昨天用systemtap跑了下pika的火焰图,今天做了下简单的对比分析,这里总结一下
1. 方法
- 使用50个clients分别压(set方法、key+value约50字节)pika和redis,pika cpu 100%,redis cpu 64%
- 使用同样用例开24个线程裸压rocksdb,cpu前期64%,随着写入的持续会触发compact,随后接近100%
- 对pika、redis、rocksdb分别使用systemtap采样(用户态)绘制火焰图进行分析
2. 火焰图
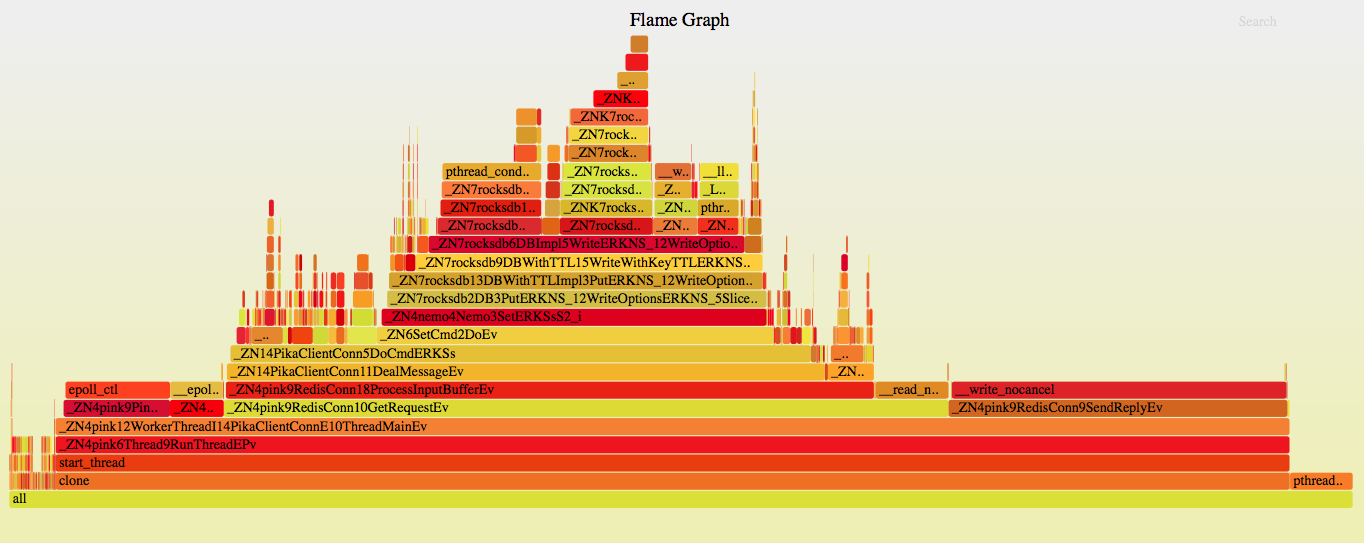
pika
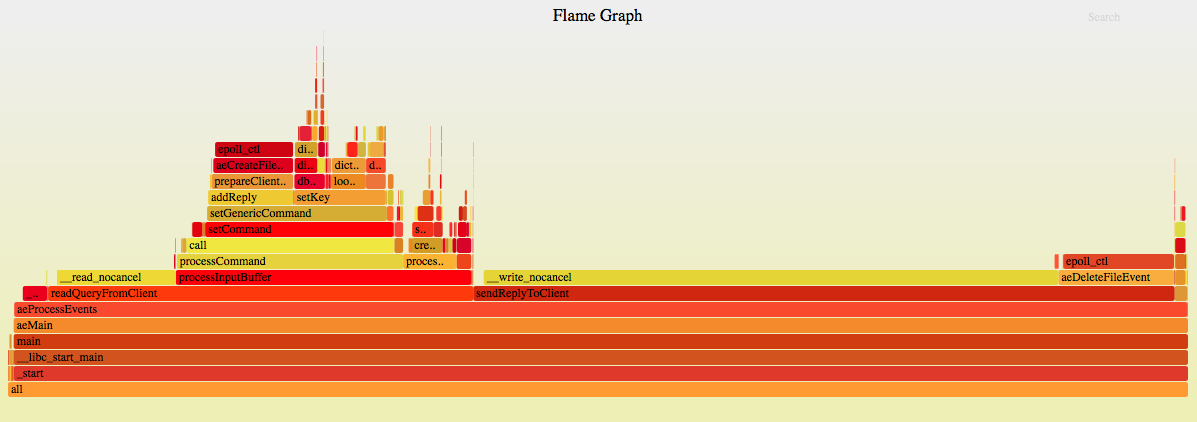
redis
rocksdb
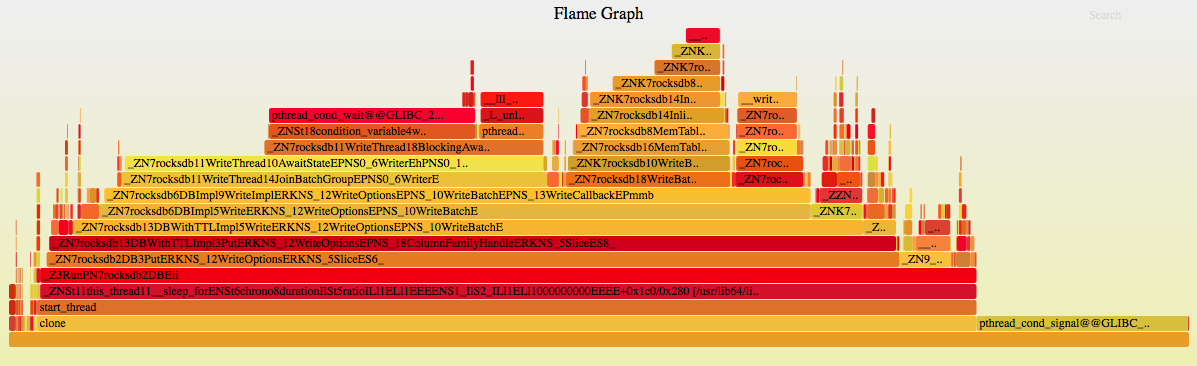
3. 结果对比
| Pika | Redis | |
|---|---|---|
| __read_nocancel | 5.04% | 10.05% |
| __write_nocancel | 24.92% | 48.71% |
| epoll_ctl | 7.78% | 9.39% |
| __epoll_wait_nocancel | 3.92% | 2.06% |
| processMultibulkBuffer | 3.43% | 4.35% |
| processCommand | 29.55% | 19.16% |
| RestoreArgs | 2.34% | |
| RecordMutex (lock+unlock) | 1.7% | |
| Mutex (lock+unlock) | 1.23 | |
| Binlog::Put (__memmove_ssse3_back 0.84%) | 2.16% | |
| rwlock (lock+unlock) | 0.85% |
4. 结论
-
从结果对比前4项可以看到无论是pika还是redis,对于网络的收发占比均接近1:5,证明pika的在网络及事件处理这块和redis没什么差压,所以针对此无明显优化方案
-
从第5项可以看到pika在协议解析方面已实现的比较完善,无明显优化方案
-
从第6项processCommand来看,pika由于底层用的是rocksdb,所以占比较高,redis这里主要耗在字符串处理、hash处理上;通过processCommand之上火焰图与裸压rocksdb的火焰图对比,这里基本一致,所以可以认为此处开销就是rocksdb本身的开销,也无明显优化方案
-
后5项是pika自身逻辑带来的开销,主要占比比较大的是RestoreArgs和Binlog::Put,不过即使全部算上也不到10%,这块可以优化但由于占比很小所以整体不会有明显提升
综上所述,对于小value写入的场景,pika 会使CPU达到瓶颈,后续需要看下是否可以通过Tuning rocksdb来稍微缓解一下这个问题
Ps:发现pika一个可优化的小”bug”:每次处理fd可写事件居然是把wbuf里的东西在while里一次发完。。。如果wbuf非常大,那就悲剧了。需要改成和处理可读事件一样的逻辑,这次没做完,下次事件处理再做