背景
熟悉leveldb的同学应该对compaction不陌生:当level N满足compaction条件时,会选level N的若干文件及level N+1相应key range内的文件一起做compaction,将结果写到level N+1新文件中并删除老的文件。在level 1+的每个level中,各个文件的key range互不覆盖(从小到大排列),而level 0比较特殊,因为它是由memtable flush而来,所以每个文件的key range会有重叠,当level 0的文件个数达到4个的时候,会触发level 0到level 1的compaction,所以这里会大概率的将level 0的4个文件一起选中到同一次compaction中。正是由于level 0文件之间没有清晰的边界,所以rocksdb虽然早就有多线程compaction,但对level 0到level 1这块却还只能单线程搞,导致这里成为compaction的瓶颈。后来有了subcompaction,终于实现了这里的并行,本篇博客就介绍下subcompaction的实现。
实现
-
【选择文件】:level 0有最大的compaction score,选择level 0中size最大的文件准备进行compaction,经过一些列演算,最终会拿到level 0及level 1中所有待compaction的文件集合,这就是本次compaction的input
-
【生成bounds】:将input中level 0的每个文件的smallest key和largest key依次push_back到bounds中(bounds是vector
),并将input中base level(一般就是level 1)的每个文件的smallest key及input中level 1所有文件的整体smallest key及largest key一起push_back到bounds中,如下图所示,然后进行sort,unique 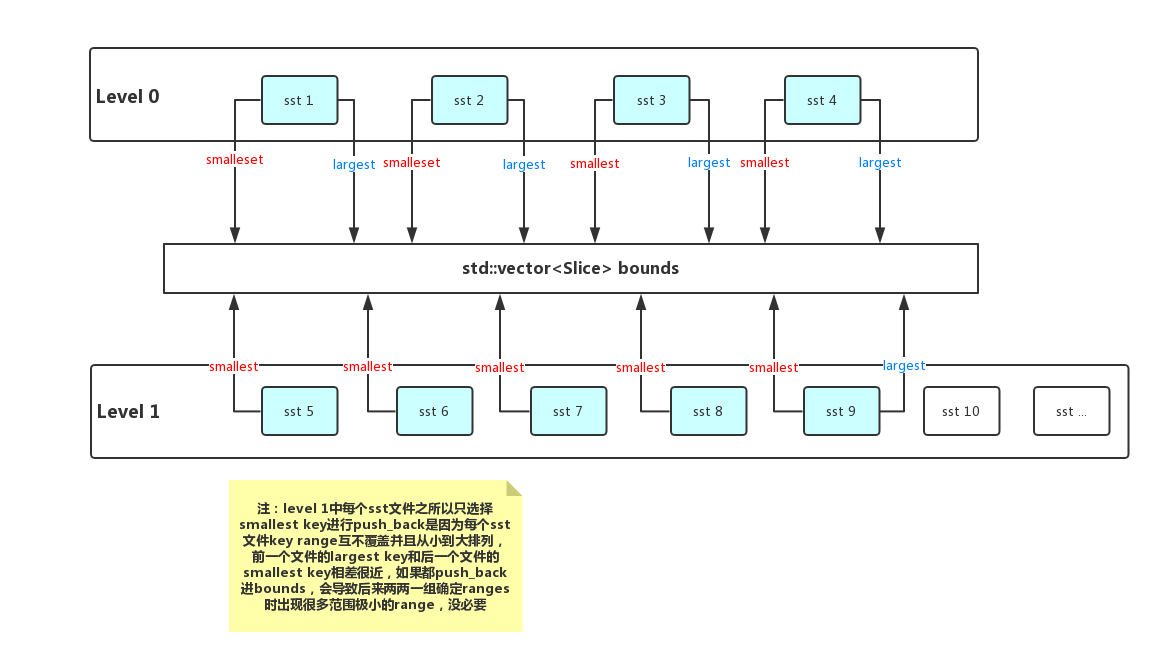
-
【生成ranges】:通过第2步,会拿到一个字典序从小到大的vector
,然后依次两两为一组,算出该组中smallest key及largest key之间的key range在level 0、level 1及level 2所有文件中覆盖的字节大小,记为size,将这个size连同本组smallest key、largest key一起打包成RangeWithSize存在ranges中(ranges是vector ),结果如下图所示,这里还会将每组的size累加的sum当中,后面会用 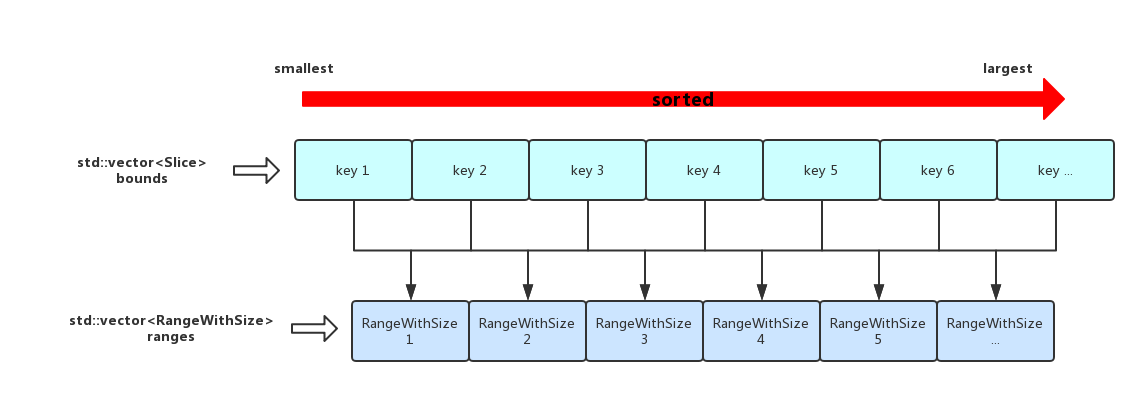
-
【确定subcompactions】确定subcompaction的线程个数,这里主要有3个参考值:
- 用户配置的max_subcompaction
- 第3步最终ranges中的元素个数
- max_output_files:公式是sum/4.0/5/max_file_size[1],其中sum是第3步中所有组的size的累加,max_file_size[1]是level 1中单个文件的最大大小,v5.0.1的默认配置是64M
取上述3者的最小值为subcompaction的线程数,记为subcompactions
-
【划分subcompaction的key range】:subcompaction的线程数已经确定,最后就是将ranges里的RangeWithSize按照subcompaction线程数合并划分成对应的个数,交给不同的线程去compact即可,如何划分:
- 确定mean:mean = sum/subcompacions
- 依次遍历ranges中的每个RangeWithSize,累加他们的size,直到totalsize>=mean时,将之前的RangeWithSize合并在一起,把他们整体的key range交给一个线程去compact,并清空totalsize继续遍历
通过上面5步,就将level 0到level 1的一次compaction按照合理的key range划分成为互不覆盖,互不影响的多个subcompaction并交给多个子线程并行去做,不同的子线程compaction结果输出到不同的文件中,等所有子线程完成自己的compaction后,主compaction线程进行结果整理合并,最终完成本次compaction。
这就是subcompaction的流程,需要说明的是,所有subcompaction读的都是相同的文件(即第1步的input集合中的文件),不过每个sub线程只负责这些文件一部分key range的compact 工作。
总结
和memtable concurrent write一样,rocksdb的level 0到level 1的多线程compaction也是开始一个线程准备参数,然后开启多个线程并行执行,最终再由一个线程收尾的方式来提高并行度,是一个不错的实现,一定程度上解决了level 0到level 1 compaction的瓶颈,代码算是梳理完了,不过rocksdb v5.0.1默认是关闭subcompaction,后续还需要实测一下看看打开后这块优化效果有多大。
Ps: 猴年博客最后一更,一共写了23篇,鸡年继续加油,努力学习,持续更新,持续进步^^