最近在给MySQL支持TTL(Time To Live),刚实现一版,有一些有意思的设计和实现问题值得记录一下。
1. 什么是TTL
TTL(Time to Live),简单来说就是给表中的记录设置过期时间,记录在其过期时间之前对外可见,过期时间之后消失,类似隐式删除。这个特性的好处就是简化了用户的数据管理复杂度,有了TTL,不需要显式通过DELETE来从外部删除不需要的记录,数据库会在内部自行处理。TTL这个概念已经很旧了,也几乎成了NoSQL的必备特性(Redis),但在关系型事务数据库领域,虽然也有不少产品有TTL,但除了在产品手册页面有简单介绍之外并无太多内部细节。我觉得实现MySQL的TTL和Redis的TTL还是有所不同,有一些问题值得讨论,比如“#5 如何在事务中给TTL一个名分“。
下面就介绍下我是如何在MySQL上设计实现的TTL。
2. 如何使用TTL
使用TTL,前提是表中一定要有一列和时间相关的列,作为过期时间的指示器。
那么问题来了,这一列是要求必须作为用户原生表定义的一部分显式存在还是可以类似InnoDB的DATA_TRX_ID作为隐式列,对用户不可见?
我倾向前者,因为相比DB,用户更了解自己的数据,要求用户显式的指定某一时间列作为TTL列,有更大的主动权,对于某一条记录:
- 设置TTL列的值来指定过期时间
- 修改TTL列的值来改变过期时间
- 查询TTL列的值来查询过期时间
这比DB通过隐式列来黑盒处理更为方便。
有了这个前提,那么如何给表设置TTL呢? – 通过DDL语句:
CREATE TABLE tbl (col_a INT, col_b DATETIME, col_c INT, PRIMARY KEY(col_a)) COMMENT="TTL=10@col_b";
通过在表comment中添加关键字“TTL=”来给表设置TTL信息。
“TTL=10@col_b”
10是存活时间(秒), col_b是TTL列(DATETIME类型),这样DB在拿到某一条记录之后,给其col_b列的时间值加10秒就得到了这一列的过期时间,然后和当前时间比较来判断可见性即可。这样的设计有如下好处:
- 不必引入新的DDL语句来设置TTL,使用简单且无兼容性问题
- 灵活
- 如果用户给TTL列存的是插入时间,那么过期时间就是“插入时间+存活时间”,类似表级TTL效果
- 如果用户通过TTL=0@col_b, 设置存活时间为0且给TTL列直接存指定过期时间,那么就类似行级TTL的效果
3. 如何存放表的TTL信息
“TTL=10@col_b”,对于这张表的TTL,我们需要额外记录2条相关信息:10(存活时间)和col_b(TTL列)。上面的设计理所当然的是存在表的meta信息里最为方便。这里我的想法是MySQL server层无需感知表的TTL,全部交给存储引擎层来处理,所以dd::Properties_impl不二人选。建表的时候存储引擎层通过拿到server层传下来的comment信息检查是否设置TTL,如有:
- 提取TTL信息,设置到存储引擎自己的内部字典数据里(如InnoDB的dict_table_t中)
- 至于持久化,给InnoDB的dd_table_key_strings加上TTL的两个信息,然后就能持久化到dd::Table的se_private_data里了
注:对于NDB引擎,因为其分布式架构,它并没有使用MySQL持久化到InnoDB里的数据字典,然后在它的Data nodes搞了一套自己的字典,以便其上运行的多个MySQL可以共享这些字典信息。但改法也类似,在它自己的字典里加入这俩字段即可,之后每次建表之后,data nodes上的内部模块包括DBTC,DBLQH,DBACC,DBTUP都可以通过DDL流程拿到该表的TTL信息。
4. 哪里检查并过滤过期的记录
- 从BTree中读取时不做任何检查。btr_cur_search_to_nth_level()是在BTree中定位某个记录的函数,最终它通过btr_cur_t来返回最匹配的记录,包含这条记录在Page的位置,匹配程度up_match,low_match等等。
- 其调用者来做检查和过滤,具体的:
- 插入:row_ins_clust_index_entry_low()中做检查。为什么插入还要进行TTL检查,因为TTL过期的记录并不是立刻从BTree中删除,只是通过过滤对外不可见而已,所以这里可能还是会拿到相同主键的记录。原本这里的逻辑如果不是allow_duplicates,就回返回DB_DUPLICATE_KEY报错,但当有了TTL,可能这条底层重复的记录已经过期了,所以这里需要特殊判断处理,如果过期就走update流程,也就是row_ins_clust_index_entry_by_modify()。
- 更新和删除:这个是MySQL Server层通过存储引擎的实现的各种Iterator来定位拿到数据,然后执行更新或者删除。所以有两处需要进行处理
- row_search_mvcc(),这是第一次读取要更新和删除的地方。从BTree中拿到记录之后,进行TTL过期判断
- row_upd(),这里是实际进行更新和删除的地方。正常情况下会通过pcur的restore_position()拿到之前读到的记录,一般不需要进行TTL判断,如果有必要判断,一定要确保和之前row_search_mvcc的可见性结果一致。
注:对于NDB引擎,修改的地方也类似,主要是DBTUP模块,具体的handleReadReq(),handleInsertReq(),handleUpdateReq(),handleDeleteReq()
5. 如何在事务中给TTL一个名分
数据库中一切数据修改的操作都是在事务的框架下完成的。TTL这种自动过期似乎打破了一切。如果将TTL简单的定义为“一条记录到达过期时间后,立刻对外不可见”。这会导致MySQL出现很多未定义的行为。举个例子,“INSERT INTO … ON DUPLICATE KEY UPDATE …”这条插入语句的行为是:
- 首先尝试插入,如果成功,即返回
- 如果在Unique index中检测到已存在的重复记录,则将整个语句转换为update语句,执行语句定义的更新
注意这2步并不是在存储引擎中定义的,而是在MySQL Server里的write_record()中实现的:首先调用handler::ha_write_row()向存储引擎尝试插入,如果这里因为冲突失败,则通过handler::ha_index_read_idx_map()读出已经存在于储存引擎的冲突记录,然后经过构造更新后的新记录通过handler::ha_update_row()来向存储引擎更新。这里之所以可以在MySQL Server层实现是因为上述三步都是在记录锁的保护下完成的。第一次插入失败后已经有了记录写锁,从而保证后续两步一定成功。但这一切在有了TTL之后都会不可控,事务的隔离性被打破,因为TTL是随时过期的行为,如下图所示,假如过期发生在第一次尝试插入失败和从引擎读取冲突记录之间,那么引擎会向Server返回Not Found,这直接给原本的Server逻辑干懵逼了:“什么?!我加着锁,你告诉我记录找不到了?” 抱怨完引擎之后Server只好把错误返回给用户,用户也懵逼了:”什么?!我一条INSERT语句,你给我返回can’t find record?!“
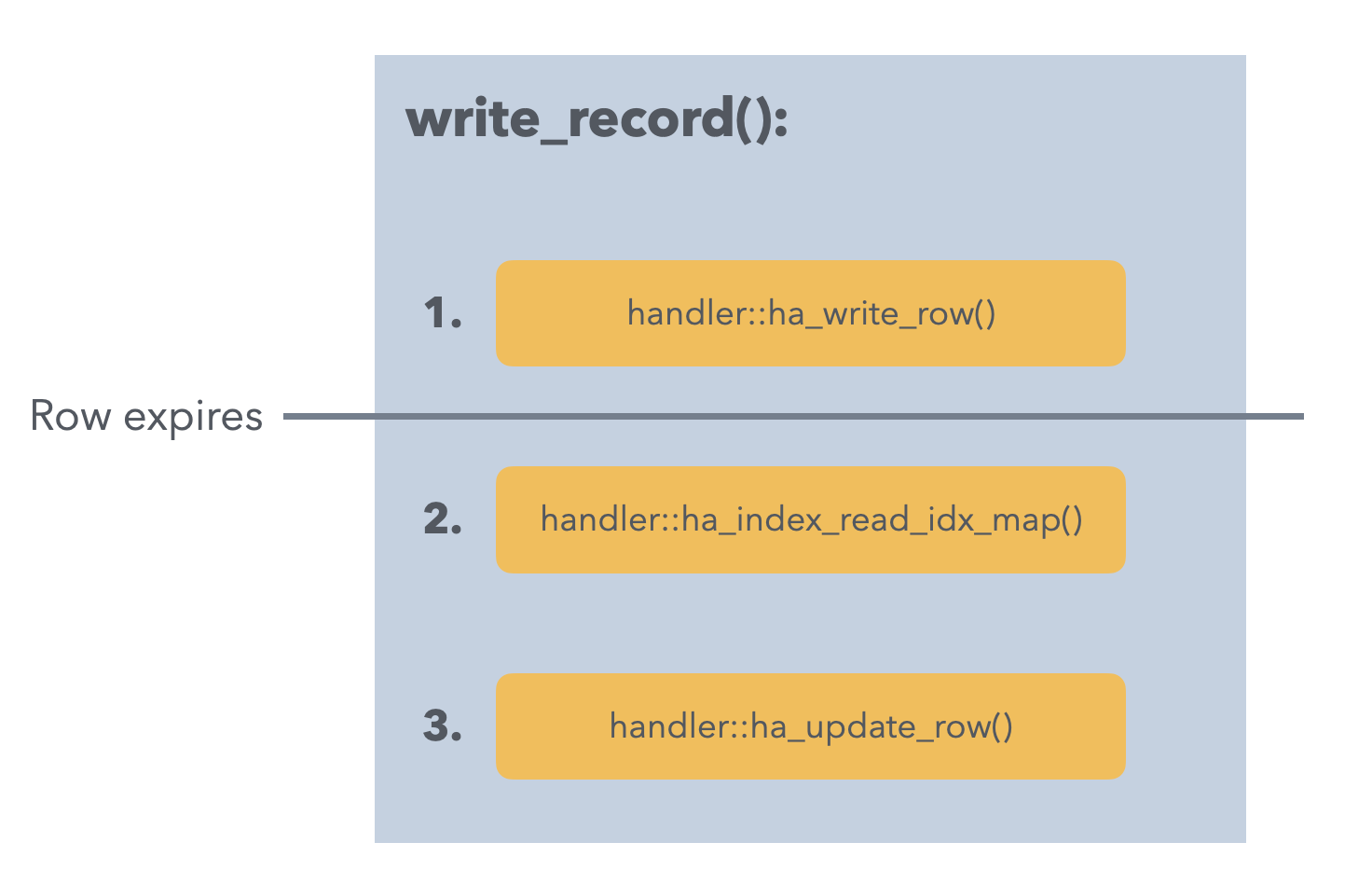
所以,这种简单粗暴的TTL定义在事务引擎下会引发很多问题。如何解决?我们需要将TTL的行为约束在事务的框架下。如果我们将TTL定义成如下:
TTL可以看成一条隐式写事务,行为如下:
- 加记录写锁
- 检查TTL列是否过期,如果未过期,提交事务
- 如果过期,删除记录,提交事务
注意这个事务并不是每条记录过期都会实际执行的显式事务,只是TTL自身对于其他并发事务的表象定义。有了这个定义,很多问题边有了合理的解法。回到上面的“INSERT INTO … ON DUPLICATE KEY UPDATE …”,过期发生在1,2步之间,但此时TTL遵循事务隔离性,在MySQL下,会尝试获取记录写锁,但此时用户的这条语句已经加上了记录写锁,那么我们这条过期事务就需要被序列化到用户事务之后才能执行。也就是有锁的保护,用户的在第2步一定可以读到冲突的记录,即使实际它已经过期。也就是记录锁的优先级大于TTL过期判断。
另外,如果我们严格的遵循这个TTL的定义,会引入一个有意思的行为,就是读锁等待读锁,假设有2个用户事务,顺序如下:
- 事务A:加记录X的读锁
- 事务B:加记录X的读锁
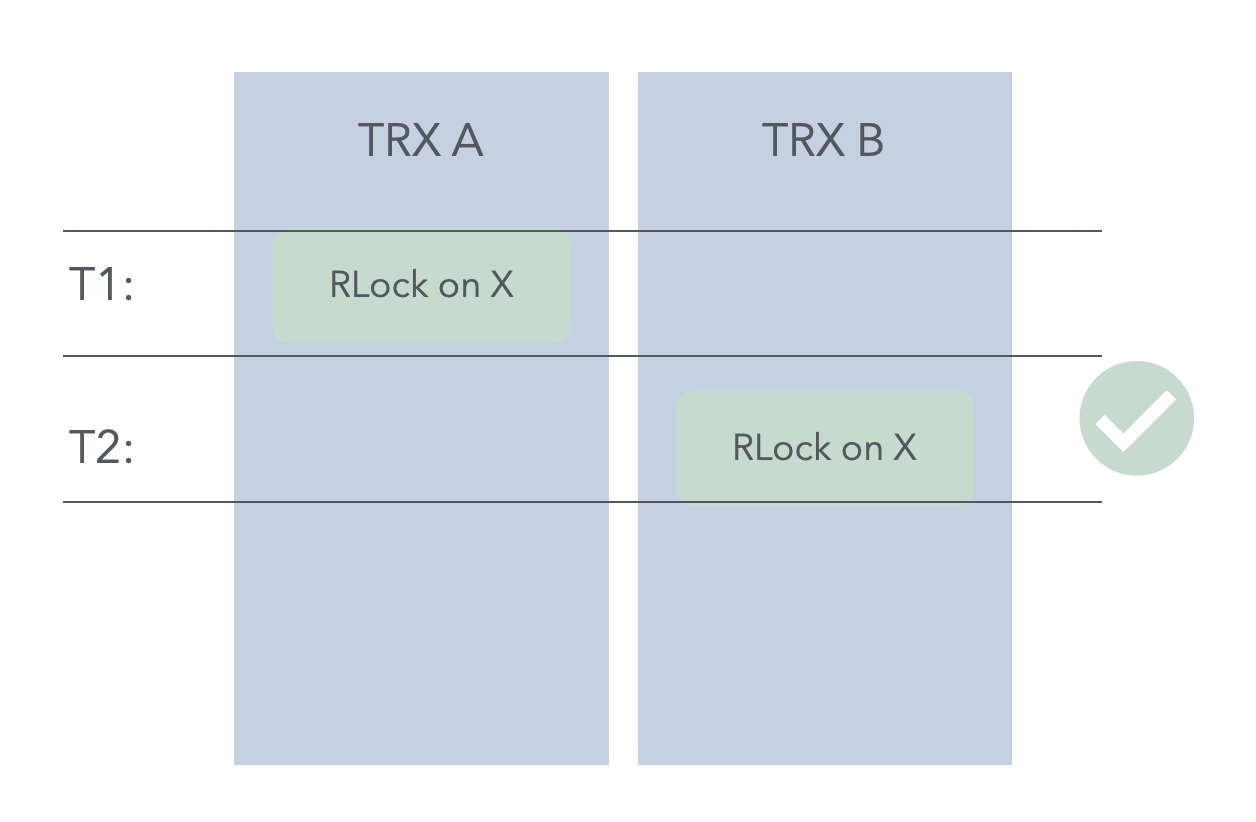
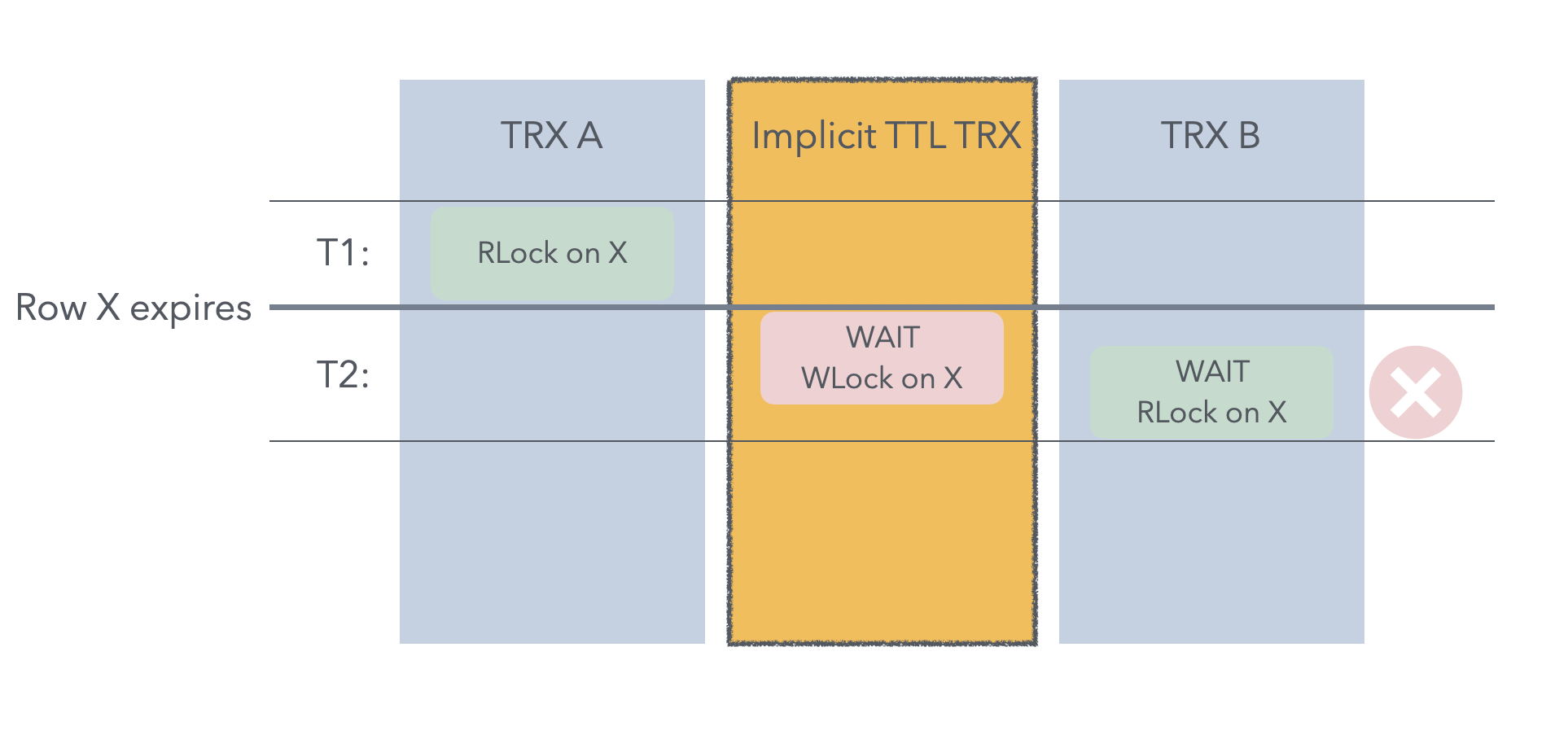
原本的行为,事务B会立刻获取到X读锁。但有了TTL上述定义后,假设在1,2之间X的过期时间到了,那么就要想象有一条隐式的TTL写事务尝试获取并等待在X的写锁上,这就导致事务B也要等待在X的读锁上,直到事务A提交。
基于上述TTL定义,我们给出相应实现:
- Locking Read:在一个事务中,对于同一条记录,只有首次加锁需要判断TTL过期,如果过期这当做记录不存在。如果未过期则加锁成功。在接下来的操作中,如果再次读取同一条记录,该条记录总是对其可见。
- Consistent Nonlocking Read (MVCC):在一个事务中,根据隔离级别(RR或者RC)在相应位置创建read view,每个read view有自己的创建时间。读到一条记录后:
- 先通过read view判断可见性,如果可见:
- 通过该read view创建时间判断TTL过期,如果已过期:
- 判断该记录是否有本事务加的锁(读 / 写锁),如果有,则可见。
这是一个简单的在事务中TTL过期的实例:
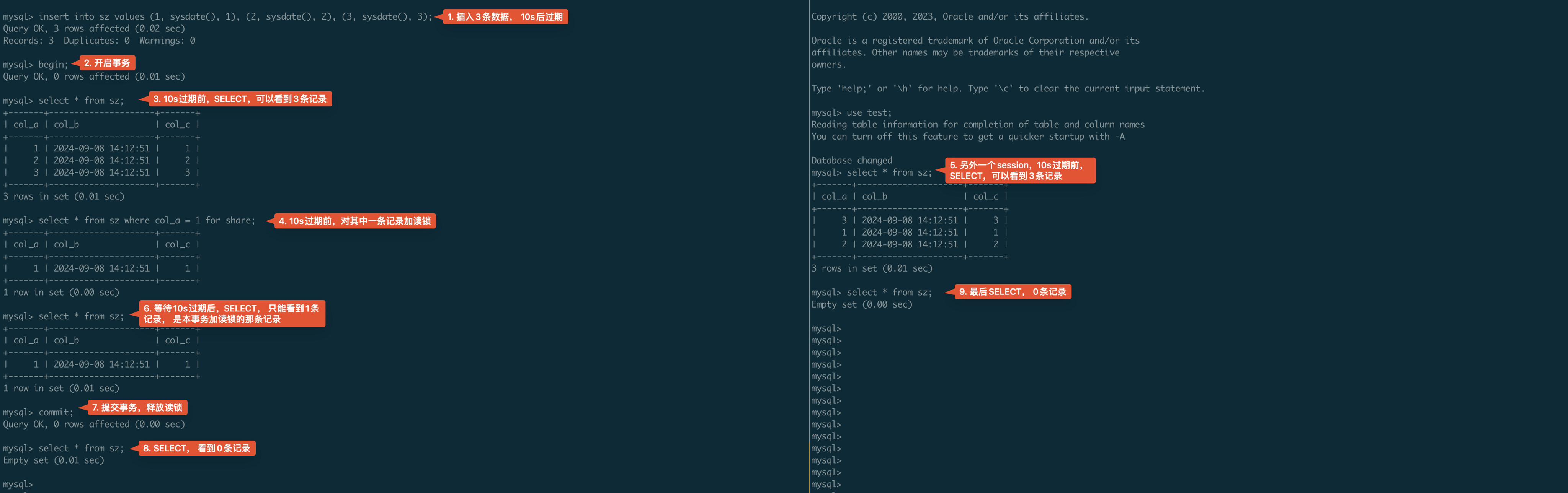
6. 过期数据回收
这个理想的实现是类似Undo穿成版本链一样,再穿一个TTL过期链,然后从最老开始进行精确的purge。但我这一版的实现简单粗暴(但有效),存储引擎搞一个定期扫描TTL表的任务,分批扫出已经过期的记录,根据当前负载控制batch大小,进行删除。
注:对于NDB引擎,分布式架构下不太好搞TTL过期链,甚至把扫描purge任务放到data node上也不像InnoDB那样容易,所以我的梭版是放在MySQL Server层,通过新加的特殊NDB Cluster API,MySQL Server可以从data nodes上精准拿到已经过期的数据,然后batch删除
7. 其他
还有很多其他问题需要考虑,尤其对于NDB引擎:
- 过期时间的时区问题(MySQL Server的时区是session变量,NDB data nodes根本无法感知)
- NDB data nodes之间主从副本的数据同步问题
- MySQL Server的binlog是NDB data nodes反向吐给它的,所以还有生成binlog的问题已经MySQL自身主从同步
- Backup 和 Restore
对于InnoDB,因为只是单机引擎,这些问题会简单很多,我认为InnoDB最大的挑战就是如何优雅的把过期数据穿成像Undo一样的链,精准且优雅的purge
8. 局限性
这一版的TTL还有一些局限性无法很好的兼容MySQL。
- 外键,如果一张TTL表有外键约束,那么他的记录TTL过期并不能触发其子表的级联删除。
- 触发器,如果我们将TTL视为删除,那么TTL过期并不能触发ON DELETE的触发器
这俩问题本质是一样的,TTL的实现是delay deletation,过期那一刻并不是立刻触发删除,对于这种有级联行为的feature暂时没有想到有效的解决方案。欢迎讨论。