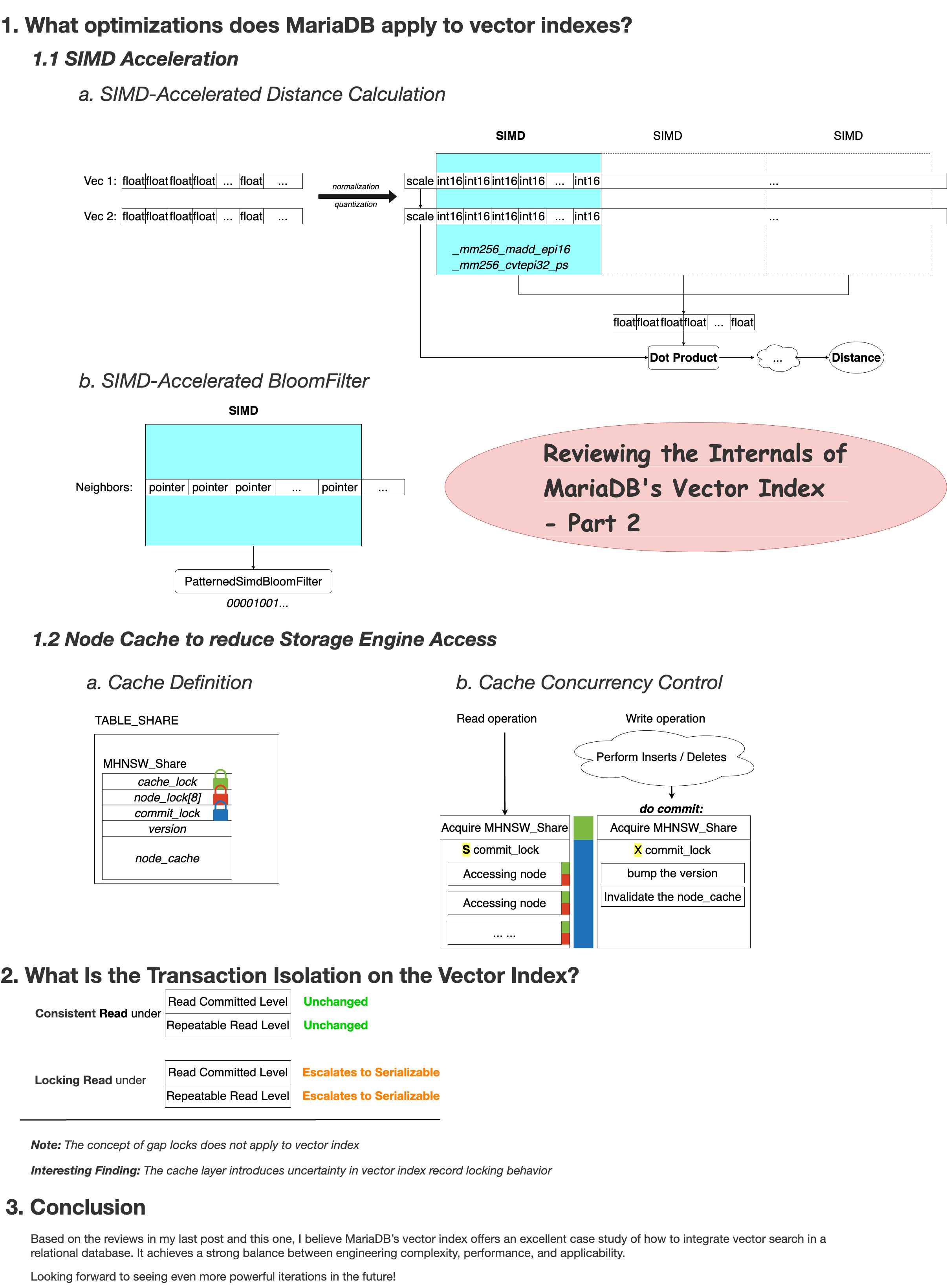
1. What optimizations does MariaDB apply to vector indexes?
1.1 SIMD Acceleration
- To improve performance, vector fields in the records are quantized from raw float arrays into fixed-point representations (scale +
int16_tarrays) using normalization and quantization. Theseint16_tarrays allow fast dot product computation using AVX2 or AVX512 instructions, which significantly speeds up vector distance calculations. - When expanding neighbors for a given node, MariaDB uses a
PatternedSimdBloomFilterto efficiently skip previously visited neighbors. This filter groups visited memory addresses in batches of 8 and uses SIMD to accelerate the matching process.
1.2 Node Caching to Reduce Storage Engine Access
-
Each table’s
TABLE_SHAREstructure holds anMHNSW_Shareobject, which contains a global cache shared across sessions (sinceTABLE_SHAREis global). -
The cache improves read performance but introduces additional locking overhead, which is worth a closer look. Three types of locks are used to manage concurrency:
cache_lock: guards the entire cache structure.node_lock[8]: partitions node-level locks to reduce contention oncache_lock. The thread first usescache_lockto locate the node, then grabsnode_lock[x]for fine-grained protection, allowingcache_lockto be released right after.commit_lock: a read-write lock that ensures consistency during writes. Readers hold the read lock throughout the query to prevent concurrent cache modifications. Writers acquire the write lock during commit, invalidate the cache, bump the version number, and notify any ongoing reads (executing betweenhlindex_read_first()andhlindex_read_next()) to switch to the new cache which generated by the writer.
Observations:
- In pure read workloads, this caching scheme works well, and the two-tier locking mechanism (
cache_lock+node_lock) minimizes contention. - In read-write workloads, however, every write invalidates the entire cache, making it less effective for concurrent readers.
2. What Is the Transaction Isolation on the Vector Index?
(This section refers specifically to vector indexes on InnoDB.)
1. Read Committed
(tx_isolation = ‘READ COMMITTED’)
- Consistent reads, remain unchanged.
- Locking reads, however, become stronger: the shared lock (S-lock) acquired on the entry-point node blocks writes completely, effectively elevating isolation to Serializable.
2. Repeatable Read
(tx_isolation = ‘REPEATABLE READ’)
- Consistent reads, remain unchanged.
- Locking reads, now acquire a next-key S-lock on the entry-point node, which again blocks concurrent writes, behaving like Serializable isolation.
Interestingly, under the Repeatable Read isolation level, the correctness of locking reads is not guaranteed by InnoDB’s next-key locks or gap locks. Since gap protection applies to ordered indexes, the concept of a “gap” does not really exist in a vector index structure. However, locking reads in this case effectively behave like Serializable, which still satisfies the requirements of Repeatable Read.
Another notable quirk: the cache layer disrupts normal locking behavior. If a node is found in the cache, no InnoDB-level lock is acquired. Locking only happens on cache misses. This makes the locking behavior somewhat unpredictable under high cache hit rates.
3. Conclusion
Based on the reviews in my last post and this one, I believe MariaDB’s current implementation of vector indexes offers an excellent case study of how to integrate vector search in a relational database. It achieves a strong balance between engineering complexity, performance, and applicability.
Looking forward to seeing even more powerful iterations in the future!