As the “SQLite for OLAP,” DuckDB has been gaining significant popularity. At Hopsworks, we’ve also had many interesting discussions around its design and capabilities. Diving into the source code of such a star project is both exciting and insightful. This post marks the beginning of my DuckDB Source Dive series, where I will break down and explain the internals of DuckDB from a source code perspective.
For this first article, I’ll start with a deep dive into one of DuckDB’s components: the DatabaseManager class. This class handles how databases are organized, along with their schemas, tables, indexes, and other related resources. Understanding this part is essential because it’s often the first concept users encounter when working with DuckDB.
1. Core Concepts
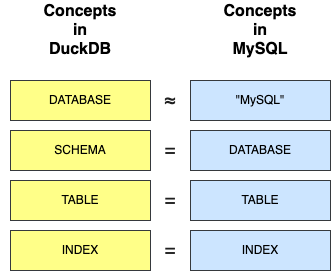
DuckDB organizes its data resources into a four-level hierarchy:
- Database: A single DuckDB instance can dynamically
ATTACHorDETACHdatabases at runtime, typically stored as.dbfiles. This concept doesn’t have a direct counterpart in MySQL. If we had to draw a comparison, one DuckDB database is ”roughly equivalent“ to a MySQL instance. - Schema: Each database contains multiple schemas, which can be created or dropped via
CREATE/DROP SCHEMA. This is conceptually equivalent to a MySQL database. A schema holds tables, indexes, and other resources. - Table: Each schema can contain multiple tables, which are created or dropped with
CREATE/DROP TABLE. This maps directly to MySQL tables. - Index: Tables can have multiple indexes, defined with
CREATE/DROP INDEX. These are equivalent to indexes in MySQL.
Here’s a diagram that illustrates how these concepts align between DuckDB and MySQL:
2. Code Breakdown
DuckDB’s codebase is well-structured, but it heavily uses inheritance, encapsulation, and templates, which can make it challenging to follow initially. However, once you understand the key classes and how they relate to each other, the overall design becomes much clearer.
Let’s walk through a concrete example. Suppose we have a DuckDB database file zhao.db, with a default schema (main) containing the following table:
CREATE TABLE tbl (
col_a INTEGER,
col_b INTEGER,
col_c INTEGER,
col_d INTEGER,
PRIMARY KEY(col_a),
UNIQUE(col_b)
);
CREATE INDEX idx ON tbl(col_c);
This table, tbl, includes:
-
4 INTEGER columns:
col_a,col_b,col_c, andcol_d -
3 indexes: a primary key on
col_a, a unique constraint oncol_b, and a regular indexidxoncol_c
We now start the DuckDB shell and load the file:
duckdb ./zhao.db
What happens under the hood? I’ll break it down into two main parts.
2.1 DatabaseManager
When DuckDB starts, it creates a DuckDB object and loads the zhao.db file. Skipping over unrelated details, it reads metadata from the file and deserializes it into in-memory structures representing all database resources.
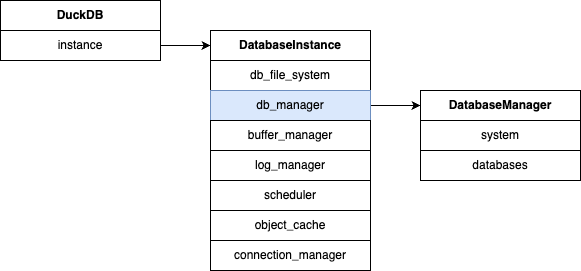
The DuckDB class has a member called instance, which is a pointer to a DatabaseInstance object — the core object representing the DuckDB instance. It contains several key components, and for this article, we’ll focus on the db_manager field. This is the DatabaseManager object that manages all attached databases and their contents (schemas, tables, indexes, etc.). It is the core module for data resource management in DuckDB.
The DatabaseManager includes two major members:
- system: This is the system database, containing built-in function sets and other predefined resources. It’s rebuilt from scratch on each startup and is not persisted in
.dbfiles. - databases: A collection of user-attached databases. Every time a user executes an ATTACH, the corresponding Database object is added to this collection.
Here’s an expanded diagram that shows how this works:
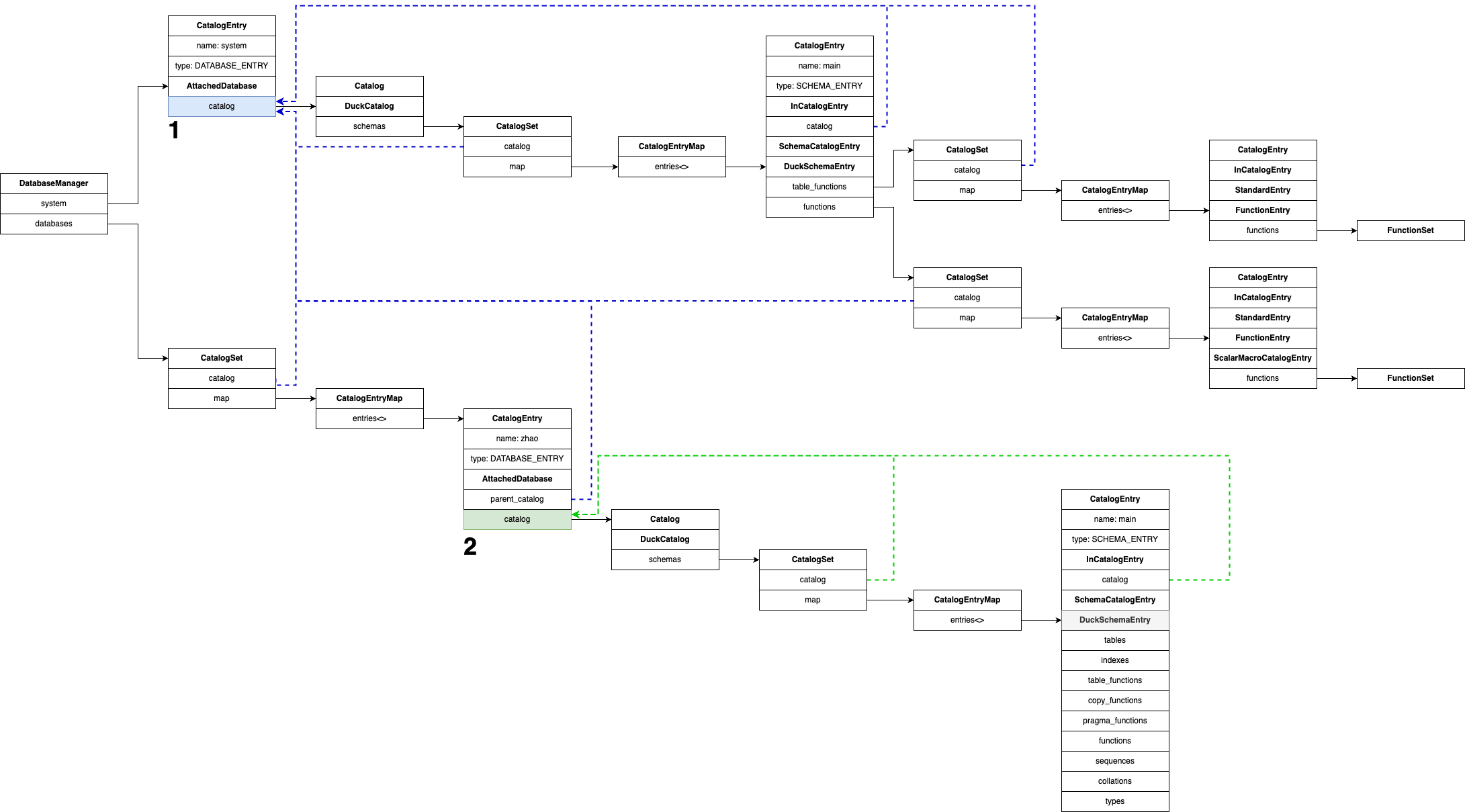
Key classes and concepts:
- Catalog: Represents the collection of resources in a database. Each database has a corresponding Catalog object. Its main job is to manage schemas.
- CatalogSet: Stores various catalog entries like schemas, tables, etc. Internally, it holds a map (of type CatalogEntryMap) which contains all entries.
- CatalogEntry: The base class for all catalog items (schemas, tables, indexes, etc.). For example, DuckSchemaEntry represents a schema and inherits from CatalogEntry.
- AttachedDatabase: Represents an attached database. Although it’s a top-level concept, it also inherits from CatalogEntry`and fits into the catalog structure.
To summarize:
- system points to an AttachedDatabase representing the system catalog, with a DuckCatalog holding its schemas. Within that is a CatalogSet of schemas, one of which is main. This schema holds built-in functions stored as FunctionEntry objects.
- databases is a CatalogSet containing user databases. Each AttachedDatabase contains its own catalog of schemas, each a DuckSchemaEntry. These, in turn, contain CatalogSets for tables, indexes, functions, types, sequences, etc., all stored as CatalogEntry-derived types like TableCatalogEntry or IndexCatalogEntry.
We’ve covered the high-level organization of databases and schemas. Next, let’s zoom into DuckSchemaEntry and explore the schema’s internal implementation.
2.2 DuckSchemaEntry
DuckSchemaEntry is a central class that represents a schema and contains all associated resources. As shown earlier, it holds tables, indexes, and more.
This object is constructed during startup, when CheckpointReader::LoadCheckpoint() is invoked. This function reads the .db file’s meta blocks and deserializes them into various catalog entries, including schemas, tables, indexes, and functions.
Here’s a rough pseudocode outline:
CheckpointReader::LoadCheckpoint():
1. Read metadata from the .db file
2. Deserialize by TYPE:
switch (TYPE) {
case SCHEMA_ENTRY:
Create DuckSchemaEntry;
break;
case TYPE_ENTRY:
Create DuckTableEntry;
break;
case INDEX_ENTRY:
Create DuckIndexEntry;
break;
case VIEW_ENTRY:
Create DuckViewEntry;
break;
case MACRO_ENTRY:
Create ScalarMacroCatalogEntry;
break;
case TABLE_MACRO_ENTRY:
Create TableMacroCatalogEntry;
break;
case TYPE_ENTRY:
Create TypeCatalogEntry;
break;
case SEQUENCE_ENTRY:
Create SequenceCatalogEntry;
break;
}
DuckSchemaEntry is the top-level catalog entry for a schema. All other entries — tables, views, macros, sequences — are nested under it.
Here’s the deserialization flow:
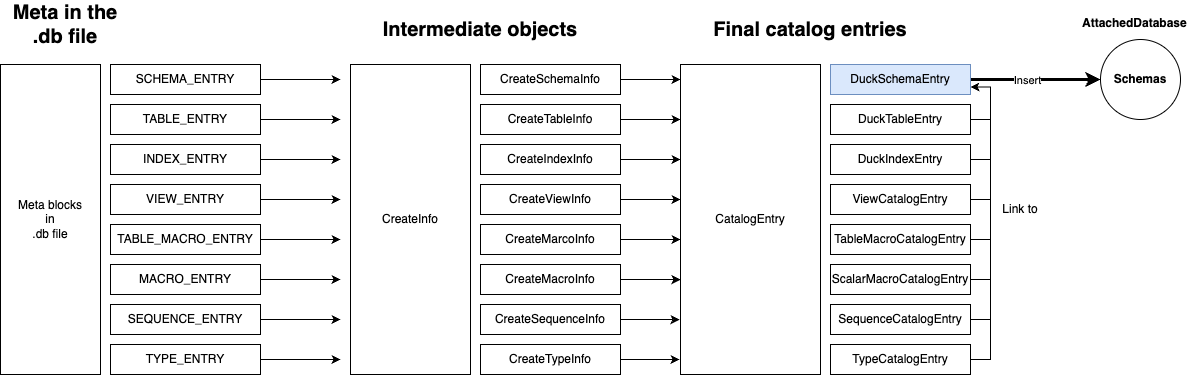
- Read an entry from the file and deserialize it.
- Based on its type, convert it into a CreateInfo structure.
- Use that CreateInfo to construct the corresponding CatalogEntry.
- Depending on the entry type:
- If it’s a schema, insert it into the schemas map of AttachedDatabase.
- Otherwise (tables, indexes, etc.), locate the target schema and add it there.
This next figure gives a detailed view of DuckSchemaEntry’s internals and how child entries are managed:
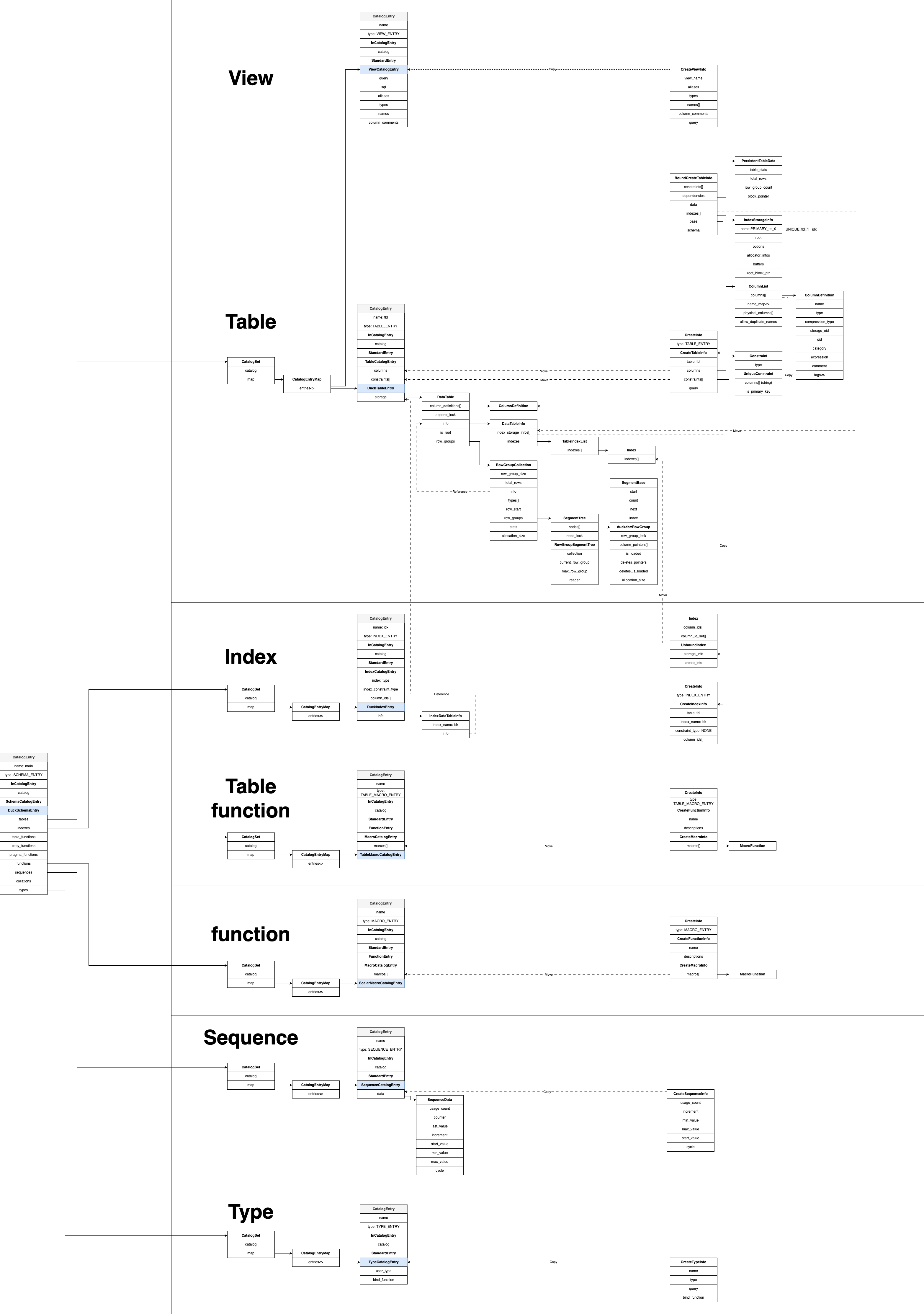
This diagram will greatly clarify the structure as we read the code. I won’t go over every part in detail here — instead, I’ll highlight some important elements:
- DuckTableEntry holds detailed information like columns, indexes, and data blocks. Stored under the schema’s tables set.
- DuckViewEntry also lives in the tables set, alongside regular tables.
- DuckIndexEntry represents an index, but note: the actual index data is stored inside the storage of the corresponding DuckTableEntry, and DuckIndexEntry merely references it.
- Not all indexes are defined via INDEX_ENTRY. Primary and unique indexes are created during TABLE_ENTRY parsing, based on constraints. Only regular indexes (like
idxin our example) are created from INDEX_ENTRY. - Functions, table functions, sequences, and types are all schema-level resources. They are created using statements like
CREATE MACRO/FUNCTION,CREATE MACRO ... AS TABLE,CREATE SEQUENCE, andCREATE TYPE. Just like tables, indexes, and views, the metadata for these resources is also persisted in the.dbfile.
In future posts, I plan to explore how DuckDB implements columnar storage, the ART index, and its transaction — possibly with comparisons to MySQL. It would be fun.