1. How It’s implemented
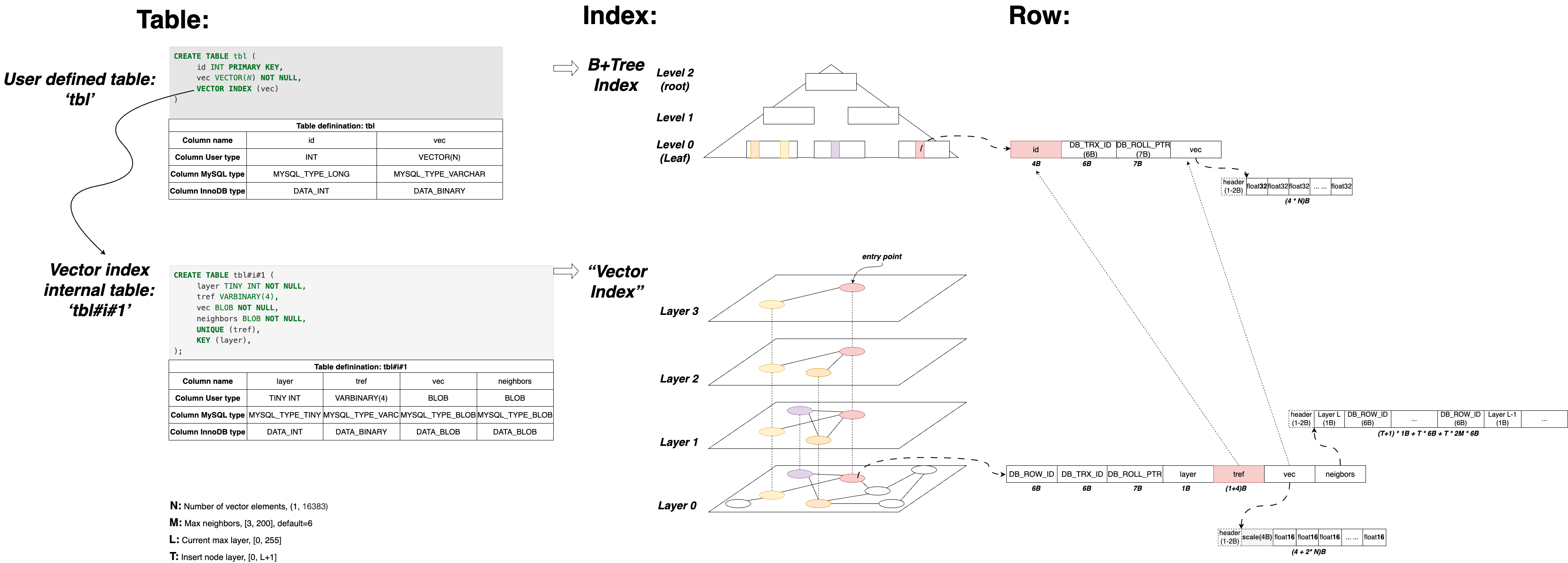
MariaDB’s vector index is implemented at the server layer, not at the storage engine. InnoDB doesn’t know vector indexes exist. Each vector index is backed by an internal table, making this effectively a “vector index on a B+Tree.”
💬 Internal Table Design:
- Created when a vector index is defined.
- Named as ‘user_table_name’#i#’vector_column_position’.
- No primary key, uses InnoDB’s DB_ROW_ID as the implicit PK.
- Each node is stored as a row:
- layer: node layer (indexed).
- tref: user table’s PK, used for fast cross-reference (UNIQUE KEY).
- vec: halfvec (header + N * float16), derived from user vector (N * float32) via normalization and quantization.
- neighbors: neighbor list by layer, each neighbor stored as its DB_ROW_ID.
2. Insertion Flow and Cost
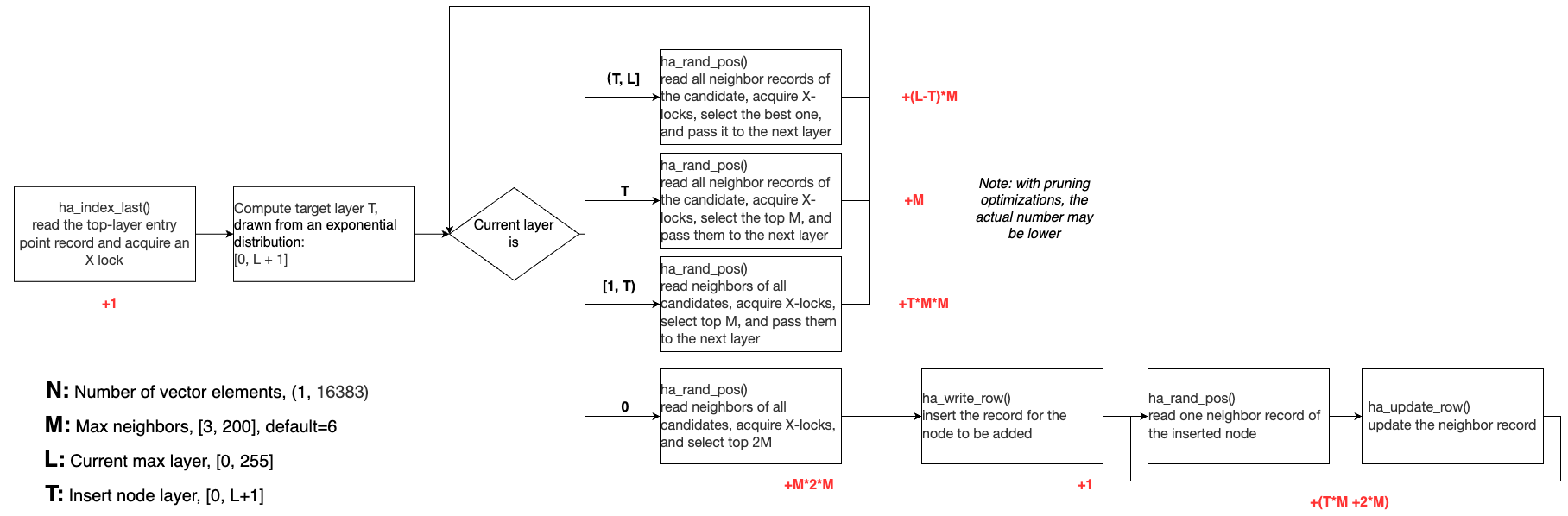
Inserting a record into a vector index involves multiple InnoDB API calls and lock acquisitions:
- ha_index_last() locates and X-locks the top-layer entry point.
- From layer L to T+1, ha_rnd_pos() reads neighbors and picks the best to descend.
- At layer T, ha_rnd_pos() selects top M candidates.
- From T-1 to 1, ha_rnd_pos() expands M candidates’ neighbors, keeping the top M.
- At layer 0, ha_rnd_pos() expands and picks top 2*M.
- ha_write_row() inserts the new node.
- ha_rnd_pos() reads selected neighbors for back-link updates.
- ha_update_row() updates neighbor lists.
👉 Max InnoDB Call Counts:
-
ha_index_last(): 1
-
ha_rnd_pos(): ((L - T) * M + M + T * M * M + M * 2M) + (T * M + 2M)
-
ha_write_row(): 1
-
ha_update_row(): T * M + 2M
(Pruning may reduce actual calls in step 3 - 5)
👉 Locking Cost:
- All calls acquire X-locks, including on unused nodes. Locks are held until transaction commit.
- The top-layer entry node becomes a write hotspot, every insert starts by X-locking this record—resulting in almost no write-write concurrency.
- Reads use snapshot reads and don’t acquire locks, so read concurrency is not impacted by locking—only by the number of InnoDB calls. I remember Mark did a detailed benchmark on this—worth checking out if you’re interested.
3. Review
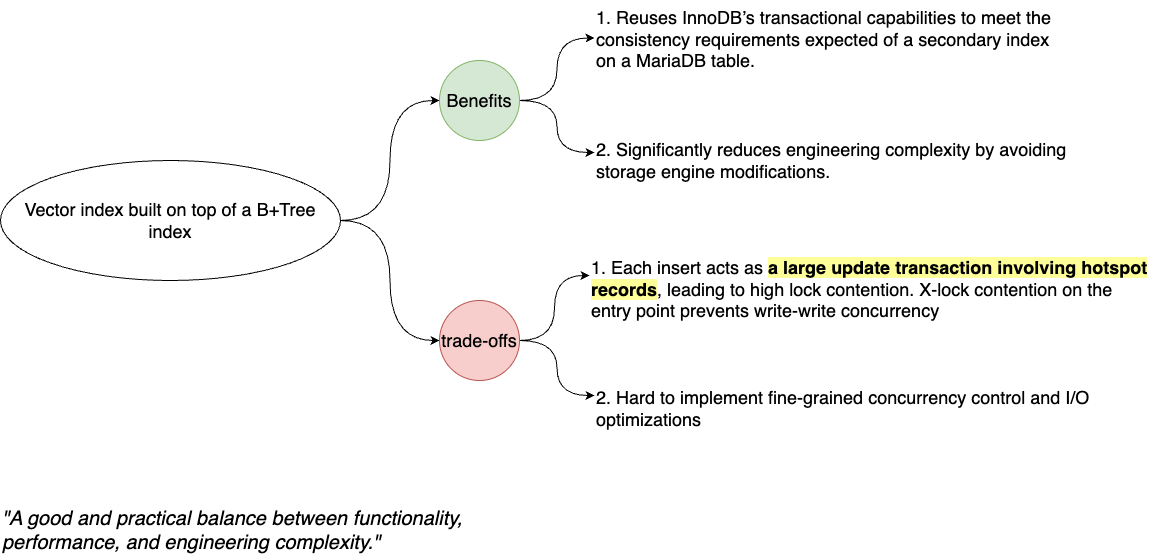
I guess this server-layer design exists because the vector index is built on a MariaDB table, which must follow all the transactional constraints of the main table. Reusing InnoDB’s transactional capabilities is thus a natural way to achieve durability and crash recovery, while significantly reducing engineering complexity.
However, each insert behaves like a large update transaction involving hotspot records. It cannot perform fine-grained concurrency control on the vector index the way InnoDB does with B+Tree latches.
Still, it represents a good and pragmatic trade-off—implementing a native vector index would require significant investment in I/O and concurrency optimizations.