MySQL 8.0 introduced instant add column and instant drop column operations, allowing multiple data formats to exist within the same table. This added complexity makes developing external tools for record-level parsing and analysis of MySQL .ibd files more complex compared to versions 5.6 and 5.7. Additionally, MySQL Server lacks robust mechanisms for detailed table usage statistics, such as accurately determining the total size and proportion of valid data in a specific index or the total size of dropped columns hidden within a primary index.
Taking advantage of the Christmas holiday, I developed ibdNinja, a C++ tool for multidimensional and fine-grained analysis of .ibd files. I hope it aids MySQL enthusiasts in understanding internals better and provides DBAs with advanced statistical insights.
Github: ibdNinja
Contents
1. Key Features of ibdNinja
2. Examples of ibdNinja Usage
3. Highlight: Parsing Records with Instant Add/Drop Columns
4. Limitations
1. Key Features of ibdNinja
1. Parsing SDI Metadata
Extracts and analyzes the dictionary information of all tables and indexes contained in an ibd file from its SDI (Serialized Dictionary Information).
2. Dynamic Parsing of Records Across Multiple Table Definition Versions *
With the parsed dictionary information, ibdNinja supports parsing and printing any record from any page of any index* in any table* (supporting all column types).
Moreover, it can dynamically adapt to parse records in tables with multiple coexisting schema versions caused by repeated instant add column and instant drop column operations.
Detailed explanations and examples are provided in Section 3
3. Multi-Dimensional Data Analysis
Powered by its record parsing capabilities, ibdNinja enables comprehensive data analysis across multiple levels, including Record, Page, Index, and Table levels. It computes and presents multi-dimensional statistics:
Record Level:
- Total size of the record (header + body), the number of fields, and whether the record contains a deleted mark.
- Hexadecimal content of the header.
- Detailed information for each field (including user-defined columns, system columns, and instant added/dropped columns), such as:
- Field name
- Field size in bytes
- Field type
- Hexadecimal content of the field value
Page Level:
- The number of valid records, their total size, and the percentage of page space they occupy.
- The count of records containing
instant dropped columnsand the size and page space percentage of these dropped but still allocated columns. - The count, total size, and page space percentage of records marked as deleted.
- The space utilized internally by InnoDB (e.g., page header, record headers, page directory), along with its percentage of the page.
- The size and percentage of free space within the page.
Index Level:
- For a specific index, analyzes and aggregates statistics for all its pages starting from the root page.
- Statistics are presented separately for non-leaf levels and leaf levels, similar to the statistics provided at the page level.
Table Level:
- For a given table, starts from its primary index and analyzes each index to display its statistics
4. Printing Leftmost Pages of Each Index Level:
Allows users to print the leftmost page number of each level for a specified index, making it easier to manually traverse and print every record in the index page by page.
5. [TODO] Repairing Corrupted ibd Files
With ibdNinja’s capability to parse records, it is possible to address ibd files with corrupted index pages. By removing damaged records from pages or excluding corrupted pages from indexes, the tool can attempt to recover the file to the greatest extent possible.
2. Examples of ibdNinja Usage
Compiling is straightforward—just run make in the current directory.
1. Display Help Information (--help, -h)
2. List Tables and Indexes in the ibd File (--list-tables, -l)
Using the system tablespace file mysql.ibd as an example, after specifying the file with the --file or -f option, the output provides:
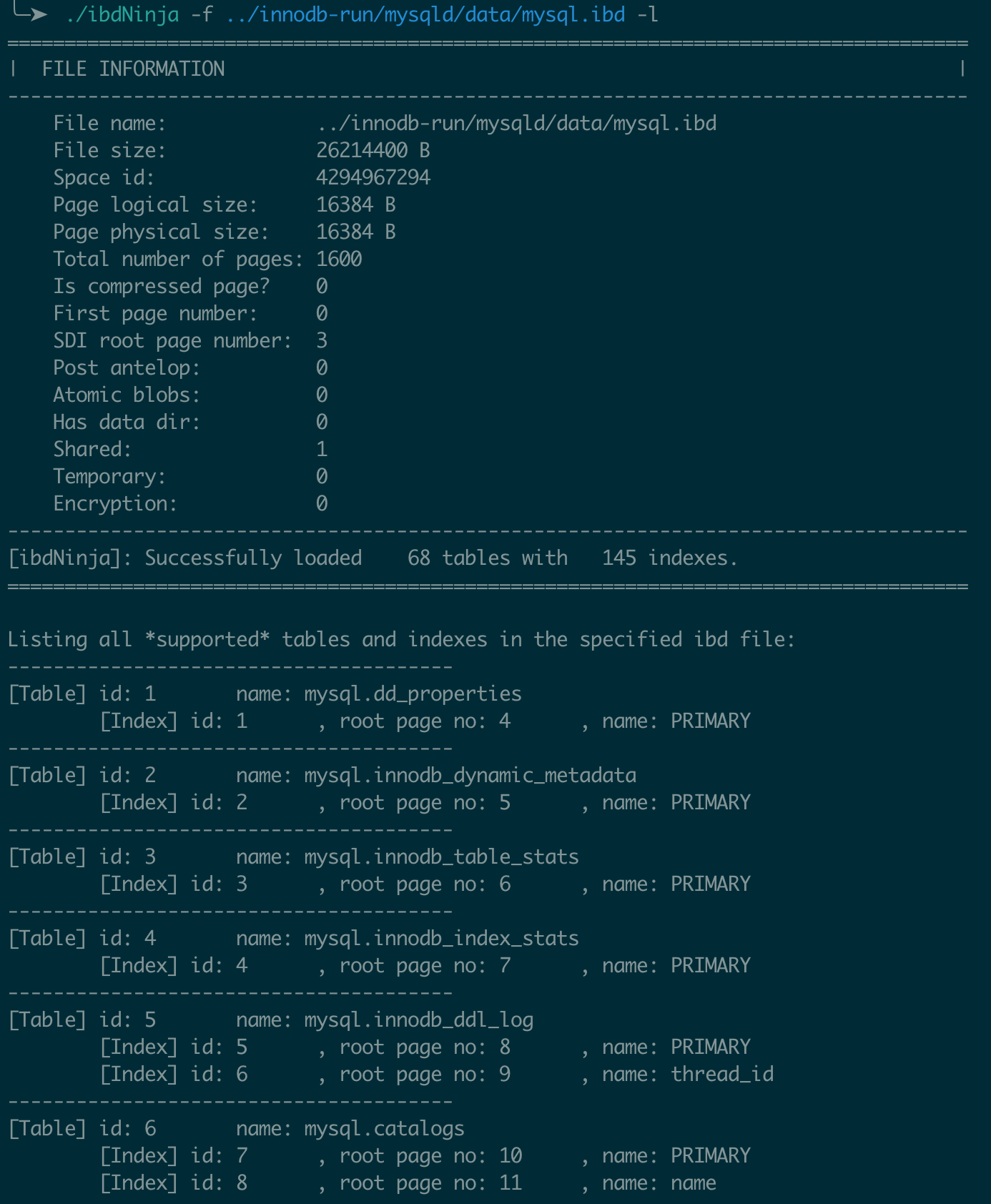
- A summary of the ibd file, including the number of tables and indexes successfully parsed and loaded from the data dictionary.
- The table IDs and names of all tables in the file.
- For each table, all index IDs, root page numbers, and index names.
With this information, you can explore the ibd file further using other commands.
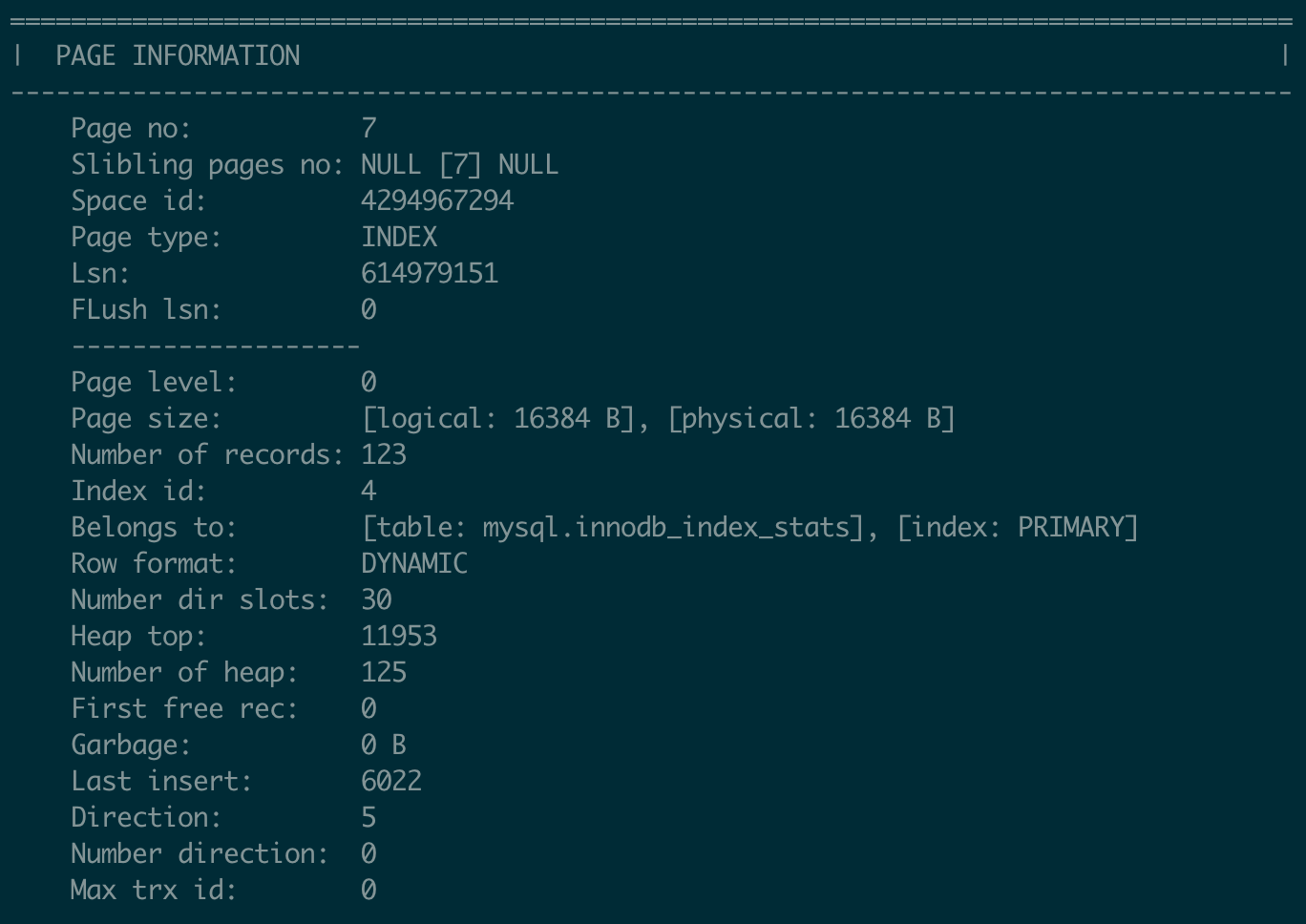
3. Parse and Print a Specific Page (--parse-page, -p PAGE_ID)
Continuing with mysql.ibd as an example, let’s parse the root page of the PRIMARY index for the mysql.innodb_index_stats table (its root page number is 7, as shown in the previous example).
Run the following command:
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -p 7
The output consists of three parts:
- Page Summary: Information such as sibling page numbers (left and right), the index the page belongs to, the page level, etc.
- Record Details: For each record in the page, details like:
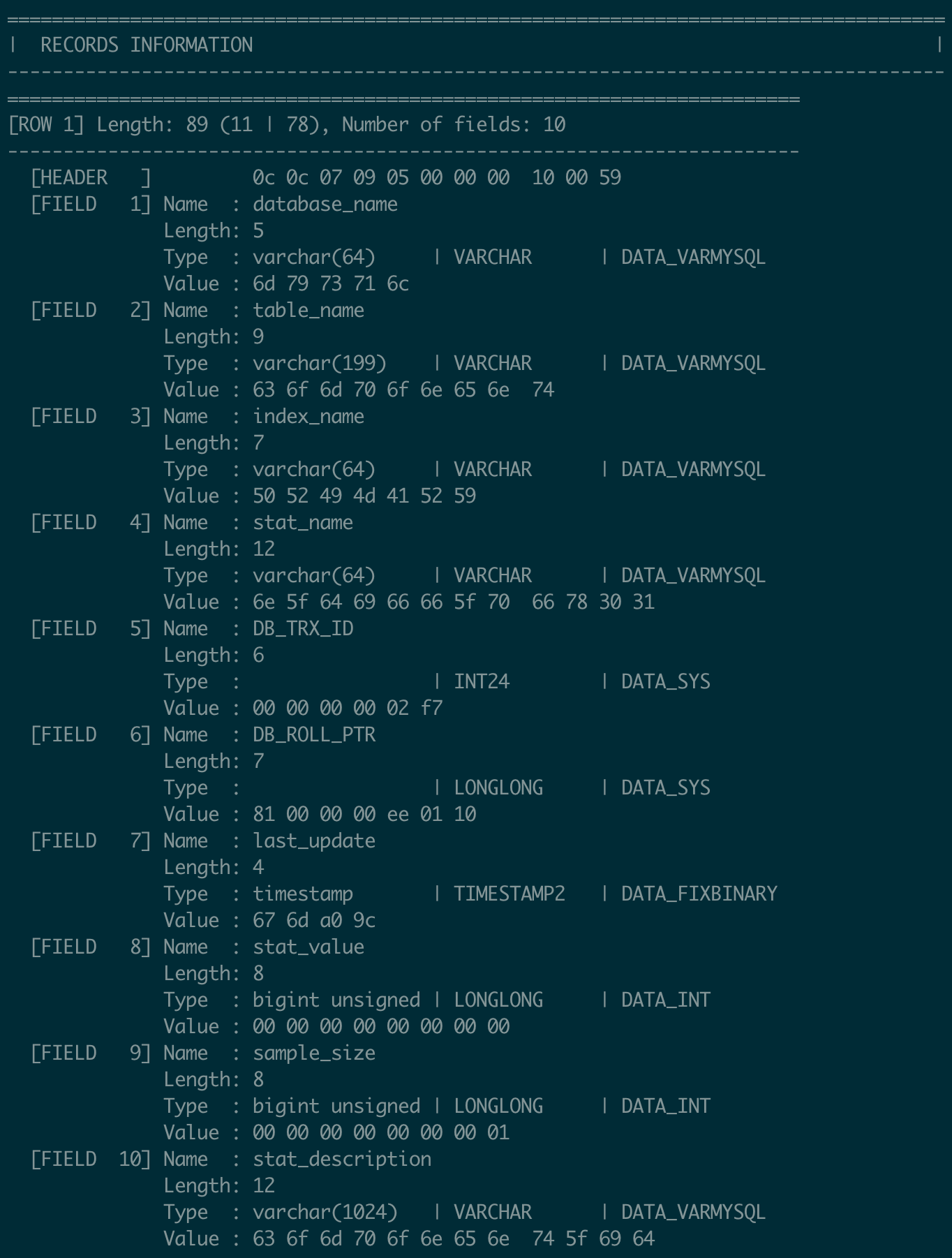
- Total length of the record (header + body), field count, and whether it has a delete mark.
- A hexadecimal dump of the record header.
- Detailed information for each field (e.g., name, length, type, and the hexadecimal value).
3. Page Analysis Summary:
Includes statistics such as:
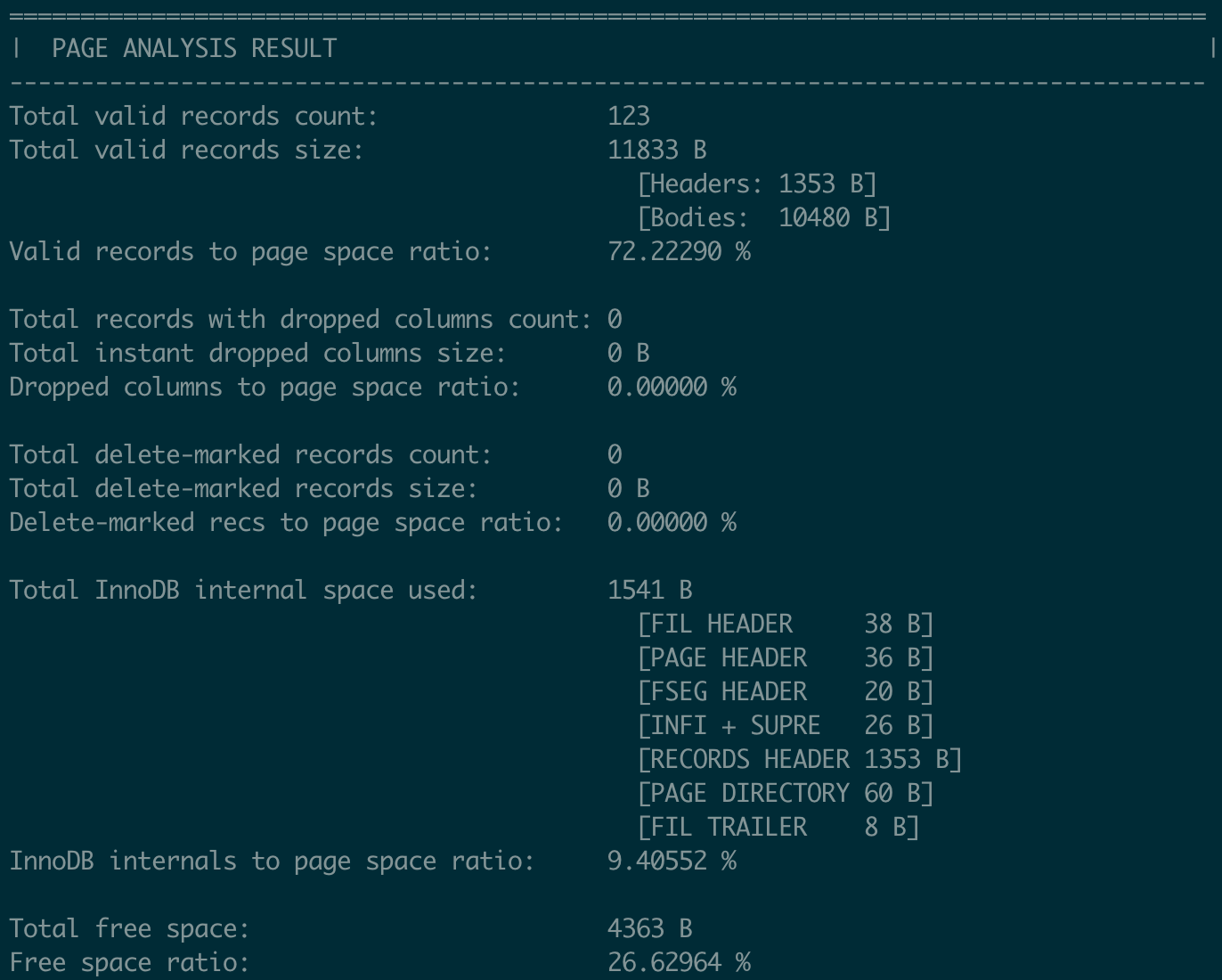
- Number, total size, and space usage percentage of valid records.
- Number and size of records with
instant dropped columns, as well as their space usage percentage. - Number and size of delete-marked records, and their space usage percentage.
- Space used by InnoDB internal components (e.g., page headers), along with their percentages.
- Free space size and percentage.
4. Analyze a Specific Index (--analyze-index, -i INDEX_ID)
Using mysql.ibd again, first obtain the table and index information using the --list-tables (-l) command.
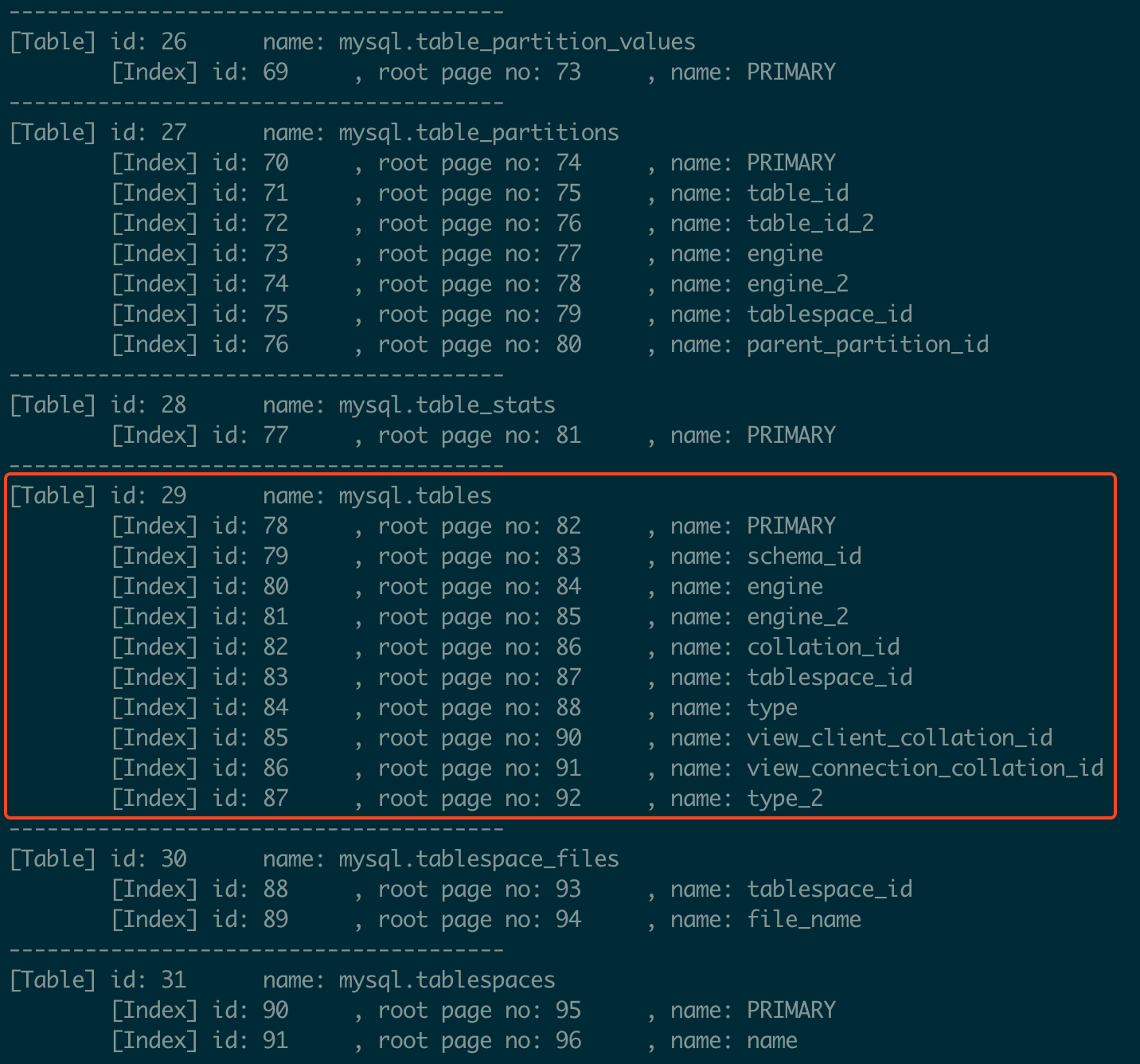
For example, the mysql.tables table has an ID of 29 and contains 10 indexes. To analyze the PRIMARY index (ID 78), run:
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -i 78
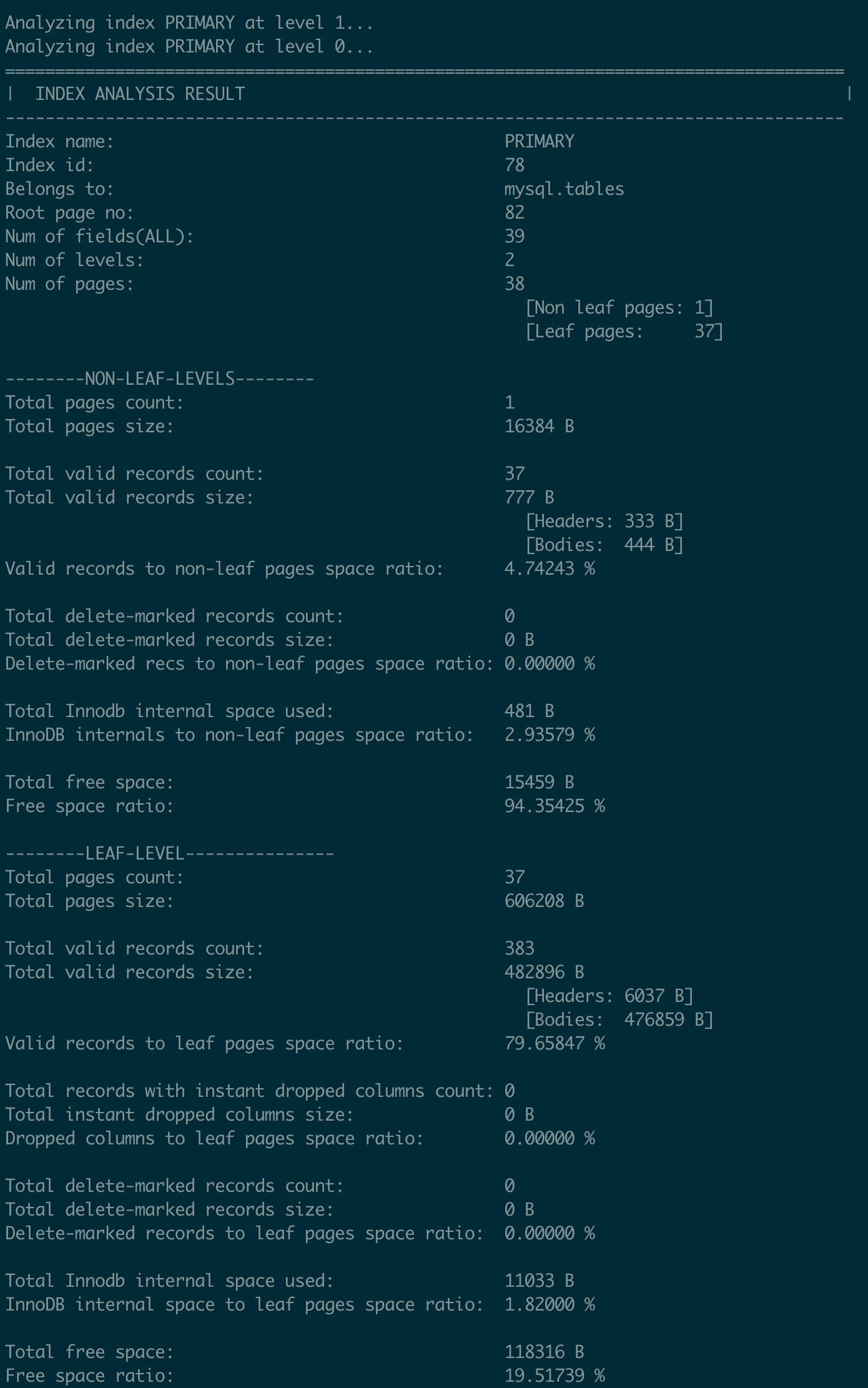
ibdNinja traverses the PRIMARY index from its root page, analyzing it level by level and page by page, then summarizes the statistics:
- Overview: Includes the index name, number of levels, and number of pages.
- Non-Leaf Levels Statistics: Provides page count, record count, and various space usage details.
- Leaf Level Statistics: Similar to the above, but specific to the leaf level.
5. Analyze a Specific Table (--analyze-table, -t TABLE_ID)
Using mysql.ibd again, first run the --list-tables (-l) command to get table and index information.
For the mysql.tables table with an ID of 29, execute:
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -t 29
This command analyzes all 10 indexes of the mysql.tables table and outputs their statistics. Each index’s structure is similar to the output of --analyze-index.
6. List the Leftmost Page Number for Each Level of an Index (--list-leafmost-pages, -e INDEX_ID)
Continuing with the mysql.ibd example, the PRIMARY index of the mysql.tables table has an ID of 78.
Run the following command:
./ibdNinja -f ../innodb-run/mysqld/data/mysql.ibd -e 78

The output shows the leftmost page number for each level of the index. For example:
- Level 1 (non-leaf) has a leftmost page number of 82.
- Level 0 (leaf level) has a leftmost page number of 161.
You can then use the --parse-page (-p PAGE_NO) command to print detailed information for these pages. From the sibling page numbers, you can continue parsing the left and right pages to traverse the entire index.
Note: To skip printing record details for a page (e.g., to avoid excessive output), use the --no-print-record (-n) option along with -p, as in:-p 161 -n
3. Highlight: Parsing Records with Instant Add/Drop Columns
Table Setup
We start by creating a table:
CREATE TABLE `ninja_tbl` (
`col_uint` int unsigned NOT NULL,
`col_datetime_0` datetime DEFAULT NULL,
`col_varchar` varchar(10) DEFAULT NULL,
PRIMARY KEY (`col_uint`)
) ENGINE=InnoDB;
Based on the current table definition (V1), we insert one record:
INSERT INTO ninja_tbl values (1, NOW(), "Row_V1");
Next, we use ALTER TABLE to add two columns to the table:
ALTER TABLE ninja_tbl ADD COLUMN col_datetime_6 datetime(6);
ALTER TABLE ninja_tbl ADD COLUMN col_char char(10) DEFAULT "abc";
Based on the updated table definition (V2), we insert another record:
INSERT INTO ninja_tbl values (2, NOW(), "Row_V2", NOW(), "ibdNinja");
Then, we drop two columns from the table:
ALTER TABLE ninja_tbl DROP COLUMN col_varchar;
ALTER TABLE ninja_tbl DROP COLUMN col_char;
Finally, based on the updated table definition (V3), we insert a third record:
INSERT INTO ninja_tbl values (3, NOW(), NOW());
Parsing Records with ibdNinja
Through the operations above, we constructed three different table definitions (V1, V2, V3) and inserted one record for each version. Now, let’s use ibdNinja to parse these three records. Since there are only three records, the primary key index of ninja_tbl must fit into a single page (root number 4). We can directly use the -p command to parse this page. Here, we skip most of the output and focus on the parsed records:
-
Record 1:
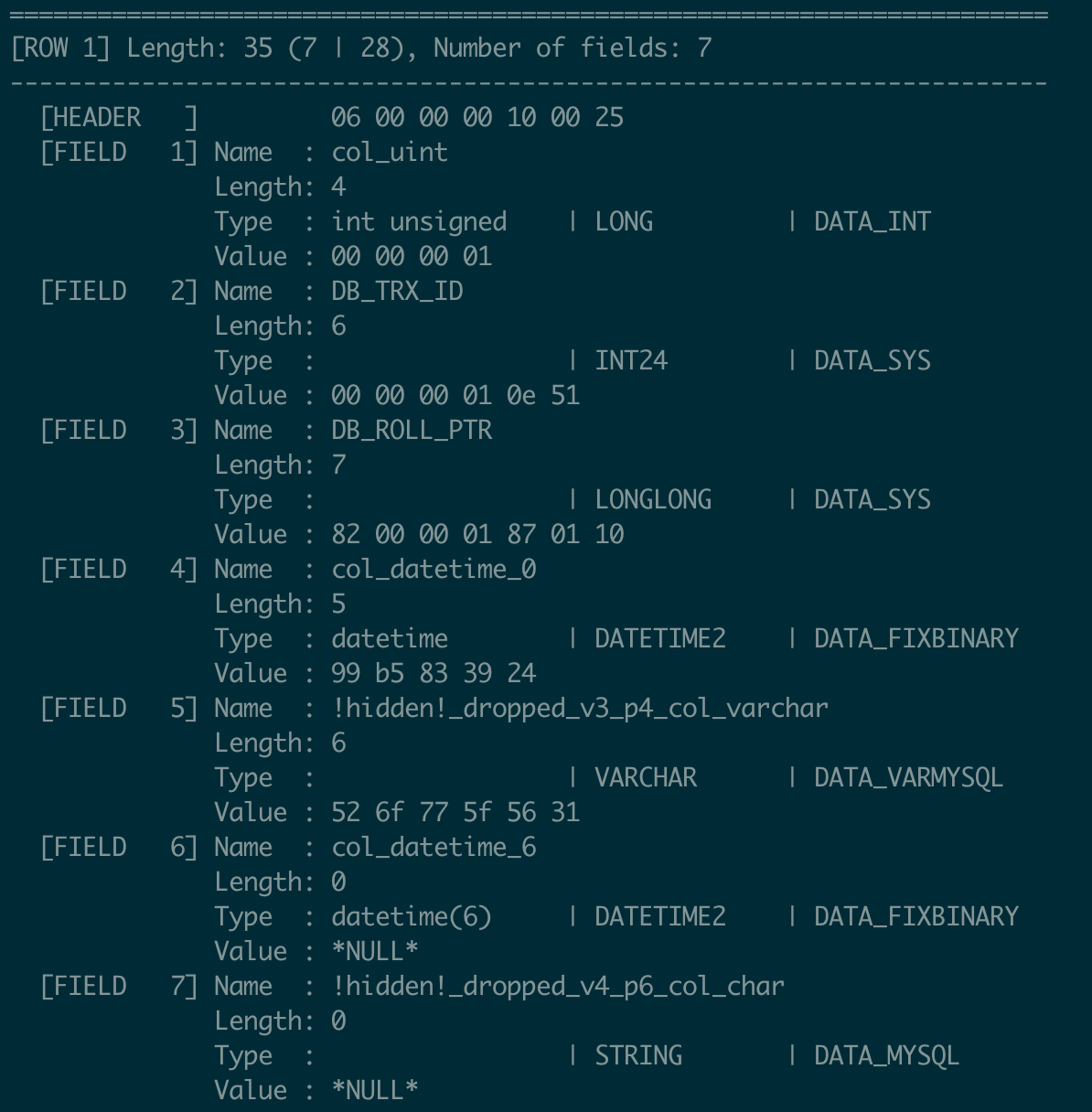
- FIELD 1 (col_uint): The value is
1, inserted under table definition V1. - FIELD 5 (col_varchar): This field was defined in V1 and is part of record 1. Its value is present but marked as
!hidden!_dropped_v3_p4_col_varcharbecause the column was instantly dropped in V3. Although hidden from queries, the data remains in the page. - FIELD 6 (col_datetime_6): Added in V2, this field has no value in record 1, as it did not exist when the record was inserted (length is 0).
- FIELD 7 (col_char): Also added in V2 and dropped in V3, this field has no value in record 1 for the same reason.
- FIELD 1 (col_uint): The value is
-
Record 2:
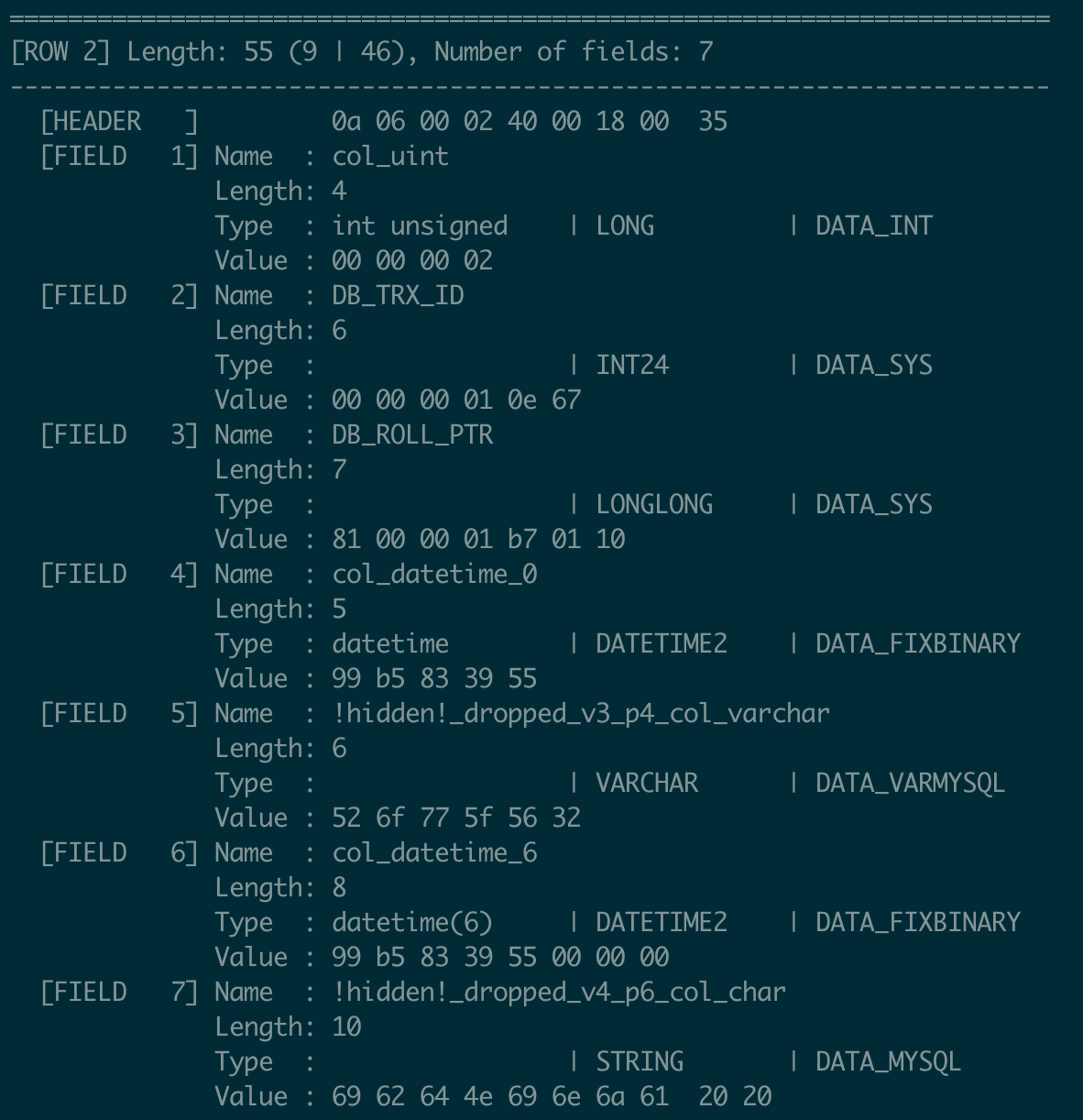
- FIELD 1 (col_uint): The value is
2, inserted under table definition V2. - FIELD 5 (col_varchar): This column was defined in V1 and dropped in V3. Since record 2 was inserted before the drop, it still contains a value.
- FIELD 6 (col_datetime_6): Added in V2, this field contains a value for record 2.
- FIELD 7 (col_char): Added in V2 and dropped in V3, this field also contains a value for record 2.
- FIELD 1 (col_uint): The value is
-
Record 3:
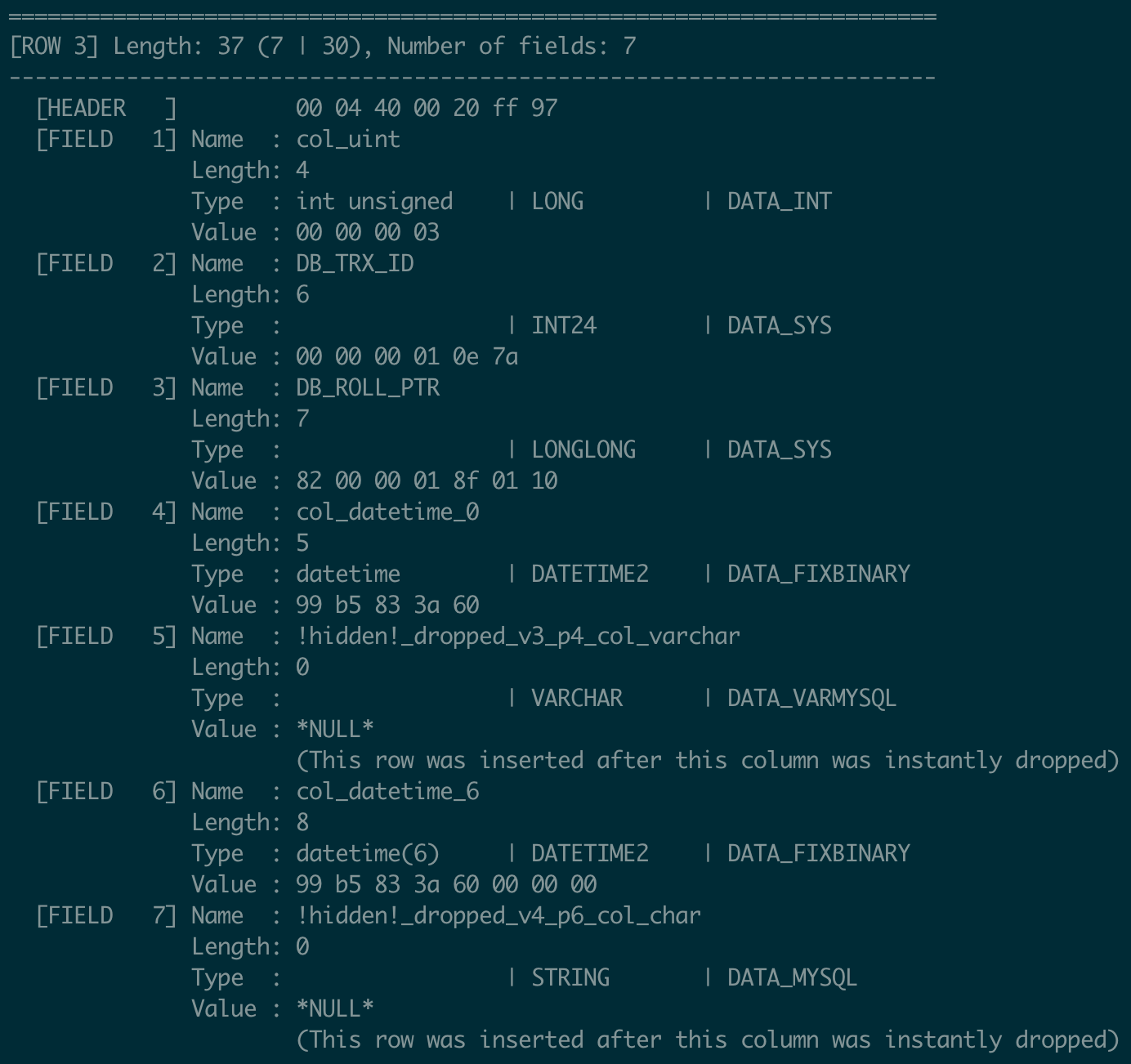
- FIELD 1 (col_uint): The value is
3, inserted under table definition V3. - FIELD 5 and FIELD 7: Both fields were dropped in V3. Since record 3 was inserted after the drop, these fields are empty.
- FIELD 1 (col_uint): The value is
Page Analysis Results
The page analysis output highlights the following key details:
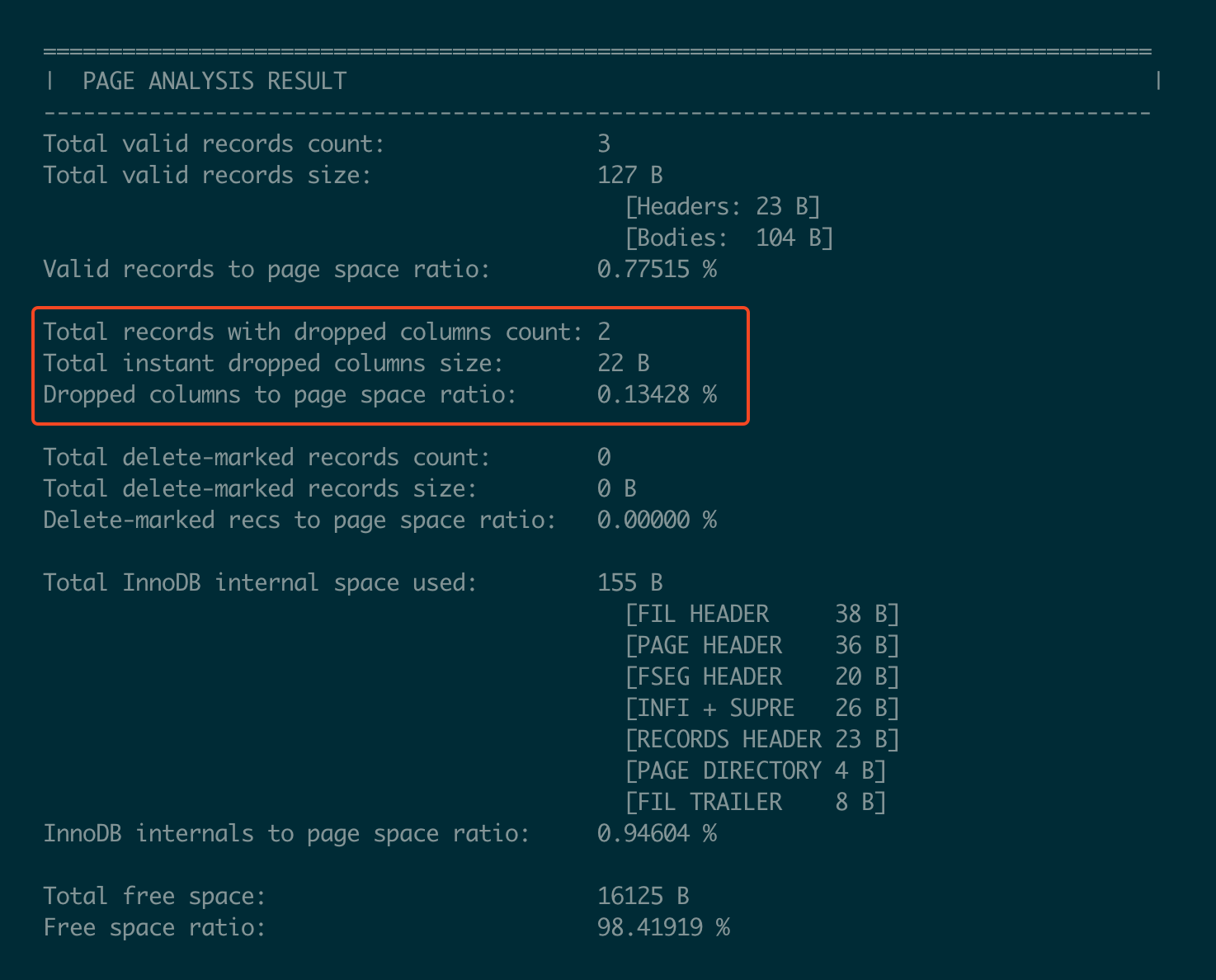
- As shown in the red box of the analysis, two records in the page still contain old values for columns that were dropped.
- The analysis shows the total size and percentage of space wasted due to these dropped columns.
This information helps to quantify the space overhead caused by instant column drops.
Similarly, if the page contains deleted-marked records, their size and percentage are also displayed.
These statistics are not only available at the page level but can also be aggregated at the index level using the --analyze-index (-i INDEX_ID) command.
4. Limitations
This is the first version I developed during the Christmas holiday, so there are some functional limitations and potential bugs (feel free to raise issues):
-
Supported MySQL Versions:
Currently supports MySQL 8.0 (8.0.16 - 8.0.40).
(Earlier versions of MySQL 8.0, prior to 8.0.16, contain a bug in SDI generation that leads to missing metadata in
dd_object::indexes::elements.) -
Supported Platforms:
Currently supports Linux and macOS.
(I don’t have Windows.)
-
Functional Limitations:
Tablespace:
- Encrypted tablespaces are not yet supported.
Table:
- Tables using table compression or page compression are not yet supported.
- Encrypted tables are not yet supported.
- Partition tables are not yet supported.
- Auxiliary and common index tables of FTS are not yet supported.
Index:
- Full-text indexes are not yet supported (only
FTS_DOC_ID_INDEXis supported). - Spatial indexes are not yet supported.
- Indexes using virtual columns as key columns are not yet supported.
Page:
- Only
INDEXpages (those in B+Tree) are currently supported.
Record:
- Records in the
redundantrow format are not yet supported.
Note: The analysis in ibdNinja is currently based on the InnoDB data pages written to the ibd file. Pages in the redo log that have not yet been flushed to the ibd file are not included in the statistics. In scenarios with a large number of dirty pages, the analysis results may have some deviations or errors.
Special thanks to MySQL for being an invaluable reference in developing ibdNinja.