对Embeddable data storage engines比较感兴趣,之前也只精读了leveldb,泛读了rocksdb的代码,这俩都是LSM Tree的实现,感觉还是有点窄,所以一直想找基于B+Tree实现的引擎看看,晦涩的lmdb给我看的半死,不爽,然后读了一个还在开发中的B+tree实现的引擎(传送门),实现比较清晰不过感觉这就是写着玩的没有生产环境的验证,还是不爽,所以找到了Kyoto Cabinet,在看treedb之前,发现它有基于hash实现的内存和文件的引擎,比较好奇所以先看了下kccachedb(基于内存)和kchashdb(基于文件),测了下性能还不错,这里简单总结一下
KCcachedb
这个就是基于内存hash,实现的和redis、mc差不多,这里就不展开介绍了,总结一下它的优缺点吧
优点:
- 支持多进程读、多线程安全
- ACID
- read uncommitted的隔离(不知道算优点还是缺点。。。)
- 支持很多接口,set、get、remove、
set_bulk、get_bulk、remove_bulk、add、cas、append、replace、increment、increment_double、copy、synchronize、dump_snapshot
缺点:
- 内存管理没有mc做的好,感觉就没做什么内存管理
- bucket不能动态扩展,用LRU来做淘汰
KChashdb
介绍
这个是基于文件实现的hash,文件结构也不复杂,主要分为Header、FreeBlockPool、Buckets section、Records section,如下图所示
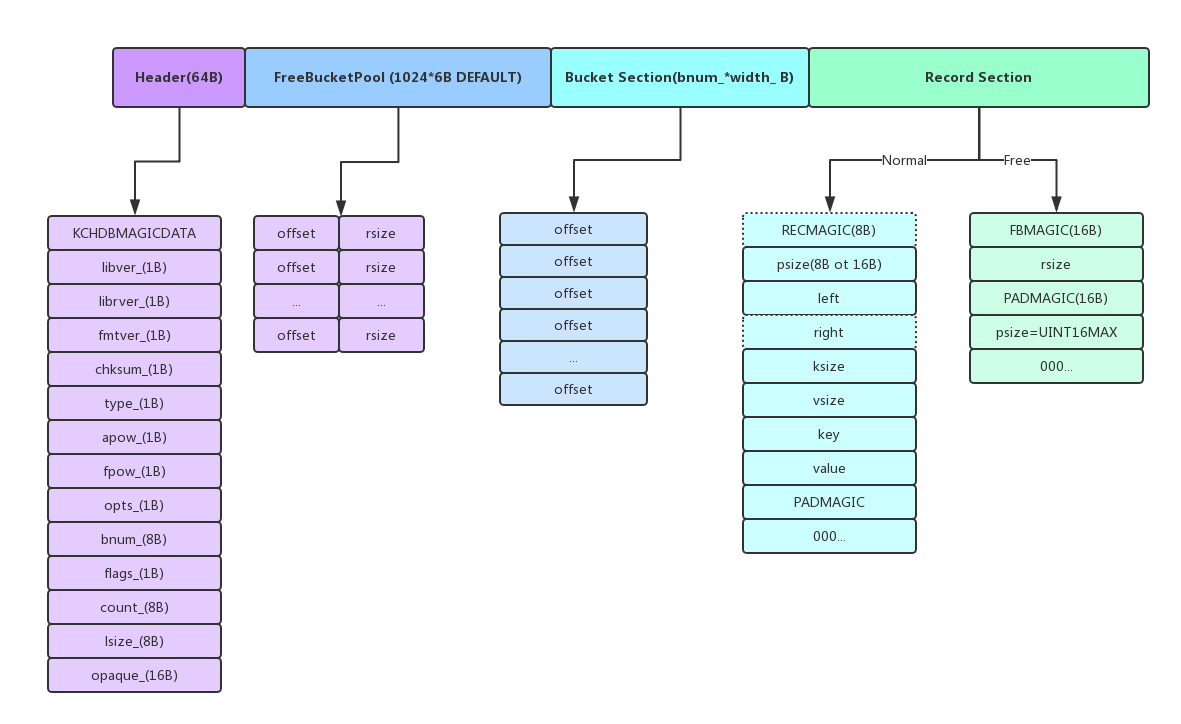
前三部分定长不会动态调整,
-
Header记录着一些元信息,如选项、bucket个数、checksum、flag等等
-
FreeBlockPool保存着可以被回收使用的record的offset和size,不过这些信息也存储在内存的std::set当中,在使用的时候只需要通过upper_bound来匹配出最合适的FreeBlock即可,在close或者synchronize时会将这些信息dump到文件FreeBlock,当以Writer身份打开文件的时候会把文件中FreeBlockPool的信息恢复到内存std::set中;注:如果程序没有调用close关闭或其他异常关闭,下次打开时会进organize_file,把修复的record写入到新的db文件中,老的FreeBlock直接抛弃。即使使用ONOREPAIR标志打开,也是直接抛弃老的FreeBlock
-
Bucket section是定长的bucket数组,每个元素大小首次可配,4B或者6B,里面存的是该bucket的top record地址,通过top record往下走就可以遍历同样hash值的record
-
Records section保存着一条条Record,每条Record都有一个header,其中psize是padding的大小,如果等于UINT16MAX则代表这个record是被删掉了,left和right是在发生碰撞之后接着查找用的,这里处理普通的链式之外,也可以支持二分查找树以加快查找速度
特点
- kchashdb通过mmap的方式打开文件,小于msize偏移的内容可以直接通过memcpy来读写,大于的这只能通过pread和pwrite来读写,msize默认64M,如果db很大但msize配置很小则每次操作会进行多次磁盘读写,性能会有所下降
- 对于overwrite的问题,如果oldrecord的size大于newrecord,则直接overwrite就可以,多余的部分加入到FreeBlockPool当中,如果oldrecord的size小于new record直接将oldrecord回收到FreeBlockPool中,new record的插入位置则从FreeBlockPool当中匹配最佳,有则用没有则插入到文件末尾。kchashdb通过apow来尽可能解决overwrite的shiftrecord的问题,如果db操作中有很多overwrite,则可以通过首次配置apow选项,默认是3,也就是8字节对齐,一条record的多余部分会填充上padding,这样实际record占用会大一些,当对此record进行overwrite时,有padding来进行一波缓冲尽可能减少由于size不够用而shiftrecord的几率
- kchashdb可以动态合并文件碎片,当overwrite或remove操作一定次数后,会触发从上次偏移量开始向后的碎片合并,具体做法就是shift有效的record,将碎片合并在一起,合并一定数目或扫描一定步长后停止
- kchashdb要求必须显式调用close来关闭db,每次open时会在header标记db已打开,如果程序异常退出,下次打开发现标记还是已打开或FATAL的时候则认为文件有损坏的风险,默认进行reorganize_file来重新整理db,具体做法就是从Record section当中遍历所有,将其写到tmp文件然后在改名,如果db特别大的话会很耗时,不过可以在open是通过ONOREPAIR来直接打开跳过修复
- Bucket个数在首次打开时配置,后期不可调整,所以不能做类似内存hash的扩容操作,这个是不灵活的点,不过对于文件hash似乎没有什么好的办法来支持bucket扩展,所以需要在使用前评估db大小来确定bucket的个数,官方推荐是records number的1~4倍,假设有100亿,每个最大占6B,则bucket section上来就要占55G的空间,而为了提高访问速度,header,FreeBlockPool,Buckets Section是需要放在内存的,那么这就需要mmap的大小比较大了,至少55G,这还只是在1倍的情况下
- FreeBlockPool定长,默认1024,也就是说最多存1024个回收块,如果满了则淘汰一个再插入,这会导致淘汰的回收块不能再被使用,直到碎片整理或文件修复时才合并清除
- 冲突解决可以使用二分查找树,不过这样会使每个record的header占用多4到6个字节(right),这样可以解决在冲突较多时查找的效率,不过推荐还是初始设置合理的bucket个数然后使用linear的方式解决冲突以达到空间和时间的最优
- 支持事务,可以在open时通过打开OAUTOTRAN选项来是的每一个操作自动是事务,也可以通过
begin_transaction、end_transaction来显式事务。undolog这里实现的比较简洁,每次操作最多会更新文件的5个地方(Header、oldrecord、buckets section、FreeBlockPool、newrecord),所以undolog第一条一定是备份Header,然后修改文件哪个块(offset、size)之前就将之前块的内容写进log中,然后再真正更新文件内容,如果出错或者abort_transaction,则执行applywal来回滚,事务提交或回滚后truncate unlog,隔离级别是read uncommitted、kc封装了write_fast,read_fast来确保在msize以内的用memcpy、以外的用pwrite、pread - 可以配置压缩,大于1K会压缩
-
可以根据数据的重要性来配置sync策略:
-
default risk on process crash: Some records may be missing. risk on system crash: Some records may be missing. performance penalty: none remark: Auto recovery after crash will take time in proportion of the database size.
-
transaction implicit usage: open(…, BasicDB::OAUTOTRAN); explicit usage: begin_transaction(false); …; end_transaction(true); risk on process crash: none risk on system crash: Some records may be missing. performance penalty: Throughput will be down to about 30% or less.
-
transaction + synchronize implicit usage: open(…, BasicDB::OAUTOTRAN | BasicDB::OAUTOSYNC); explicit usage: begin_transaction(true); …; end_transaction(true); risk on process crash: none risk on system crash: none performance penalty: Throughput will be down to about 1% or less.
-
-
为了达到性能的最优,需要对参数进行调整,我简单测了一下不同的参数对性能的影响,同样是写1000w条record,每条差不多30B,如下:
- 单线程,默认配置(64M msize、100w bucket):59.116s
- 4线程,默认配置(64M mszie、100w bucket):47.185s
- 单线程,调整bucket(64M msize、2000w bucket):49.579s
- 4线程,调整bucket(64M msize、2000w bucket):46.715s
- 单线程,调整mszie(8G msize、2000w bucket):12.312s
- 4线程,调整msize(8G msize、2000w bucket):11.873s
可以看到msize越大越好,bucket越多越好,不过即使用默认配置,性能也还说得过去
- iterator支持挂回调,这个不错,不过也有hash的通病就是不能有序迭代还有就是不能像leveldb那样基于某个快照来进行迭代,另外每一步迭代都是全局独占写锁阻塞其他操作
- 备份:如果确保没有写请求可以直接cp文件来备份,或者使用copy命令来备份。也可以使用dump_snapshot来备份,他会阻住一切请求.如果不想阻住请他请求则可以通过synchronize命令,传一个外部备份脚本来备份。总之kc的备份做的有些繁琐,远不如rocksdb的checkpoint的好
总结
个人感觉kchashdb比较适合用在update、delete操作比较少的场景,因为他的块回收和碎片整理稍微有一些跟不上。总体还好,可以一用^^