在下一篇写rocksdb关于读优化之前,先铺垫一片基础,关于thread-specific data(线程私有存储),之前博客讲tcmalloc的ThreadCache的时候也有提到过,rocksdb也正是用了线程私有存储来优化读性能,具体的优化先卖个关子,下篇再说,本篇先总结一下rocksdb对线程私有存储的封装,很实用。
Thread-Specific data
一个线程,除了自己的栈和寄存器之外,其他基本上都是共用的,那么问题来了,假如每个线程需要有自己的私有存储,该怎么实现?首先明确一下,线程私有存储的需求并不是YY出来的,以tcmallo为例,tc就是thread cache,它的思想就是从操作系统申请到的内存,每个线程都在自己的私有存储中缓存一部分,这样大多数时候线程之间的内存申请和释放就不需要加一把大锁来做,极大提高的性能。还有rocksdb对version的缓存(下篇介绍)也需要这么做。
怎么实现线程私有存储呢,这就是pthread_key_t,用法也不难,写了个简单的例子,如下:
#include <iostream>
#include <thread>
#include <chrono>
pthread_key_t key;
class Content {
public:
Content(int num) : num_(num) {
}
~Content() {
std::cout << "Destroy Content, whose num_ is " << num_ << std::endl;
}
int num_;
};
void OnThreadExit(void *ptr) {
std::cout << "OnThreadExit for thread " << std::this_thread::get_id()
<< std::endl;
delete static_cast<Content *>(ptr);
}
void Func(int num) {
Content *ptr = new Content(num);
pthread_setspecific(key, ptr);
std::cout << "Thread " << std::this_thread::get_id() << " set key to "
<< ptr->num_ << ", object addr = " << ptr << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(2000));
std::cout << "Thread " << std::this_thread::get_id() << " get key: "
<< static_cast<Content *>(pthread_getspecific(key))->num_
<< ", object addr = " << pthread_getspecific(key) << std::endl;
}
int main(void)
{
pthread_key_create(&key, OnThreadExit);
std::thread t1 = std::thread(Func, 6);
std::this_thread::sleep_for(std::chrono::seconds(1));
std::thread t2 = std::thread(Func, 8);
t1.join();
t2.join();
pthread_key_delete(key);
std::cout << "Bye!" << std::endl;
return 0;
}
输出如下:
Thread 139729139767040 set key to 6, object addr = 0x7f15340008c0
Thread 139729129277184 set key to 8, object addr = 0x7f152c0008c0
Thread 139729139767040 get key: 6, object addr = 0x7f15340008c0
OnThreadExit for thread 139729139767040
Destroy Content, whose num_ is 6
Thread 139729129277184 get key: 8, object addr = 0x7f152c0008c0
OnThreadExit for thread 139729129277184
Destroy Content, whose num_ is 8
Bye!
例子不多做解释,这就是线程私有存储的基本用法。
ThreadLocalPtr
上面说了线程私有存储的基本用法,不过这个有点原生,假如有这么一个场景:一个进程,有10个变量需要所有线程私有存储,怎么做?pthread_key_create()10次?可以。。。如果需要线程私有存储变量个数提前不可知,怎么做?呃,有点麻烦,因为不太好维护动态生成的pthread_key_t,其他的线程也不好知道新创建的pthread_key_t是什么,啧啧。
其实不需要给每个变量单独pthread_key_create(),全局就一个pthread_key_t,这样所有线程都能知道它并通过它来访问自己的私有存储,然后在这个私有存储上做文章,让它支持维护多个变量就可以了,rocksdb就是这么做的,封装了一个ThreadLocalPtr,所有的事情都有它来做,对外暴露的接口和使用及其简单,下面就来看下ThreadLocalPtr是怎么实现的
1. 使用方法
ThreadLocalPtr对外暴露的接口很简单,一般主要Get和Swap,典型用法是这样:
/*
* 1. 首先定义线程退出回调函数
*/
void UnrefHandle(void *ptr) {
//当线程退出的时候会回调UnrefHandle来
//释放该线程的私有存储,ptr指向该私有存储地址
//所以这里需要定义这块私有存储该如何释放
//比如最简单的:
//delete static_cast<XXX>(ptr);
}
/*
* 第一个私有变量创建及使用
*/
// 创建第一个私有存储变量
ThreadLocalPtr *local_1 = new ThreadLocalPtr(&UnrefHandle);
// 设置本线程对应的该私有存储变量的值
XXX *ptr_1 = new XXX();
void *old_ptr_1 = local_1->Swap(ptr_1);
// 读取本线程对应的私有存储变量的值
void *cur_ptr_1 = local_l->Get();
// local_1需要在pthread_create的时候传给新创建的线程,这样新创建的线程就可以
// 通过它来访问自己线程对应的私有存储
/*
* 第二个私有变量创建及使用
*/
// 创建第二个私有存储变量
ThreadLocalPtr *local_2 = new ThreadLocalPtr(&UnrefHandle);
// 设置本线程对应的该私有存储变量的值
XXX *ptr_2 = new XXX();
void *old_ptr_2 = local_2->Swap(ptr_2);
// 读取本线程对应的私有存储变量的值
void *cur_ptr_2 = local_2->Get();
用法非常简单,创建local_1之后,所有线程就可以认为它是某个私有存储变量在本线程对应的地址,可以随意进行读写,也不需要管释放,只要定义好正确的回调,本线程退出时会自动释放其对应的私有存储
2. 实现
实现也不难,整体就一个ThreadLocalPtr的类,以及它的三个内部类,包括ThreadLocalPtr::StaticMeta,ThreadLocalPtr::ThreadData和ThreadLocalPtr::Entry,具体如下图:
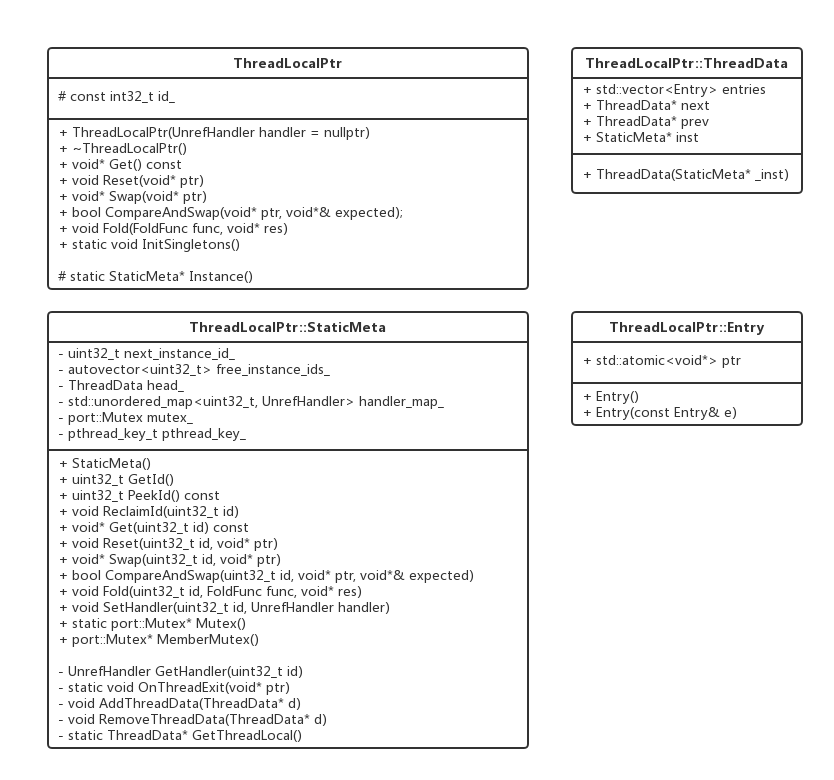
前面提到过,ThreadLocalPtr实际就只使用了一个pthread_key_t变量,然后在其对应的私有存储上做文章来支持多个私有存储变量的维护,怎么做的呢,从创建开始,一步一步来看:
一开始肯定是要new一个ThreadLocalPtr变量了,先看下构造函数:
ThreadLocalPtr::ThreadLocalPtr(UnrefHandler handler)
: id_(Instance()->GetId()) {
if (handler != nullptr) {
Instance()->SetHandler(id_, handler);
}
}
里面用到了Instance(),通过上面的类图知道,这是一个类的静态函数,实现如下:
ThreadLocalPtr::StaticMeta* ThreadLocalPtr::Instance() {
static ThreadLocalPtr::StaticMeta* inst = new ThreadLocalPtr::StaticMeta();
return inst;
}
可以看到这里生成了一个ThreadLocalPtr::StaticMeta对象,并用一个静态的指针inst指向它,也就是说在Instane()第一次调用的时候会创建一个ThreadLocalPtr::StaticMeta对象,仅创建一次,以后再调用就直接返回已经赋值的inst指针即可,可以认为全局就一个ThreadLocalPtr::StaticMeta对象。没错,这里就已经可以看出一些线索了,ThreadLocalPtr的对象可以有多个,但他们其实都在使用同一个ThreadLocalPtr::StaticMeta对象,那接着再看下ThreadLocalPtr::StaticMeta的构造函数:
ThreadLocalPtr::StaticMeta::StaticMeta() : next_instance_id_(0), head_(this) {
if (pthread_key_create(&pthread_key_, &OnThreadExit) != 0) {
abort();
}
static struct A {
~A() {
ThreadData* tls_ =
static_cast<ThreadData*>(pthread_getspecific(Instance()->pthread_key_));
if (tls_) {
OnThreadExit(tls_);
}
}
} a;
head_.next = &head_;
head_.prev = &head_;
刚才说了全局只会有一个ThreadLocalPtr::StaticMeta对象,那么这个构造函数也只会调一次,这里也是全局唯一一次pthread_key_create()的调用,成功后,pthread_key_会被赋值,以后就可以通过pthread_key来读写私有存储了。看下初始化列表,next_instance_id_是什么?其实每个不同ThreadLocalPtr对象都有一个全局唯一id,这个id的唯一性就是通过全局唯一的ThreadLocalPtr::StaticMeta对象的next_instance_id_来递增来保证的,第一次肯定为0,head_是什么呢?看下上面的类图,它的类型是ThreadLocalPtr::ThreadData,从定义能推测,ThreadLocalPtr::ThreadData应该就是私有存储了,一个线程对应一个ThreadLocalPtr::ThreadData对象,并且他们相互之间通过next和prev指针串起来,另外每个ThreadLocalPtr::ThreadData对象通过自己的inst指针指向全局唯一的ThreadLocalPtr::StaticMeta对象(通过head_(this)来赋值,这里可以看到一个类可以在自己的初始化列表中使用将要创建出来的对象的this指针),所以head_干什么用的也就清楚了,用链表的形式来维护所有线程对应的私有存储。这里发现还有一个static struct A,这是干什么用的呢?等会再说。
好了,Instance()说完了,往上返回,回到ThreadLocalPtr的构造函数,到了这一步:
id_(Instance()->GetID())
看下GetID()的实现:
uint32_t ThreadLocalPtr::StaticMeta::GetId() {
MutexLock l(Mutex());
if (free_instance_ids_.empty()) {
return next_instance_id_++;
}
uint32_t id = free_instance_ids_.back();
free_instance_ids_.pop_back();
return id;
}
这里用到了free_instance_ids_和next_instance_id_,前者不多说了,其实就是保存回收的id,总之,GetID会返回一个全局唯一的id
继续回到构造函数,上一步返回的id赋值给ThreadLocalPtr的id_,至此我们new出来的ThreadLocalPtr有了唯一的id,接着走完,剩下最后一步:
if (handler != nullptr) {
Instance()->SetHandler(id_, handler);
}
这个handle就是用户传入的回调函数地址,SetHandler想必就是将正在创建的ThreadLocalPtr对象的id与其回调函数建立映射,方便在将来销毁是反查执行,定义如下:
void ThreadLocalPtr::StaticMeta::SetHandler(uint32_t id, UnrefHandler handler) {
MutexLock l(Mutex());
handler_map_[id] = handler;
}
至此,我们已经顺利创建出来第一个ThreadLocalPtr对象,先别着急用,我们紧接着创建第二个ThreadLocalPtr对象看看会发生什么,继续调用构造函数,此时Instance()直接返回ThreadLocalPtr::StaticMeta对象指针,然后GetID拿到下一个id赋值给新对象,接着SetHandler完成新对象及其回调函数的映射,此时对象关系大致如下图左半部分黄色区域:
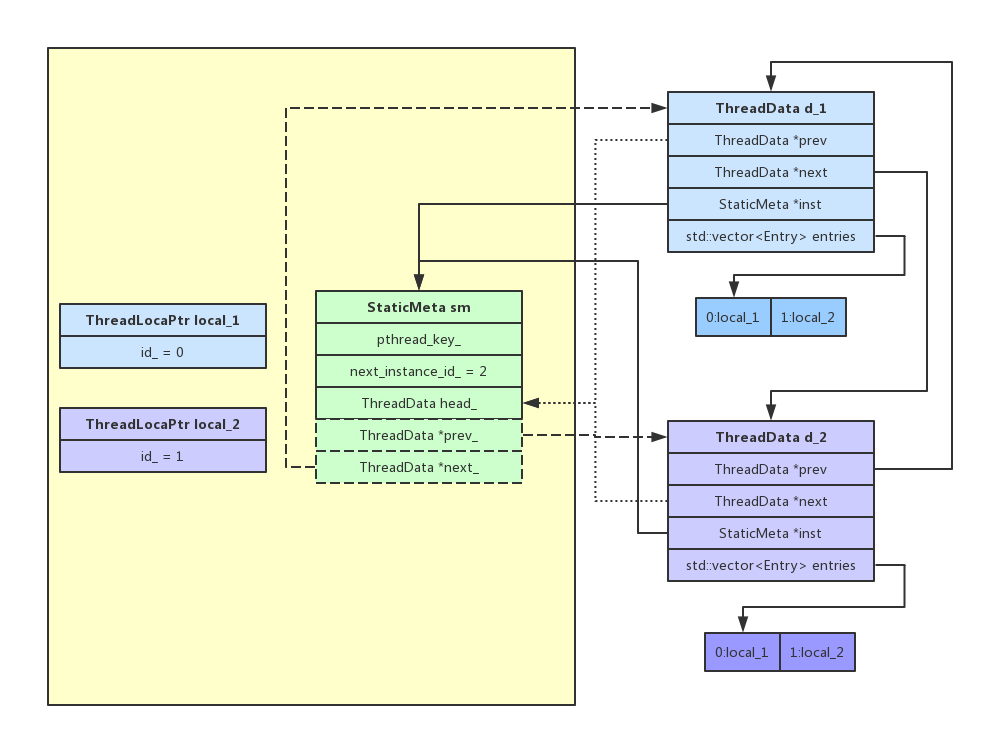
很简单,两个ThreadLocalPtr对象local_1和local_2,一个全局的ThreadLocalPtr::StaticMeta对象sm,这个时候还没有图中右办部分的东西(d1和d2),也就是每个线程自己专属的ThreadLocalPtr::ThreadData对象还没创建。
接着,开始使用刚才创建的两个ThreadLocalPtr对象,先这么用:
local_1->Swap(point_to_sth_for_local_1);
local_2->Swap(point_to_sth_for_local_2);
通过swap来给本线程所属的两个私有存储local_1和local_2赋值,存入东西。来看下Swap的实现:
void* ThreadLocalPtr::Swap(void* ptr) {
return Instance()->Swap(id_, ptr);
}
这里调用的是ThreadLocalPtr::StaticMeta的Swap,继续跟:
void* ThreadLocalPtr::StaticMeta::Swap(uint32_t id, void* ptr) {
auto* tls = GetThreadLocal();
if (UNLIKELY(id >= tls->entries.size())) {
// Need mutex to protect entries access within ReclaimId
MutexLock l(Mutex());
tls->entries.resize(id + 1);
}
return tls->entries[id].ptr.exchange(ptr, std::memory_order_acquire);
}
Swap参数是id和ptr,id从ThreadLocalPtr传入,是具体某个ThreadLocalPtr对象的id,比如local_1的话就是0,local_2的话就是1,ptr就是咱们要给私有空间赋的值的指针,进来后首先GetThreadLocal(),从名字上就可以看出,这个函数就是要取出属于本线程对应的私有存储,即ThreadLocalPtr::ThreadData对象,来看实现:
ThreadLocalPtr::ThreadData* ThreadLocalPtr::StaticMeta::GetThreadLocal() {
ThreadData* tls_ =
static_cast<ThreadData*>(pthread_getspecific(Instance()->pthread_key_));
if (UNLIKELY(tls_ == nullptr)) {
auto* inst = Instance();
tls_ = new ThreadData(inst);
{
MutexLock l(Mutex());
inst->AddThreadData(tls_);
}
if (pthread_setspecific(inst->pthread_key_, tls_) != 0) {
{
MutexLock l(Mutex());
inst->RemoveThreadData(tls_);
}
delete tls_;
abort();
}
}
return tls_;
上来先通过pthread_getspecific()来取自己的私有存储,有就返回,没有就创建,咱们这是第一次,所以创建一个新的ThreadLocalPtr::ThreadData对象,将它加到全局ThreadLocalPtr::StaticMeta对象的head_链表中,然后将这个ThreadLocalPtr::ThreadData对象通过pthread_setspecific()来存入自己的私有存储。
再回到Swap,GetThreadLocal()返回了本线程的私有存储对象,即ThreadLocalPtr::ThreadData对象,tls指向它,然后通过tls->entries[id].ptr.exchange()来交换entries中对应id索引位置元素的值,即完成最终Swap,entries是一个vector,id是从上层传入的,这里就明了了,为什么每个ThreadLocalPtr对象要有自己的id,这个id就是用到这里,实际就是不同ThreadLocalPtr对象对应的私有存储地址就是entries中的不同位置索引的元素。至此,所有关系都已经缕清,再返上去看看对象关系图,已经很明了了
结合上图简单总结一下:
每个进程就一个sm对象,sm对象pthread_key_create()一个pthread_key_,用户使用的local_1和local_2在创建时通过sm拿到自己所属的唯一的id,当通过local_1来访问本线程私有存储时,首先通过pthread_getspecific()尝试获取属于本线程的ThreadLocalPtr::ThreadData对象(本例中d-1和d_2分别是不同线程对应的私有存储),有的话就直接用,没得话创建一个,假设是上图d_1,然后调用pthread_setspecific()存入私有存储并链如sm的head_,以后再用的话就可以通过pthread_getspecific()直接拿到,d_1是保存本线程对应的所有私有存储空间地址的vector,不同的私有存储空间即ThreadLocalPtr对象有不同的对象,每个对象有不同的id,这个id便是这里vector的索引,可以看到,全局的私有存储试图就是一张表(本例中的[d_1 , d_2] * [local_1 * local_2]),横轴是不同私有存储变量,纵轴是不同线程(一个线程有属于自己的所有的私有存储变量,一个私有存储变量在不同线程有不可能不同的值)
如果某个线程退出,则会执行最开始注册的回调函数OnThreadExit,来看下:
void ThreadLocalPtr::StaticMeta::OnThreadExit(void* ptr) {
auto* tls = static_cast<ThreadData*>(ptr);
assert(tls != nullptr);
// Use the cached StaticMeta::Instance() instead of directly calling
// the variable inside StaticMeta::Instance() might already go out of
// scope here in case this OnThreadExit is called after the main thread
// dies.
auto* inst = tls->inst;
pthread_setspecific(inst->pthread_key_, nullptr);
MutexLock l(inst->MemberMutex());
inst->RemoveThreadData(tls);
// Unref stored pointers of current thread from all instances
uint32_t id = 0;
for (auto& e : tls->entries) {
void* raw = e.ptr.load();
if (raw != nullptr) {
auto unref = inst->GetHandler(id);
if (unref != nullptr) {
unref(raw);
}
}
++id;
}
// Delete thread local structure no matter if it is Mac platform
delete tls;
}
做的就是把自己的私有存储清空,将自己的ThreadLocalPtr::ThreadData对象tls从ThreadLocalPtr::StaticMeta对象的head_中摘除,然后遍历tls中的entries的所有私有存储变量,通过id拿到用户注册的回调unref,调用它来释放私有存储空间,最终删除tls
如果某个ThreadLocalPtr对象被销毁,则执行其析构函数,这里就不展开了,很简单,就是将该对象对应的id交给sm回收,以便给下一个创建的PthreadLocalPtr对象使用,并且遍历sm的head_,把每个ThreadLocalPtr::ThreadData对象的entries中对应id的空间调用unref回收
3. 疑问
-
一般单例的是这么做:
#include <iostream> class Singleton { public: ~Singleton() { std::cout << "destruction!\n"; } static Singleton *getInstance() { // 方法1 static Singleton instance; return &instance; /* 方法2 static *ints = new Singleton(); return 0; */ } private: Singleton() { std::cout << "construction!\n"; } };代码中方法2是一个不好的实现,因为new出来的Singleton对象不会被任何人释放,内存泄漏(虽然不严重),我测试了一下,如果使用方法2,那么Singleton的析构函数永远不会被调用,方法1则会。但是,ThreadLocalPtr的Instance用的是方法2,它有解释:
Note that here we decide to make “inst” a static pointer w/o deleting it at the end instead of a static variable. This is to avoid the following destruction order desester happens when a child thread using ThreadLocalPtr dies AFTER the main thread dies: When a child thread happens to use ThreadLocalPtr, it will try to delete its thread-local data on its OnThreadExit when the child thread dies. However, OnThreadExit depends on the following variable. As a result, if the main thread dies before any child thread happen to use ThreadLocalPtr dies, then the destruction of the following variable will go first, then OnThreadExit, therefore causing invalid access.
它的意思是说如果main thread先于其他thread退出,那么当其他thread再退出时回调的OnThreadExit函数会用到单例的inst,而这个inst已经由于main thread退出被析构,所以这里通过使用方法2,让inst对象人为被泄漏,谁也不释放,这样的话任何时候都可以访问inst对象。看似合理,不过我写代码测试了一下,即使用方法1,也不会造成invalid access,是作者多虑了还是我想简单了?
-
ThreadLocalPtr::StaticMeta的构造函数里,有一个static struct A,它的析构函数是主动调用OnThreadExit来回收空间,看了下作者的解释,他的意思是虽然其他的thread在退出时会通过回调OnThreadExit来释放其私有存储空间,但主线程没有机会来执行回调,那么主线程的私有空间就不会被释放,造成泄漏,所以通过构造一个static A,A的析构函数肯定会被调用从而这里执行回调进行main thread私有存储空间的释放。为什么要这么做呢?上一个问题提到过,因为StaticMeta对象是new出来的永远不会调析构函数,即使程序退出,所以放在StaticMeta的析构函数的逻辑不会被执行,但如果其构造函数里再定义一个static A变量,这个A肯定会被析构函数(我验证过),所以将回调写到这里会被最终调用的。其实这里不回收也没关系,因为程序都要退出了,不过有了这个过程更加严谨。那么问题来了,如果上一个问题用的是方法2,那么StaticMeta的析构函数肯定会被调用,把回调写到这里岂不是更好?所以问题1到底谁对谁错,还得研究研究
-
看上面的类图,有好多static的成员函数,感觉有些没必要,比如ThreadLocalPtr::StaticMeta::Mutex(),没什么卵用啊
结合问题1,,我自己写代码测试了,发现没有作者说的问题,代码如下:
#include <iostream>
#include <thread>
#include <unistd.h>
class A {
public:
class B;
class C {
public:
C(B *pb) : pb_(pb) {
}
~C() {
std::cout << "destroy C" << std::endl;
}
B *pb_;
};
class B {
public:
B(int n) : n_(n) {
std::cout << "construct B" << std::endl;
pthread_key_create(&key_, OnThreadExit);
static struct La {
~La() {
std::cout << "destroy La" << std::endl;
C* pc = static_cast<C *>(pthread_getspecific(Instance()->key_));
if (pc != nullptr) {
OnThreadExit(pc);
}
}
}la;
}
~B() {
std::cout << "destroy B" << std::endl;
}
void Get() {
C* pc = GetThreadLocal();
pc->pb_->Output();
}
int GetID() {
n_++;
return n_-1;
}
void Output() {
std::cout << n_ << std::endl;
}
private:
int n_;
pthread_key_t key_;
static C* GetThreadLocal() {
C *pc = static_cast<C*>(pthread_getspecific(Instance()->key_));
if (pc == nullptr) {
B* pb = Instance();
pc = new C(pb);
pthread_setspecific(pb->key_, pc);
}
return pc;
}
static void OnThreadExit(void *ptr) {
std::cout << "OnThreadExit: ";
// static_cast<C *>(ptr)->pb_->Output();
Instance()->Output();
delete static_cast<C *>(ptr);
}
};
A() : id_(Instance()->GetID()) {
}
~A() {
std::cout << "destroy A whose id_ = " << id_ << std::endl;
}
void Get() {
Instance()->Get();
}
static B *Instance() {
// static B *ptr = new B(0);
// return ptr;
static B b(0);
return &b;
}
int id_;
};
void *Func(void *ptr) {
A* pa = static_cast<A *>(ptr);
pa->Get();
sleep(5);
}
int main(void) {
A *pa = new A();
pa->Get();
pthread_t tid;
pthread_create(&tid, NULL, Func, pa);
sleep(2);
delete pa;
sleep(10);
// pthread_exit(NULL);
return 0;
}
输出:
construct B
1
1
destroy A whose id_ = 0
OnThreadExit: 1
destroy C
destroy B
destroy La
OnThreadExit: 1
destroy C
总结
线程私有存储还是十分有用了,rocksdb已经封装了它并且用在自己的实现中,如此一来,感觉重构nemo的最大问题已经解决,之前之所以nemo需要改动rocksdb源码是因为nemo需要rocksdb在compact中做一个meta_key的回查,缓存这个meta_key,在下个操作中看能不能复用,这样可以提高compact速度。但修改rocksdb代码导致nemo不能快速跟进rocksdb官方版本,如果不改rocksdb代码而是在上面包一层来完成目前所有nemo的功能,这样倒是可以直接更新rocksdb版本,但包一层的话compact这里是个难点,毕竟多线程compact的情况下每个线程临时保存的回查meta_key的值没地方放,这下好了,直接用ThreadLocalPtr来存,在自己实现的外部compactfilter中来访问,简直完美啊。