I presented this proposal at Oracle’s MySQL Contributor Summit on May 26. It focuses on optimizing the InnoDB B+Tree insert path, especially structure modification operations (SMOs), by introducing a B-link-style split protocol.
This blog post summarizes the main ideas behind the proposal, including the current bottlenecks, the high-level design, several low-level InnoDB integration challenges, and benchmark results from my PoC based on MySQL 9.7.0.
1. Bottlenecks in InnoDB B+Tree Inserts
The current InnoDB B+Tree index insert path has three major performance bottlenecks:
-
Repeated B+Tree descent
A pessimistic insert may go through the B+Tree descent path multiple times:
- Optimistic insert attempt:
btr_cur_search_to_nth_level(BTR_MODIFY_LEAF)->btr_cur_optimistic_insert - Pessimistic insert with page split:
btr_cur_search_to_nth_level(BTR_MODIFY_TREE)->btr_cur_optimistic_insert->btr_cur_pessimistic_insert
Each path requires
btr_cur_search_to_nth_level()to descend the B+Tree again. - Optimistic insert attempt:
-
BTR_MODIFY_TREEserializes SMO throughSX(dict_index_t::lock)The pessimistic insert path acquires
SX(dict_index_t::lock), which means all SMO operations are effectively serialized. -
The pessimistic
BTR_MODIFY_TREEphase holds X latches on the affected subtreeMySQL introduced
SX(dict_index_t::lock)in 8.0. Although it is compatible with theS(dict_index_t::lock)held by readers and optimistic writers, and therefore improves concurrency between SMO and other operations to some extent, the subtree involved in the pessimisticBTR_MODIFY_TREEphase is still held with X latches until the SMO completes.During this period, no other read or write operation can enter that subtree. This becomes even worse when cascading SMO reaches higher levels of the tree.
To optimize these issues, in principle we need:
- A new B+Tree descent, ascent, and page-latching protocol, so that after an optimistic insert fails, we do not need to release the current leaf page latch and restart from the root. Instead, we should be able to start the pessimistic insert process in place.
- Pessimistic insert should no longer hold
SX(dict_index_t::lock). It should only needS(dict_index_t::lock), so that SMO operations can run in parallel. - SMO should not pre-lock the whole affected subtree. The latch granularity should be reduced. The split should proceed bottom-up, one level at a time: latch, split, and release. This allows the subtree being modified by SMO to remain readable and writable as much as possible.
Combining these three points, we can borrow ideas from B-link Trees and perform a more complete redesign.
2. High-Level Design
1. Introduce a new B-link-style descent path: blink_search_to_nth_level
The new search path works as follows:
- Acquire
S(dict_index_t::lock). - Starting from the root page, acquire an S latch on the current page, get the child page number, release the current page latch, then descend and acquire an S latch on the child page. Repeat this until reaching the level immediately above the target level. During descent, record the page numbers of the internal pages in
path[]. - After obtaining the target page number at the target level, acquire either an S latch or an X latch on the target page depending on whether the operation is a read or write.
There is no longer a fundamental distinction between BTR_MODIFY_LEAF and BTR_MODIFY_TREE in the descent protocol. The main difference is only the target level.
After descent completes, the operation holds the latch on the target page, and also has the page numbers of all internal pages on the path. These can later be used to optimistically locate the parent page if needed.
2. Latching-order protocol
- During descent, latch coupling is not required. We latch one level at a time: parent -> child page number -> release parent -> latch child.
- During ascent, latch coupling is also not required.
- When moving right on the same level through the B-link high key, latch coupling is required. The protocol is current -> right: acquire the right page latch while still holding the current page latch, then release the current page latch.
- Pages are split only to the right, which fits the B-link Tree right-move logic.
3. Full insert flow
-
Use
blink_search_to_nth_level()to descend to the target leaf pageL, acquire an X latch onL, and return the internal-page pathpath[]. -
Try an optimistic insert. If it succeeds, the insert is complete and returns.
-
If the optimistic insert fails, continue holding the X latch on
L, acquire an X latch onL’s right siblingR, allocate a new pageN, move part ofL’s records toN, and insertNbetweenLandR.At the same time, set the
INCOMPLETE_SPLITflag onL, and setL’s high key.The semantics of
INCOMPLETE_SPLITare:- concurrent readers and optimistic writers can still enter
L; - they can use the high key to decide whether they need to move right to continue the operation;
- concurrent pessimistic writers are blocked by this flag and return retry, waiting for the previous unfinished cascade to make progress.
After the split is complete, obtain the
node_ptrforN, then release all latches onL,N, andR. - concurrent readers and optimistic writers can still enter
-
Use
path[]to optimistically acquire an X latch on the parent pageP. IfPhas changed, descend again to locate the correctPand acquire its X latch.If
Phas enough space for an optimistic insert, insert thenode_ptr, then reacquire the latch onL, clearL’sINCOMPLETE_SPLITflag, and return success. -
If
Pcannot accept thenode_ptr, perform step 3 atP’s level and splitP. Then reacquire the X latch onLand clearL’sINCOMPLETE_SPLITflag. -
Perform step 4 at
P’s level and insert thenode_ptrofP’s new right page intoP’s parent. -
Continue this process upward until the cascading split completes.
With this design, we can effectively address the three bottlenecks described above.
4. Benchmark results
I implemented a PoC based on MySQL 9.7.0 and ran several benchmarks to evaluate the effect of the new protocol.
1. Split-heavy insert workload
The first benchmark is a deliberately constructed split-heavy insert workload.
Before the measured phase, I preloaded 2.5 million rows into the table. Each row is about 2.5 KB, so after the preload phase, most leaf pages were already close to the split threshold.
Then, during the measured phase, the benchmark inserted 400,000 additional rows. These rows were evenly distributed across the table, triggering a large number of page splits.
| Version | TPS | Avg latency | P95 latency |
|---|---|---|---|
| MySQL 9.7.0 | 5,666.22 | 5.65 ms | 17.01 ms |
| Optimized version | 91,523.92 | 0.35 ms | 0.40 ms |
The optimized version achieved about 16.2x higher TPS, 16.1x lower average latency, and 42.5x lower P95 latency.
I also collected perf samples on the optimized version. The hotspot shifted from index-lock contention to redo log commit wait. In particular, log_wait_for_write accounts for about 40% of the samples. This indicates that SMO concurrency inside the B-link-style protocol is no longer the bottleneck.
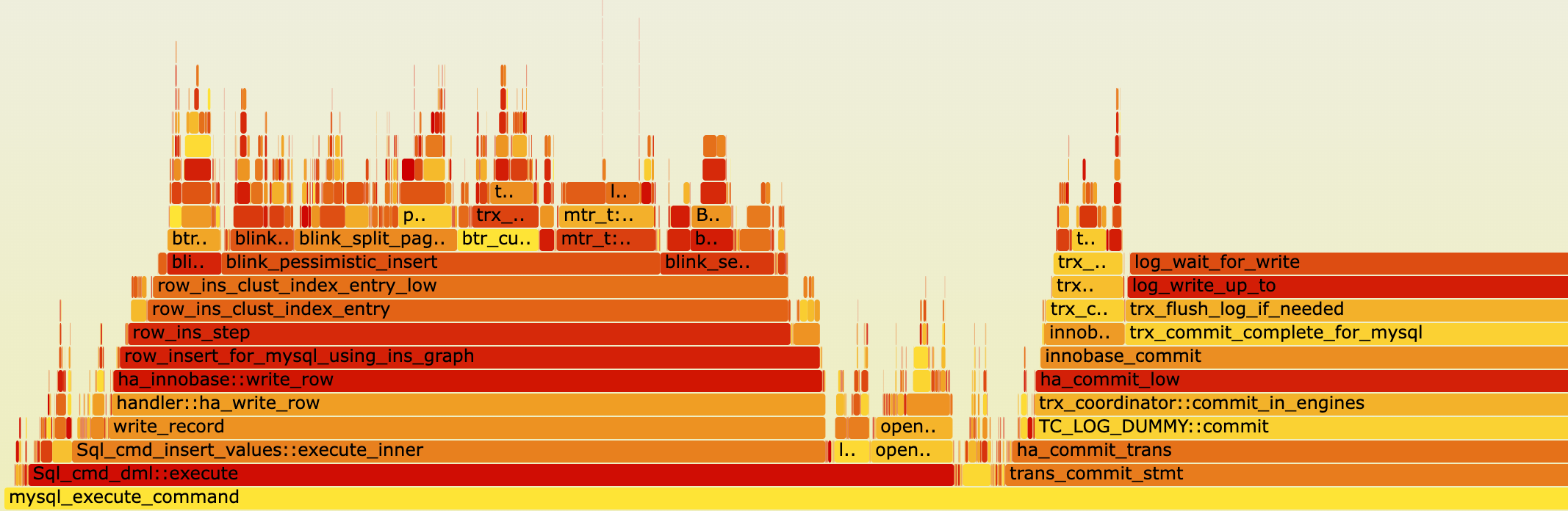
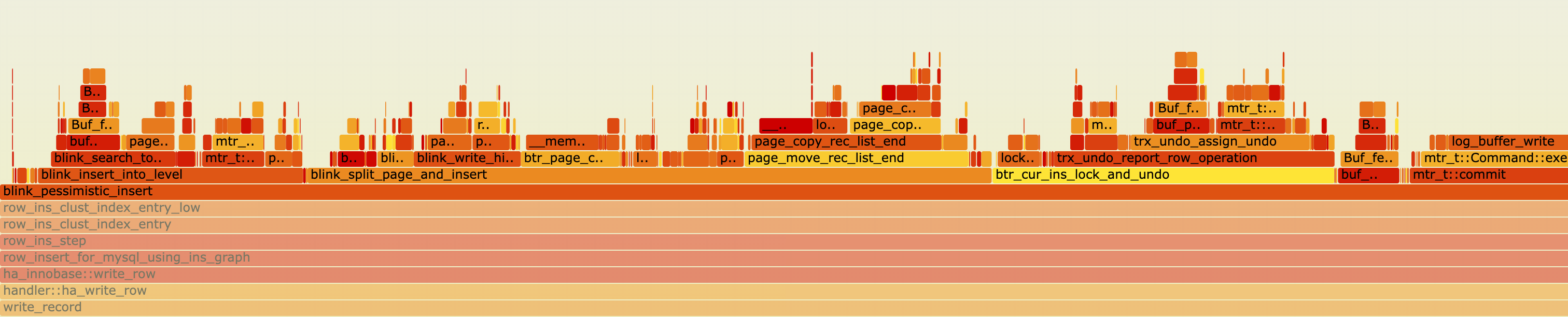
2. sysbench oltp_insert
I also tested the standard sysbench oltp_insert workload.
This is not a split-heavy workload because the rows are small, but the optimized version still shows clear improvements.
With auto_inc = ON , inserts concentrate on the rightmost part of the B+Tree. This creates an insert hotspot. The optimized version benefits mainly from the reduced latch scope around the hotspot.
| Version | TPS | P95 latency |
|---|---|---|
| MySQL 9.7.0 | 80,223 | 1.64 ms |
| Optimized version | 104,776 | 0.90 ms |
The optimized version achieved about 30.6% higher TPS and 45.1% lower P95 latency.
With auto_inc = OFF , inserts are more evenly distributed across the B+Tree. In this case, the optimized version benefits more from parallel SMOs.
| Version | TPS | P95 latency |
|---|---|---|
| MySQL 9.7.0 | 194,912 | 0.19 ms |
| Optimized version | 245,161 | 0.19 ms |
The optimized version achieved about 25.8% higher TPS, with no P95 latency regression.
Overall, these benchmarks show that the B-link-style protocol improves not only artificially split-heavy workloads, but also standard insert workloads.
The improvement is significant, so I believe this proposal is worth further investigation.
3. InnoDB Low-Level Design
The main difficulty of this proposal is that it requires a major redesign of InnoDB core modules. There are also historical design constraints in InnoDB that conflict with this new design.
1. Add high keys to pages
The high key is an important part of B-link Trees. It allows concurrent threads to repair their access path when they encounter a page being split. Therefore, it must be introduced.
In InnoDB, for compatibility reasons, I found that the high byte of the PAGE_DIRECTION field in PAGE_HEADER is effectively unused. PAGE_DIRECTION is a 2-byte field, but InnoDB only uses the low byte to store the last insert direction. The high byte remains 0 before and after upgrade.
Therefore, in my PoC, I use it as a B-link Tree flag byte, reusing the existing page-header space without changing the file format.
The flags are:
- bit 0:
PAGE_IS_BLINKIndicates whether the page is a B-link page or a normal B+Tree page. It is set when the page is first touched by SMO and is never cleared. - bit 1:
PAGE_INCOMPLETE_SPLITIndicates that the page’s cascade has not yet been propagated to the parent. This is an intermediate state during the B-link split process.
If a page is a B-link page, the high key always exists as the record immediately before supremum.
On internal pages, the high key has the same shape as a normal node_ptr. The difference is that the high key’s child page number is FIL_NULL, meaning it points to +infinity.
This requires adding high-key checks and skip logic in code paths that fetch the next record, so that the high key is treated as an internal reserved record.
2. Split SMO into multiple mtrs
In the current InnoDB implementation, when BTR_MODIFY_TREE descends the B+Tree, the mtr already latches all pages that may need to split along the path. These latches are held until the whole pessimistic insert finishes and the mtr commits.
During this time, the whole affected area cannot be accessed concurrently. Also, dirty-page unlatching in the current mtr model happens together with mtr commit.
For the B-link-style design, we need to split this large mtr into multiple smaller mtrs.
mtr 1
Acquire the index S lock, descend the B+Tree to the target leaf page L, and hold L’s X latch.
If an optimistic insert succeeds, commit the mtr and the insert is complete.
Otherwise, acquire an X latch on L’s right sibling R, allocate a new page, split L, set L’s INCOMPLETE_SPLIT flag and high key, and then start mtr 2.
mtr 2
Transfer the index S lock held by mtr 1 to mtr 2 through a new mtr interface transfer_to, ensuring that the index S lock is held during the entire insert operation.
Then mtr 1 can commit, and the split becomes visible.
mtr 2 continues to hold the index S lock and tries to insert the new page’s node_ptr into the corresponding parent page P.
The design is to locate the parent using the path[] collected during the mtr 1 descent. The cached information includes the parent page number and LSN. After acquiring an X latch on the parent page, we compare the LSN to determine whether the cached parent is still valid. This can avoid descending the tree again. Even when the cache is invalid, the same-level right-move logic can be used to repair the search path.
However, in my current PoC, each cascade step still uses btr_cur_search_to_nth_level() to descend again and locate P.
Then we check whether P can optimistically accept the node_ptr:
-
If it can, insert the
node_ptrdirectly. Then use the cached page number ofLto acquire an X latch onL.According to the proposed protocol,
LhasINCOMPLETE_SPLITset. It can accept reads and optimistic writes, but blocks pessimistic writes. Therefore,Lcan be safely located by page number.Then clear
L’sINCOMPLETE_SPLITflag, commit mtr 2, and the insert succeeds. -
If
Pcannot accept thenode_ptr, acquire an X latch onP’s right sibling, splitP, and similarly setP’sINCOMPLETE_SPLITflag and high key.Then obtain the
node_ptrof the new page created by splittingP.After that, acquire the X latch on
LusingL’s page number and clearL’sINCOMPLETE_SPLITflag.Start mtr 3, transfer the index S lock to mtr 3, and then commit mtr 2. At this point,
P’s split also becomes visible.
mtr 3 and above
mtr 3 now holds the index S lock and is ready to continue inserting the node_ptr into the upper level. This is the same state as mtr 2. The process repeats until the cascading split completes.
This is the mtr-splitting model.
In principle, each level modification corresponds to one mtr. The index S lock is transferred between mtrs to ensure it is held throughout the whole operation.
For cascading splits, the mtr that splits the parent and the mtr that clears the child’s INCOMPLETE_SPLIT flag must be atomic with respect to each other. Therefore, they need to be in the same mtr.
However, before clearing INCOMPLETE_SPLIT, we do not need to keep holding the child page latch. We only need to reacquire the child page by page number at the end and then clear the flag.
3. Page allocation and the FSP locking problem
After changing SMO from holding index SX to holding index S, the bottleneck moves from the index SX lock to the locks inside FSP page allocation.
Specifically, when allocating a new page from FSP, InnoDB needs to hold SX on the root page and then hold SX on space->lock.
This is the biggest historical constraint I encountered in this optimization.
The current InnoDB BTR_MODIFY_TREE path holds the root page SX or X latch while descending the tree, which makes this latch order valid in the existing design.
However, in the new protocol, allocating a page requires holding the root page latch, which breaks the B+Tree latch-order protocol and may introduce deadlocks.
More seriously, even if we adjust the order to avoid deadlocks, the root SX latch would still block concurrent SMO. Also, the latch is released only when the mtr holding it commits. Even after splitting the mtr, the resulting mtr is still too large for such a global latch and becomes a performance bottleneck.
This is a difficult issue, and I do not currently have a perfect solution. The main problems are:
-
If we remove the root page dependency from the FSP new-page allocation logic, this may involve data-file format changes and introduce compatibility issues.
-
If we use a separate
alloc_mtrto minimize the new-page allocation phase, there are two problems.First, in the new insert flow, we allocate a new page while holding a data page latch. This still creates a data-page X -> root-page X order, which may cause deadlocks.
To avoid that, we would need to release the held data page latch before allocation, and then reacquire it after
alloc_mtrcommits. But this workaround exists only to accommodate historical constraints, and it is not very clean from an engineering perspective. It may also hurt performance.Second, if
alloc_mtrcommits early and the later operation fails, the newly allocated page cannot be returned to FSP easily. -
Using an up-locking order is not a clean solution. In this protocol, clearing the child page’s
INCOMPLETE_SPLITflag and inserting the new page’snode_ptrinto the parent must be atomic with respect to crash recovery and concurrent access. This means the mtr that installs the parentnode_ptrstill needs to reacquire and modify the child page at the end.In other words, even if we try to use an up-locking order to propagate the split to the parent, the final step still requires a parent-to-child latch order. This brings us back to a down-locking pattern.
Also, even if we could make this ordering work, the root page’s SX latch would still be held longer than necessary, which would again limit parallel SMOs.
Since this is not the main topic of the proposal, my current PoC uses a temporary solution: a B-link allocator thread.
The allocator thread pre-allocates pages from FSP into a pool. The pool stores page numbers only.
The allocator maintains separate watermarks for FSP_LEAF and FSP_NON_LEAF, so that the high consumption rate of leaf pages does not starve the internal-page segment.
During B-link split, all new pages are taken directly from this pool. The allocator monitors the pool watermarks and keeps them at a reasonable level, so that there are normally enough pre-allocated page numbers available.
When a split needs a new page, it simply takes one from the pool. If the pool is empty, it signals the allocator thread and returns DB_BLINK_RETRY. Then the row layer retries the whole insert path. This avoids blocking the latch path on an empty allocation pool.
This decouples the root SX latch required by page allocation from the B+Tree insert path.
Of course, this is only the PoC solution and still needs further refinement.
For example, we need to consider how to reclaim pre-allocated pages after a server crash. One possible solution is to introduce a new redo record to record the pre-allocation state, and then reclaim unconsumed pre-allocated pages during server restart. This should be solvable from an engineering perspective.
Another reason why I think an allocator thread is useful is that, for B-link Trees, if merge is supported in the future, pages created or removed by merge cannot be immediately freed back to FSP.
B-link Tree correctness requires that concurrent operations may still see intermediate SMO states. If a page is freed too early, another operation may follow a stale right-link and reach a freed page, causing correctness problems.
A page can be safely freed only after all mtrs that were active at the moment when the page was removed from the tree have completed. This is also implementable in engineering terms, similar to an MVCC visibility check, but much lighter than full MVCC.
This asynchronous safe-free work can also be handled by the allocator thread after merge support is added.
Merge is also an important part of the design, but I will not expand on it in this proposal.
4. Crash Recovery
When a writer crashes in the middle of a cascading split, a lower-level page may have its INCOMPLETE_SPLIT flag durably written to disk, while the corresponding parent page may not yet contain the node_ptr pointing to the new page.
In my current PoC, during restart, B-link recovery runs as the first step of srv_start_threads_after_ddl_recovery.
It scans the buffer pool in a single thread. For each page with both PAGE_IS_BLINK and PAGE_INCOMPLETE_SPLIT set, it separately acquires X(index). Since this is during recovery and runs single-threaded, there is no concurrent contention.
Then it reuses the runtime split/root-raise primitives to complete the interrupted cascade.
There is an important invariant that simplifies recovery:
The parent node_ptr installation and the clearing of the child page’s INCOMPLETE_SPLIT flag commit in the same mtr.
Therefore, if a flagged page survives crash recovery, it means the corresponding parent must be missing the node_ptr. We do not need an idempotency check for whether the parent already contains the node_ptr.
The current implementation only scans the buffer pool.
There is an edge case where a flagged page has been flushed to disk, the checkpoint has advanced, and recovery misses it. In that case, the impact is mainly performance-related rather than correctness-related, because descent itself does not consume INCOMPLETE_SPLIT.
The high key and right-link can still route the operation to the correct target page.
A complete solution can be implemented in multiple ways, such as runtime repair, or maintaining page numbers of dirty pages that still have PAGE_INCOMPLETE_SPLIT set at flush time.
5. Summary and Next Steps
This is a large proposal. It involves major changes to several core InnoDB modules, so the implementation is definitely challenging.
Also, this proposal only covers the split path. Merge support will be needed in the future. I plan to describe the merge design in a separate follow-up proposal, or as an extension of this one.
That said, I think the full patch can be delivered incrementally.
For V1, we can focus only on parallel page splits and fall back to the existing serialized behavior for page merges. For example, we can introduce a new SMO lock to make splits and merges mutually exclusive:
Split: S(index->lock) + S(index->smo_lock)
Merge: S(index->lock) + X(index->smo_lock)
In this way, multiple splits can run in parallel, while merges still take exclusive access through index->smo_lock and follow the existing InnoDB behavior.
The PoC shows that this direction is feasible and has significant performance potential, so I believe it is definitely worth exploring further.