1. Experiment
By running this script, you can generate an extremely sparse B+Tree in an InnoDB table with just simple INSERT statements:
#!/bin/bash
# Define the MySQL command path
MYSQL_CMD="/PATH/TO/mysql -h127.0.0.1 -P3306 -uroot"
# Create database and table if not already existing
$MYSQL_CMD -e "
CREATE DATABASE IF NOT EXISTS test;
USE test;
DROP TABLE IF EXISTS tbl;
CREATE TABLE tbl (
pk INT,
val CHAR(240) NOT NULL DEFAULT 'a',
PRIMARY KEY(pk)
) ENGINE=InnoDB, CHARSET=LATIN1;
"
# Insert initial values from 1 to 32
for i in {1..32}
do
echo "Inserting $i"
$MYSQL_CMD -e "INSERT INTO test.tbl(pk) VALUES($i)"
done
# Insert values from 10000001 to 10000027
for i in {10000001..10000027}
do
echo "Inserting $i"
$MYSQL_CMD -e "INSERT INTO test.tbl(pk) VALUES($i)"
done
# 1 leaf page splits into 2 leaf pages: [1 ... 30],[31, 32, 10000001 ... 10000027]
# Insert values from 10000028 to 10000054
for i in {10000028..10000054}
do
echo "Inserting $i"
$MYSQL_CMD -e "INSERT INTO test.tbl(pk) VALUES($i)"
done
# Insert alternating values starting from 33 to 999
for ((i=33; i<1000; i+=2))
do
j=$((i+1))
echo "Inserting $j and $i"
$MYSQL_CMD -e "INSERT INTO test.tbl(pk) VALUES($j)"
$MYSQL_CMD -e "INSERT INTO test.tbl(pk) VALUES($i)"
done
The tbl table contains 2 columns: a pk (INT) and a val (CHAR(240)). Each record has the following size:
262B = 4B (pk) + 240B (val) + 5B (HEADER) + 6B (TRX_ID) + 7B (ROLL_PTR)
InnoDB’s default page size is 16KB. After accounting for the page header, trailer, record slots, and reserved page space size(1024B), each page can store up to 58 records for the tbl table defined above. In the script, we inserted a total of 1054 records. Let’s see how many leaf pages the B+Tree has after the insertion.

468 leaf pages! This is far more than the 19 pages theoretically needed to store 1054 records (1054 / 58 = 19 pages). The B+Tree has expanded by a factor of 25 (468 / 19). After running the OPTIMIZE TABLE command to reorganize the B+Tree, we find that the optimized B+Tree uses only 19 leaf pages, matching our calculations.
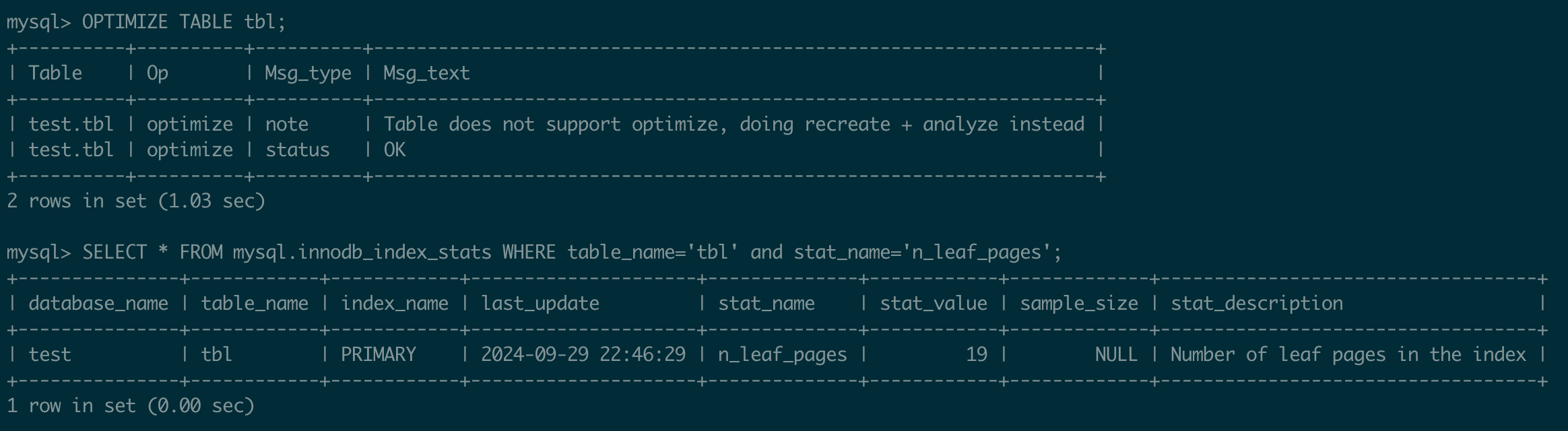
19 leaf pages after ‘OPTIMIZE TABLE’ So, why does this script cause the B+Tree to expand so much? Let’s analyze the reasons below.
2. Analysis
InnoDB organizes data using the B+Tree, and one of its key operations is the Structure Modification Operation (SMO). When a page becomes full, it splits into a new page, migrating some data to this new page, and linking it into the doubly linked list of leaf pages. This operation creates room for new records. However, here is a question: which data should be migrated to the new page?
1. General Splitting Strategy: Splitting the Page at the Middle
This is the most common splitting strategy in a B+Tree. As shown below:
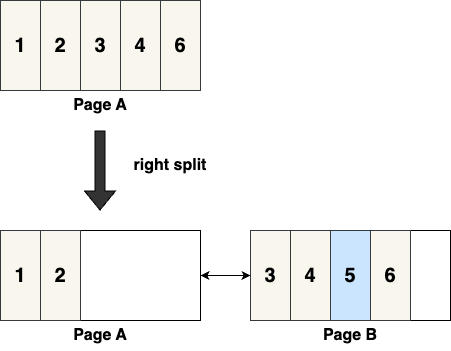
Assume a page can store up to 5 records, and page A contains [1, 2, 3, 4, 6]. Inserting 5 will trigger an SMO. The middle record (3) is selected, and records [3, 4, 6] are migrated to a new page B, leaving space in both the old and new pages. The insertion of 5 will then occur in page B, resulting in [3, 4, 5, 6], completing the SMO.
This strategy works well in most cases, but there are situations where it is not optimal.
2. Special Case: Sequential Inserts
Consider a scenario where records are inserted in descending order, e.g., 20, 19, 18… 3, 2, 1. If the standard splitting strategy is applied here, it will result in page space being wasted, as shown below:
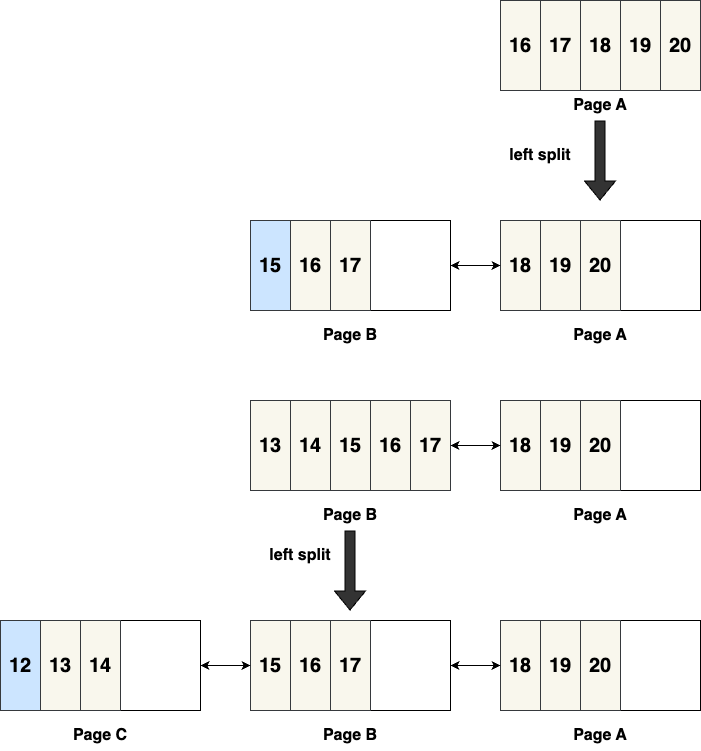
First, insert records from 20 to 16 into page A. When inserting 15, an SMO will occur, splitting page A into [16, 17] and [18, 19, 20], and 15 will be inserted into the new page B, forming [15, 16, 17] [18, 19, 20]. Continuing with descending inserts (14, 13), page B will eventually fill up. When inserting 12, page B will split into a new page C. As you can see, this scenario will lead to a 50% space waste on each page.
3. Optimized Splitting Strategy
To address this sequential insert case, InnoDB optimizes its splitting strategy. In this case, instead of migrating data from the old page to the new one, only the record being inserted is placed in the new page, as shown below:
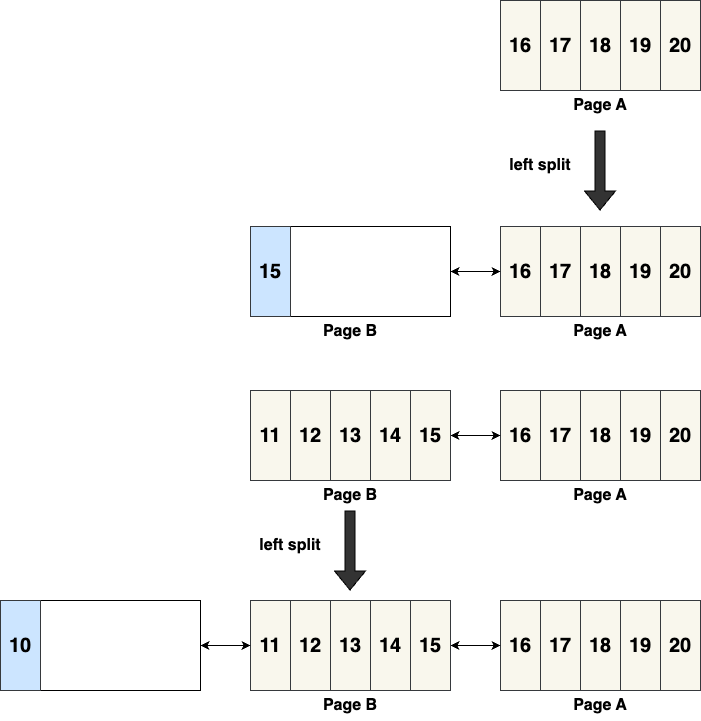
In this scenario, when page A fills up with [16, 17, 18, 19, 20], inserting 15 will trigger a left split, creating a new page B without migrating any records. Only 15 is inserted into page B, leaving no wasted space.
4. Additional Problem
Although this optimized splitting strategy works well for sequential inserts, there are still cases where it can lead to inefficiencies. For example, if three records [1, 2, 3] are inserted first (from the smallest end), followed by descending inserts from 20, the optimized strategy may fail.
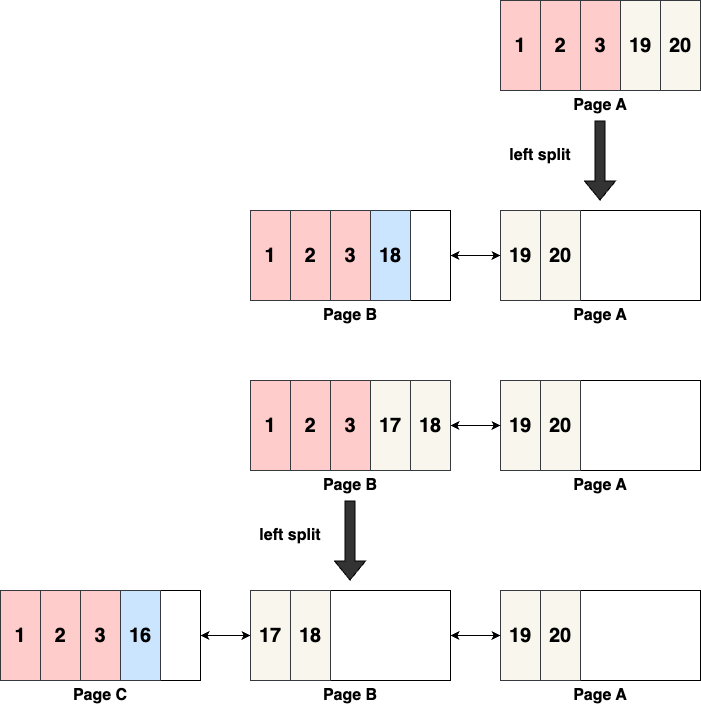
When inserting 18, since [1, 2, 3] already exists in page A, they must be migrated to the new page B. After several more inserts, [1, 2, 3] will need to be moved again and again, leading to repeated movement of these records and wasted space.
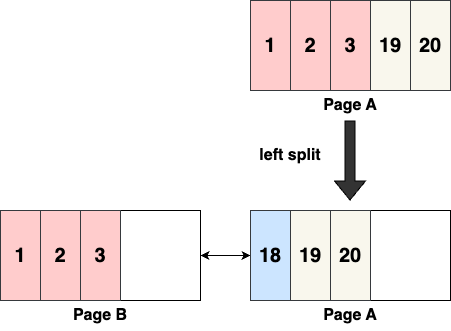
To mitigate this, InnoDB makes an adjustment. Instead of inserting 18 into the new page B, it is inserted into the old page A, isolating [1, 2, 3] in page B, then the subsequent inserts can follow the optimized strategy, reducing repeated movements and space waste.
5. It’s time to apply a Hack!
InnoDB’s evolving splitting strategy gives us an opportunity to exploit certain conditions to create sparse B+Trees. Let’s analyze the conditions for triggering these strategies:
How does InnoDB determine if sequential inserts are happening? This is quite simple. After each insert, InnoDB records the insert position as PAGE_LAST_INSERT. If the next insert is immediately to the left or right of this position, InnoDB assumes that sequential inserts are occurring and applies the optimized splitting strategy. How does InnoDB determine where to insert new records after a split? If InnoDB detects a left split due to descending inserts, it will only place the new record into the new page if it is the smallest or second smallest record. Otherwise, it will keep the current insert point in the old page.
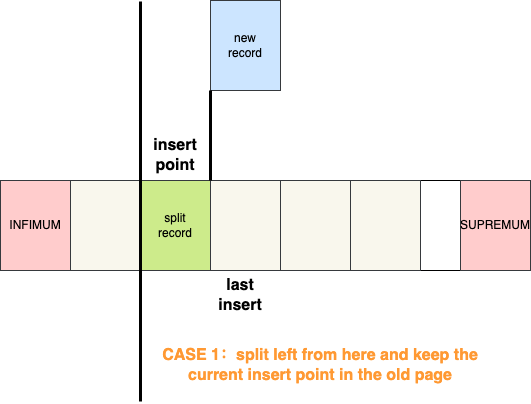
The case that keeps the current insert point in the old page
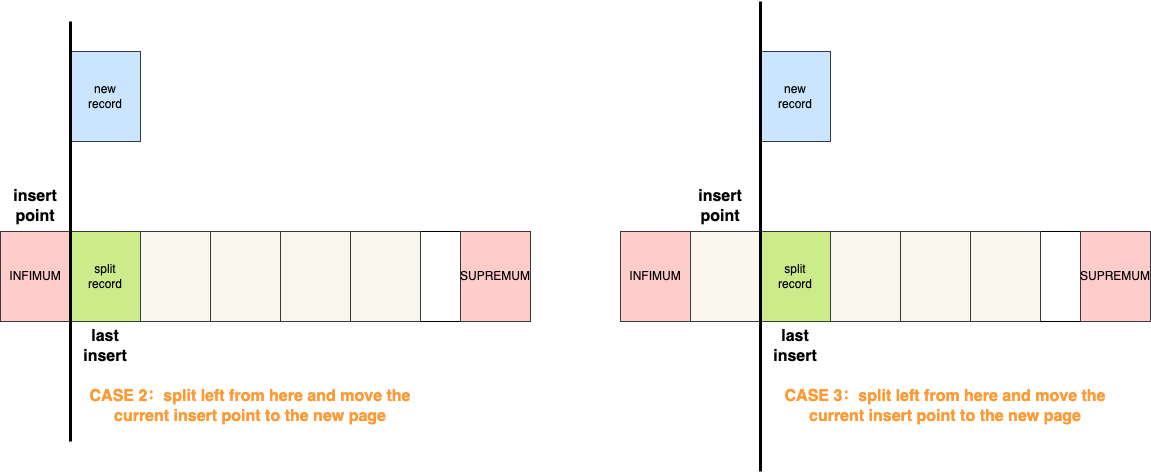
The cases that move the current insert point to the new page
By exploiting these two conditions, now we can construct specific insert patterns to hack InnoDB and force it to create sparse B+Trees:
- Right before triggering an SMO (when there is only enough free space for two more records in the page), perform two consecutive descending inserts. This tricks InnoDB into thinking that sequential inserts are occurring, prompting it to use the optimized splitting strategy.
- Always insert at the third position in the page, ensuring that the current insertion point remains in the old page. This forces only two records to be migrated to the new page during each SMO, keeping the majority of records in the original page.
By repeating this process, we can create an extremely sparse B+Tree, where each leaf page stores only two records, leading to significant space waste.
3. How to Fix This
Of course, a more comprehensive split strategy is needed. But for a quick fix, it can be addressed by targeting the two conditions mentioned earlier:
More accurate detection of sequential inserts: InnoDB shouldn’t rely solely on just two consecutive inserts to determine sequential insertion patterns. Instead, it should leverage the PAGE_N_DIRECTION statistic, which tracks the number of consecutive inserts, to make better-informed decisions about when to use the optimized splitting strategy. Better split point selection: The insertion point after a split should be determined by considering the density of both the new and old pages, along with the predicted current insertion pattern. This would help reduce the frequency of SMOs and prevent space wastage.
In summary, while InnoDB’s current SMO splitting strategy functions adequately, it still has room for significant optimization. I’ve already reported it#110412 to the MySQL verification team, where it has been verified, although it remains unresolved.