Nothing to scavenge, delay for a while.
scavenge_counter_ = kDefaultReleaseDelay;
} else {
// Compute how long to wait until we return memory.
// FLAGS_tcmalloc_release_rate==1 means wait for 1000 pages
// after releasing one page.
const double mult = 1000.0 / rate;
double wait = mult * static_cast<double>(released_pages);
if (wait > kMaxReleaseDelay) {
// Avoid overflow and bound to reasonable range.
wait = kMaxReleaseDelay;
}
scavenge_counter_ = static_cast<int64_t>(wait);
}
scavenger_counter_初始值是0,每次进来判断如果小于0才继续往下,所以第一次的Delete肯定会进来,rate是一个参数,大概的作用就是如果此时的PageHeap可以从free_或者large_缓存的span链表中,任意一个链表最末尾的span对应的页们还给操作系统(ReleaseAtLeastNPages(1)),那么本次假设还了N页,则直到今后上层再向PageHeap累计释放1000N页之后,再从自己的缓存中取一个可还的span还给操作系统
有一个地方比较奇怪,居然会在ReleaseAtLeastNPages(1)之后,判断released_pages == 0,感觉不可能等于0啊,因为在ReleaseAtLeastNPages(1)之前,肯定会有一个空闲的span被上层调用PageHeap::Delete返回给PageHeap的缓存链表(free_或者large_),所以不会为0,这个问题先留着,等下篇写central_freelist的时候没准就知道答案了
对了还有一个地方要说明,开始我以为返回给操作系统的意思就是这段内存再也不用了,看代码发下他的实现是这样的:
Length PageHeap::ReleaseLastNormalSpan(SpanList* slist) {
Span* s = slist->normal.prev;
ASSERT(s->location == Span::ON_NORMAL_FREELIST);
RemoveFromFreeList(s);
const Length n = s->length;
TCMalloc_SystemRelease(reinterpret_cast<void*>(s->start << kPageShift),
static_cast<size_t>(s->length << kPageShift));
s->location = Span::ON_RETURNED_FREELIST;
MergeIntoFreeList(s); // Coalesces if possible.
return n;
}
真正释放的函数TCMalloc_SystemRelease实际是调用madvise来告诉系统Indicates that the application is not expecting to access this address range soon.,有意思的是在他的前后分别调用了RemoveFromFreeList和MergeIntoFreeList,第一个是从指定free_的normal链表中拿出来最后一个span,这个span并没有删除,而是修改了一下location的属性,再次插入回了free_,不过这次肯定不是插入到free_的normal链表,而是returned链表,这个returned的链表上面也说过,在New的时候也会尝试从里面取,不过这里面的span对应的内存页不是可能已经被操作系统回收了吗?这里的细节以后还需要再细细抠一下
总结
PageHeap的实现代码很容易看懂,写的很好,不过一些细节还是要慢慢琢磨才行,好啦,下一篇该讲central_freelist了,下篇见^^