说到mutex和atomic,直觉上就知道atomic效率肯定高于mutex(mutex要lock和unlock两次操作,而atomic只需要一次),不过具体高多少呢,自己一直没有量化的结果,所以今天实际测了一下
测试方法
两个变量
volatile unsigned int count;
std::atomic<int> a_count;
单线程循环1000万次,对两个变量进行累加,其中count前后使用mutex保护,具体代码如下:
#include <iostream>
#include <chrono>
#include <atomic>
const int kNum = 10000000;
int main() {
volatile unsigned int count;
pthread_mutex_t mutex;
std::atomic<int> a_count;
pthread_mutex_init(&mutex, 0);
count = 0;
a_count.store(0);
auto begin = std::chrono::steady_clock::now();
while (count < kNum) {
pthread_mutex_lock(&mutex);
count++;
pthread_mutex_unlock(&mutex);
}
auto end = std::chrono::steady_clock::now();
std::chrono::duration<int, std::nano> diff = end - begin;
std::cout << "count = " << count << ", Mutex used: "
<< diff.count() << std::endl;
begin = std::chrono::steady_clock::now();
while (a_count.fetch_add(1, std::memory_order_relaxed) < kNum-1) {
//对计数的场景,这里使用std::memory_order_relaxed更合适,性能更高
};
end = std::chrono::steady_clock::now();
diff = end - begin;
std::cout << "a_count = " << a_count.load() << ", Atomic used: "
<< diff.count() << std::endl;
pthread_mutex_destroy(&mutex);
return 0;
}
跑了3次,结果如下(单位纳秒):
count = 10000000, Mutex used: 268739652
a_count = 10000000, Atomic used: 114195449
count = 10000000, Mutex used: 271568003
a_count = 10000000, Atomic used: 114331315
count = 10000000, Mutex used: 271557151
a_count = 10000000, Atomic used: 112725464
可以看到Mutex大概是Atomic的接近3倍倍,符合预期,看过一个哥们2008写的测试,Mutex用时也是Atomic的3倍。
perf看下,结果如下:
Samples: 1K of event 'cycles', Event count (approx.): 1160274395
Children Self Command Shared Object Symbol ◆
+ 99.63% 0.00% a.out libc-2.12.so [.] __libc_start_main
+ 37.55% 5.42% a.out a.out [.] main
+ 35.14% 35.08% a.out libpthread-2.12.so [.] pthread_mutex_unlock
+ 32.72% 3.76% a.out a.out [.] std::atomic_fetch_add<int>
+ 28.14% 3.81% a.out a.out [.] std::atomic_fetch_add_explicit<int>
+ 25.39% 25.39% a.out libpthread-2.12.so [.] pthread_mutex_lock
+ 25.16% 25.16% a.out a.out [.] std::__atomic_base<int>::fetch_add
+ 1.01% 1.01% a.out a.out [.] pthread_mutex_lock@plt
+ 0.17% 0.00% a.out ld-2.12.so [.] _dl_sysdep_start
+ 0.17% 0.00% a.out ld-2.12.so [.] dl_main
+ 0.17% 0.00% a.out ld-2.12.so [.] _dl_relocate_object
+ 0.17% 0.17% a.out [kernel.vmlinux] [k] page_fault
+ 0.12% 0.00% a.out [kernel.vmlinux] [k] apic_timer_interrupt
+ 0.12% 0.00% a.out [kernel.vmlinux] [k] smp_apic_timer_interrupt
+ 0.09% 0.00% a.out [unknown] [k] 0x00000032b42acde7
+ 0.09% 0.00% a.out [kernel.vmlinux] [k] stub_execve
+ 0.09% 0.00% a.out [kernel.vmlinux] [k] sys_execve
+ 0.09% 0.00% a.out [kernel.vmlinux] [k] do_execve
+ 0.09% 0.00% a.out [kernel.vmlinux] [k] search_binary_handler
+ 0.09% 0.00% a.out [kernel.vmlinux] [k] load_elf_binary
+ 0.08% 0.00% a.out [kernel.vmlinux] [k] elf_map
+ 0.08% 0.00% a.out [kernel.vmlinux] [k] do_mmap_pgoff
+ 0.08% 0.00% a.out [kernel.vmlinux] [k] mmap_region
+ 0.08% 0.00% a.out [kernel.vmlinux] [k] perf_event_mmap
+ 0.08% 0.08% a.out [kernel.vmlinux] [k] kfree
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] hrtimer_interrupt
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] __run_hrtimer
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] tick_sched_timer
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] tick_do_update_jiffies64
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] do_timer
+ 0.06% 0.06% a.out [kernel.vmlinux] [k] update_wall_time
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] irq_exit
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] do_softirq
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] call_softirq
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] __do_softirq
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] rcu_process_callbacks
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] __rcu_process_callbacks
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] force_quiescent_state
+ 0.06% 0.00% a.out [kernel.vmlinux] [k] rcu_process_dyntick
+ 0.06% 0.06% a.out [kernel.vmlinux] [k] dyntick_save_progress_counter
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] setup_new_exec
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] set_task_comm
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] perf_event_comm
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] perf_event_context_sched_in
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] perf_pmu_enable
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] x86_pmu_enable
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] intel_pmu_enable_all
+ 0.00% 0.00% a.out [kernel.vmlinux] [k] native_write_msr_safe
主要就三项:
+ 35.14% 35.08% a.out libpthread-2.12.so [.] pthread_mutex_unlock
+ 32.72% 3.76% a.out a.out [.] std::atomic_fetch_add<int>
+ 25.39% 25.39% a.out libpthread-2.12.so [.] pthread_mutex_lock
可以看到pthread_mutex_lock和pthread_mutex_unlock加起来占总60%(unlock比lock多10%,why?),atomic_fetch_add占30%
最后,上火焰图:
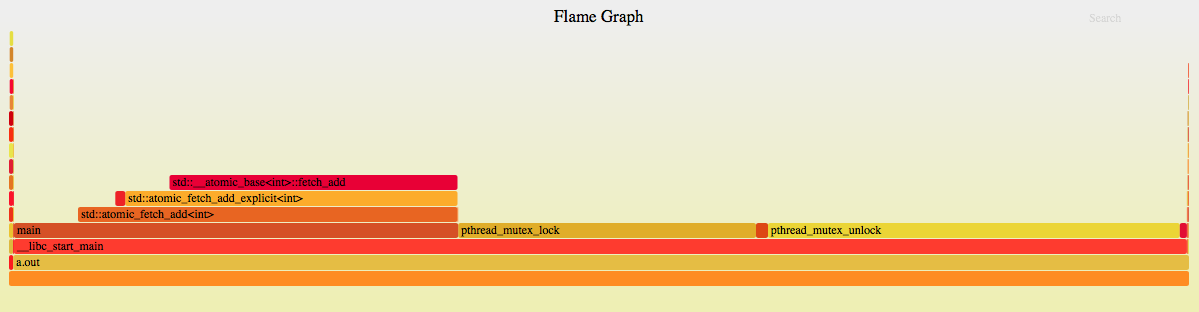
总结
测试结果过预期一样,现在有了量化的对比,以后在atomic和mutex都适用的情况下优先选atomic。
其实rocksdb就是将leveldb里Get()实现中一上来就mutex加锁的操作换成atmoic+线程私有存储的方式来进行优化,优化后读操作基本很少再会有互斥,性能提高不少,