InnoDB看了有一阵子了,由于之前没有总结,走马观花看过一些的fsp,btr,page基本都忘差不多了…这两天刚好有时间,整理下redo log模块这里的东西,后面的东西再边看边总结吧
【版本:mysql-8.0.12】
1. Mini Transaction(mtr)
InnoDB会将事务执行过程拆分为若干个Mini Transaction(mtr),每个mtr包含一系列如加锁,写数据,写redo,放锁等操作。举个例子:
void btr_truncate(const dict_index_t *index) {
... ...
page_size_t page_size(space->flags);
const page_id_t page_id(space_id, root_page_no);
mtr_t mtr;
buf_block_t *block;
mtr.start();
mtr_x_lock(&space->latch, &mtr);
block = buf_page_get(page_id, page_size, RW_X_LATCH, &mtr);
page_t *page = buf_block_get_frame(block);
ut_ad(page_is_root(page));
/* Mark that we are going to truncate the index tree
We use PAGE_MAX_TRX_ID as it should be always 0 for clustered
index. */
mlog_write_ull(page + (PAGE_HEADER + PAGE_MAX_TRX_ID), IB_ID_MAX, &mtr);
mtr.commit();
... ...
}
btr_truncate函数将一个BTree truncate到只剩root节点,具体实现这里暂不用关心,不过上面有一步是需要将root page header的PAGE_MAX_TRX_ID修改为IB_ID_MAX,这个操作算是修改page上的数据,这里就需要通过mtr来做,具体:
- mtr.start() 开启一个mini transaction
- mtr_x_lock() 加锁,这个操作分成两步,1. 对space->latch加X锁;2. 将space->latch放入mtr_t::m_impl::memo中(这样在mtr.commit()后就可以将mtr之前加过的锁放掉)
- mlog_write_ull 写数据,这个操作也分成两步,1. 直接修改page上的数据;2. 将该操作的redo log写入mtr::m_impl::m_log中
- mtr.commit() 写redo log + 放锁,这个操作会将上一步m_log中的内容写入redo log file,并且在最后放锁
以上就是一个mtr大致的执行过程,这里仅需要知道mtr.commit()是开始写redo log的地方就可以了。
2. redo log 概述
在具体看代码之前,先说下InnoDB redo log的一些特点:
- 顺序写,每个mtr的redo log追加到文件末尾
- 单个文件大小固定,写满之后会切换到下一个文件
- 文件个数固定,写完最后一个之后会回绕到第一个文件开始继续写。
- 每个文件有2K的FileHeader
- FileHeader之后是一个个512B的Block,每个Block包含12字节BlockHeader,4字节BlockTrailer,中间则是实际redo log的内容
- 概念上有一个全局递增的SN和LSN,SN对应所有写入的redo log原始内容的序列号,LSN则是原始内容包含BlockHeader和BlockTrailer之后的序列号,二者可以互相转换,LSN主要有2个用处:
- 每个mtr的redo log都有对应的[start_lsn, end_lsn],通过换算,便可以拿到实际文件对应的写入位置
- 每个mtr的redo log都有对应修改数据文件的脏页,拿redo log的LSN作为脏页的LSN,因为LSN有序递增,所以后台刷脏页的线程便可以根据每个脏页的LSN知道它们产生的先后顺序,根据此顺序控制落盘
3. 偏移量计算
先上图:
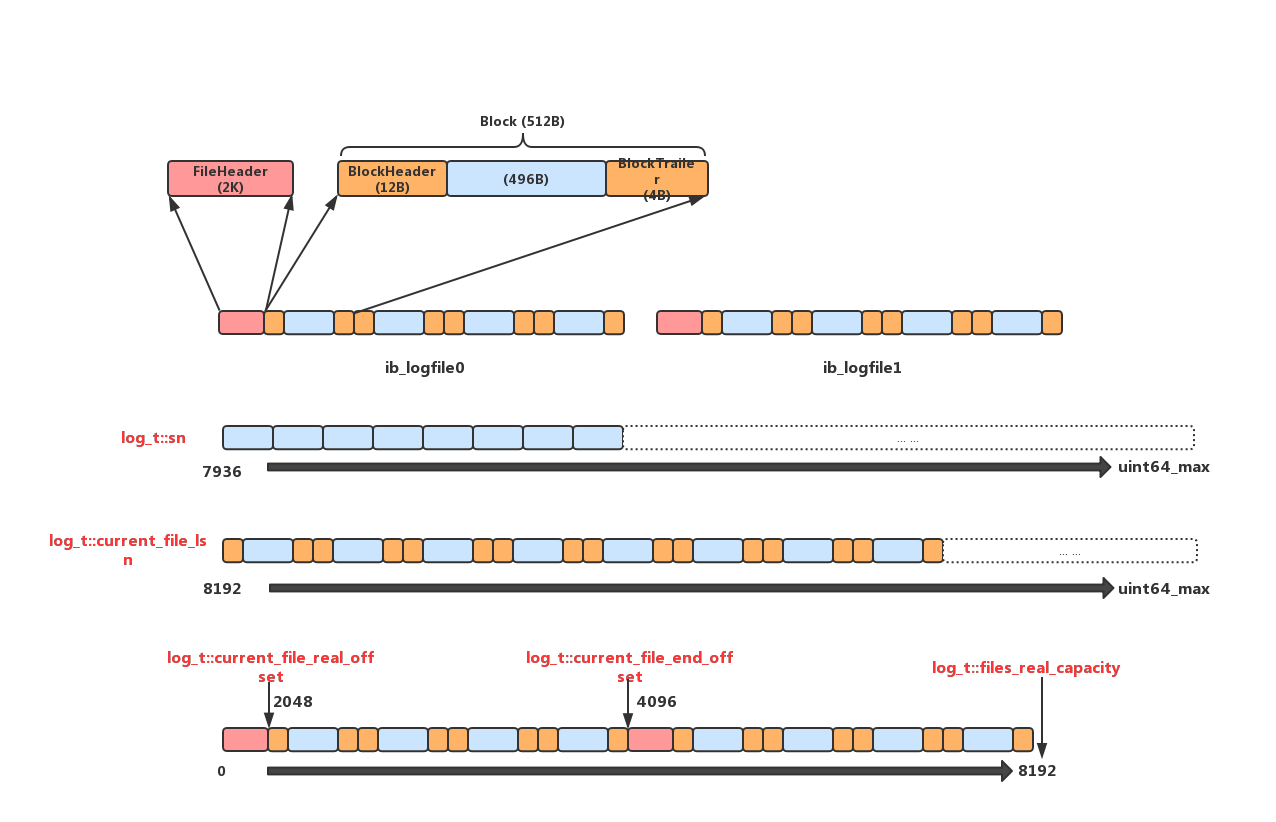
图中有两个redo log文件,ib_logfile0和ib_logfile1,每个文件4K(包含2K的FileHeader和4个512B的Block),下面就来看下InnoDB是如何使用这2个文件来管理redo log的:
第一层连续蓝色块是要写的redo log原始内容,sn作为原始内容的序列号,初始值是7936,随着写入增加,每次增加一个mtr中原始log的长度。不过实际写入文件中的并不只是原始内容,InnoDB会将原始内容按496B为单位切分,加上16B的BlockHeader和BlockTrailer,凑成一个512B的Block,这样实际写入log文件的内容是类似图中第二层的格式,一个Block接一个Block。由于sn只表示原始内容的序列号,现在加入了Header和Trailer,那么对应的变化之后的序列号就由current_file_lsn来表示,初始值为8192,sn和current_file_lsn相互转换方式如下:
// sn 转换到 lsn
// 给sn每496B都增加16B的头尾,结果即为对应的lsn
constexpr inline lsn_t log_translate_sn_to_lsn(lsn_t sn) {
return (sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE +
sn % LOG_BLOCK_DATA_SIZE + LOG_BLOCK_HDR_SIZE);
}
// lsn 转换到 sn
// 给lsn每512B都减去16B的头尾,再加上最后一个不完整的Block内偏移,减去
// 该Block的Header 12B,结果即为对应的sn
inline lsn_t log_translate_lsn_to_sn(lsn_t lsn) {
/* Calculate sn of the beginning of log block, which contains
the provided lsn value. */
const sn_t sn = lsn / OS_FILE_LOG_BLOCK_SIZE * LOG_BLOCK_DATA_SIZE;
/* Calculate offset for the provided lsn within the log block.
The offset includes LOG_BLOCK_HDR_SIZE bytes of block's header. */
const uint32_t diff = lsn % OS_FILE_LOG_BLOCK_SIZE;
if (diff < LOG_BLOCK_HDR_SIZE) {
/* The lsn points to some bytes inside the block's header.
Return sn for the beginning of the block. Note, that sn
values don't enumerate bytes of blocks' headers, so the
value of diff does not matter at all. */
return (sn);
}
if (diff > OS_FILE_LOG_BLOCK_SIZE - LOG_BLOCK_TRL_SIZE) {
/* The lsn points to some bytes inside the block's footer.
Return sn for the beginning of the next block. Note, that
sn values don't enumerate bytes of blocks' footer, so the
value of diff does not matter at all. */
return (sn + LOG_BLOCK_DATA_SIZE);
}
/* Add the offset but skip bytes of block's header. */
return (sn + diff - LOG_BLOCK_HDR_SIZE);
}
current_file_lsn同样是不断增加并且不回环的,它是redo log实际内容在逻辑上的增长,所以理论上是支持到无限大(UINT64_MAX),代表可以写入这么多redo log,但实际上的情况并非这样,redo log文件个数存在多个(图中有2个),这样无限增长的current_file_lsn需要知道什么时候换需要换下一个文件开始写,什么时候所有文件都已经写完需要回绕到第一个文件开始写。这里就需要图中第三层的转换,由于图中只有2个文件,每个文件4K,那么实际能写入的内容上限即是8K,刨除两个文件的FileHeader 4K,实际有效内容只剩4K,也就是说current_file_lsn每增长2K就要切换到下一个文件,每增长4K就要回绕到第一个文件。这里有一点需要注意,redo log这里其实对单个文件的感知并不强,在切换文件时它并不会显式的切换fd,具体切换是在fil_system里根据page_id做的,redo log模块这里认为下面的两个文件组成的实际上是一个逻辑上连续的8K空间,current_file_real_offset代表这8K内的偏移,初始值为2048(前面是第一个文件的FileHeader),初始时current_file_real_offset和current_file_lsn对应起来,即(2048 <—> 8192),之后的每次写入都同步更新这两个值,就可以完成逻辑上无限的current_file_lsn到实际有限的current_file_real_offset的映射转换。另外,current_file_end_offset代表当前在写的这个文件对应的结尾位置,如果current_file_real_offset超过这个位置就需要将其加上2K Header表示切换到下一个文件,files_real_capacity表示2个文件实际大小总和,这里即8K,如果current_file_real_offset超过这个值,代表当前2个文件都已经写完了,需要回绕到第一个文件重新写,这里就会将current_file_real_offset重新置为2048,完成回绕。
具体代码就不展开了,只要知道图中5个变量的含义,redo log文件组织,偏移量转换的代码就很容易看了
【注】:上面为了表述简单,实际current_file_lsn和current_file_real_offset以及current_file_end_offset并不是每次写入都更新,而是只在每次切换文件的时候更新,当文件未发生切换时,current_file_lsn和current_file_real_offset一一对应,代表该文件的起始lsn和real_offset,然后每次写入是通过将要写入的lsn与二者进行比较计算便可以算出要写入的real_offset完成写入,当要写入的offset大于current_file_end_offset则进行文件切换。
4. 并发写入
redo log是追加写,理论上当多个mtr同时追加redo log时,则需要加锁来确保写入顺序。8.0对这里做了无锁优化,来具体看一下。同样先上图大体感受下:
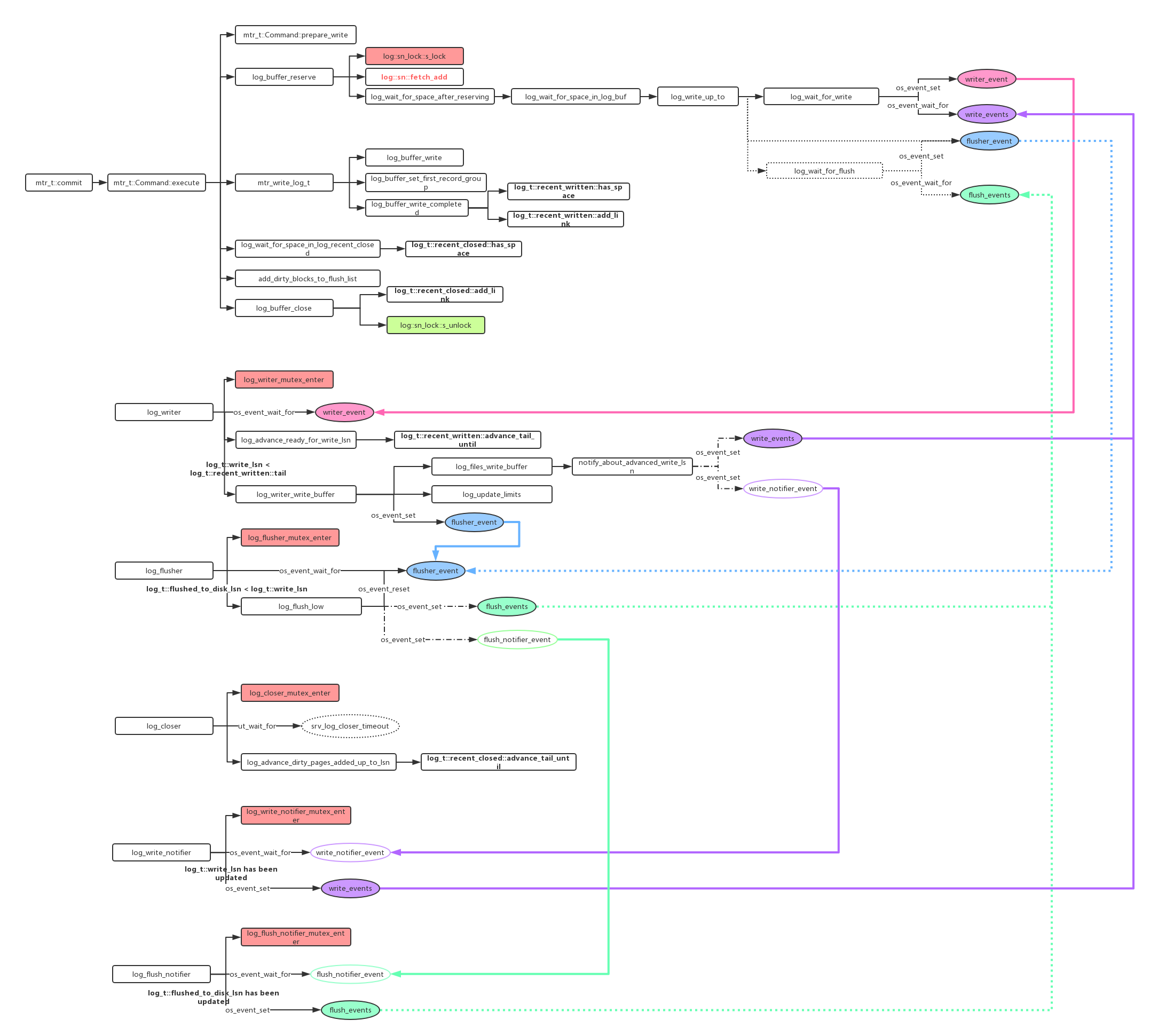
试想,如果每个mtr在写log之前可以拿到自己最终会写入的实际文件位置,预留好空间,那么就不需要一把大锁来严格保证日志的顺序写入了。InnoDB就是这么做的,首先在内存中有一块固定大小的log buffer,每个mtr上来先更新log_t::sn拿到自己log对应的sn区间,然后通过sn->lsn->log buffer position的转换,将自己的log内容拷贝到log buffer,由于多个mtr并发写入log buffer的不同位置,所以可能存在大lsn的mtr已经写完但小lsn的mtr还未写,即log buffer的空洞,所以就需要一个单独的线程log_writer,它负责不断扫描log buffer,发现从上次写入位置之后又有新的连续内容写入,就会将这段连续内容写入page cache,可以看到log_writer就是不断检测并刷log buffer到page cache,它是真正往文件里写入的线程。
用户线程并发写log buffer,log_writer线程扫描新的连续内容后写入page cache,二者配合是通过Link_buf来实现的,Link_buf也不难,它是一个大小固定、元素类型为std::atomic
下面举个例子,假设数组大小为10,初始化为:
0 0 0 0 0 0 0 0 0 0
现在有三个用户线程并发写log,通过上面说的,每个线程fetch_add log_t::sn(加上自身长度),拿到自己对应的lsn区间,假设
mtr 1: [0 , 2]
mtr 2: [3 , 7]
mtr 3: [8, 9]
此时,mtr 2先写完log buffer,通过计算它更新了Link_buf:
0 0 0 5 0 0 0 0 0 0
在位置3写入对应log长度(这里是5),此时log_writer从起始位置扫描,发现位置0的值为0,代表还没有写入(即使位置3已经有了内容,但由于不连续,所以无法继续),之后mtr 3也写完了 log buffer,同样更新Link_buf:
0 0 0 5 0 0 0 0 2 0
在位置8写入对应log长度(这里是2),同样log_writer检测到空洞,不做任何操作,直到mtr 1也写完log buffer并更新Link_buf:
3 0 0 5 0 0 0 0 2 0
在位置0写入对应log长度(这里是3),然后log_writer从起始位置扫描到非0,代表有数据写入,然后根据该位置的长度继续往后跳,调到位置3,还是非0,继续跳到8,非0,继续跳到9,为0,停止,代表从log buffer中上次写入位置之后扫描到3个新的连续log,没有空洞,所以log_writer线程就将这连续log写入到page cache中,并更新log_t::write_lsn(代表之前的lsn都已经写入到page cache)及Link_buf的下一次扫描位置m_tail。
这样就完成了redo log的无锁写入,从上图可以看到用户线程执行
mtr_t::commit() -> mtr_t::Command::execute()->
log_buffer_writer_completed()->log_t::recent_written::add_link()
就是在对应的Link_buf recent_written中标记对应lsn已经写入log buffer,然后log_writer线程通过timeout或者其他用户线程唤醒后,执行
log_advance_ready_for_write_lsn()-> log_t::recent_written::advance_tail_until()
来扫描下一段新的连续内容,如果发现有,就就调用
log_writer_write_buffer()
写入到page cache。
上面用户线程标记完recent_written之后,会将mtr中的脏页用该mtr之前从log_t::sn拿到的序列转换为lsn对应的[start_lsn, end_lsn]作为参数加入到flush_list里,lsn对应脏页的产生顺序。这里具体以后专门总结buffer pool的时候再说。然后调用
log_buffer_close()->log_t::recent_closed::add_link()
在另一个Link_buf recent_closed中标记对应lsn,代表这个区间的脏页已经挂到flush_list上了,这里为什么还要使用Link_buf呢,因为这里挂flush_list的顺序也不是按照lsn严格有序了,它允许在recent_closed大小的范围内存在lsn空洞(即大lsn的脏页已经挂入flush_list而小lsn还未挂入),这里也有允许小范围的并发挂flush_list了,log_closer会不断检查,当发现连续lsn被标记后,先前滚动,更新recent_closed.m_tail,代表此之前的lsn脏页都已经挂入flush_list,这个值在取checkpoint的时候会用到,后面会具体说。
总之,两个Link_buf, recent_written和recent_closed的存在,使得用户线程在写log buffer和挂flush list的时候可以并发起来。
redo log的刷盘也是异步来搞的,log_flusher线程检测到log_t::flushed_to_disk_lsn < log_t::write_lsn,代表有新的数据写入到page cache但还没有刷盘,会调用log_flush_low来完成(write_lsn - flushed_to_disk_lsn)这部分日志的刷盘。
另外,从上面的图和描述中可以看到参与redo log这块的线程真的不少:
N个用户线程
1个log_writer
1个log_closer
1个log_flusher
1个log_write_notifier
1个log_flush_notifier
涉及这些线程间同步的条件变量也很多:
writer_event
write_events[]
write_notifier_event
flusher_event
flush_events[]
flush_notifier_event
下面结合上图说下他们之间的关系
- 用户线程,并发写入log buffer,如果写之前发现log buffer剩余空间不足,则唤醒等在writer_event上的log_writer线程来将log buffer数据写入page cache释放log buffer空间,在此期间,用户线程会等待在write_events[]上,等待log_writer线程写完page cache后唤醒,用户线程被唤醒后,代表当前log buffer有空间写入mtr对应的redo log,将其拷贝到log buffer对应位置,然后在recent_written上更新对应区间标记,接着将对应脏页挂到flush list上,并且在recent_closed上更新对应区间标记
- log_writer,在writer_event上等待用户线程唤醒或者timeout,唤醒后扫描recent_written,检测从write_lsn后,log buffer中是否有新的连续log,有的话就将他们一并写入page cache,然后唤醒此时可能等待在write_events[]上的用户线程或者等待在write_notifier_event上的log_write_notifier线程,接着唤醒等待在flusher_event上的log_flusher线程
-
log_flusher,在flusher_event上等待log_writer线程或者其他用户线程(调用log_write_up_to true)唤醒,比较上次刷盘的flushed_to_disk_lsn和当前写入page cache的write_lsn,如果小于后者,就将增量刷盘,然后唤醒可能等待在flush_events[]上的用户线程(调用log_write_up_to true)或者等待在flush_notifier_event上的log_flush_notifier
- log_closer,不等待任何条件变量,每隔一段时间,会扫描recent_closed,先前推进,recent_closed.m_tail代表之前的lsn已经都挂在flush_list上了,用来取checkpoint时用。
还有log_write_notifier和log_flush_notifier线程,注意到上面有两个条件变量是数组:write_events[],flush_events[],他们默认有2048个slot,这么做是为什么呢?
根据上面描述可以看到,等待在这两组条件变量上的线程只有用户线程(调用log_write_up_to),每个用户线程其实只关心自己需要的lsn之前的log是否被写入,是否被刷盘,如果这里用的是一个全局条件变量,很多时候不相关lsn的用户线程会被无效唤醒,为了降低无效唤醒,InnoDB这里做了细分,lsn会被映射到对应的slot上,那么就只需要wait在该slot就可以了。这样log_writer和log_flusher在完成写page cache或者刷盘后会判断:如果本次写入的lsn区间落在同一个slot上,那么就唤醒该slot上等待的用户线程,如果跨越多个slot,则唤醒对应的log_write_notifier和log_flush_notifier线程,让他们去扫描并唤醒lsn区间覆盖的所有slot上的用户线程,这里之所以将多slot的唤醒交给专门的notifier来异步做,应该是想减小当lsn跨度过大时,log_writer和log_flusher在此处的耗时
5. Checkpoint
InnoDB在确定checkpoint时,用到将以下几个lsn:
- recent_closed.m_tail,它代表在此之前的lsn对应的脏页都已经挂在了flush_list上
- flush_list上取oldest_modification最小的lsn,它代表之前的lsn对应的脏页都已经刷到盘上
- flushed_to_disk_lsn,它代表此之前lsn对应的redo log都已经刷到盘上
先比较1,2,首先如果当前flush_list比较长,大于recent_closed的capacity(2M),那么肯定2<1,如果当前flush_list刷盘比较快,在recent_closed.m_tail对应的lsn之前可能都已经刷到盘上了,那么之前上面说的,由于flush_list允许有2M的空洞,此时从flush_list上取的oldest_modification的lsn需要减去recent_closed的capacity(2M),减完之后在比较1和2,取二者最小值
然后将其和flushed_to_disk_lsn比较去最小值,这个值如果大于当前的checkpoint_lsn,则该值可以作为新的checkpoint_lsn。总之checkpoint就是取数据和对应redo log都已经落盘的最小lsn。
这里有个疑问,由于recent_closed最多只能有2M空洞,也就是说flush_list的空洞始终增量限制在2M之内,任何时候从flush_list上取得oldest_modification减去2M后,这个值已经可以确保:
- 在此之前的lsn对应的脏页都已经挂在flush_list上了
- 该值已经是当前还没有落盘的数据页最小oldest_modification的lsn了
直接用它感觉就可以了,没必要和recent_closed.m_tail作比较了??
6. 总结
InnoDB redo log这里整体上分为两大块:
-
log文件管理,lsn对应文件位置的转换;
-
并发写入控制,这里涉及到多个线程的同步。
整体来看这两块设计的都很巧妙:
-
lsn管理和文件管理分层,在redo log模块来看只有逻辑无限的current_file_lsn和逻辑上连续但空间有限的current_file_real_offset,定位时只需要根据二者计算便可算出对应的逻辑offset,然后交给文件管理模块去定位到具体文件具体偏移读取,这样简化了redo log模块维护这些文件偏移的代价
-
使用Link_buf来进行并发写入,相比5.6一把大锁的实现美不少