In this blog, I would like to introduce the implementation of BLOB and BLOB partial update in MySQL, and explain how the current design works together with the MVCC module to support multi-version control for BLOB columns.
1. Background
Before going into the details, I would like to briefly introduce two important concepts that are closely related to this topic.
1. Basic Principles of MySQL MVCC (Multi-Version Concurrency Control)
MySQL supports snapshot reads. Each read transaction reads data based on a certain snapshot, so even if other write transactions modify the data during the execution of a read transaction, the read transaction will always see the version it is supposed to see.
The underlying mechanism is that a write transaction directly updates the data in place on the primary key record. However, before the update happens, the old value of the field to be modified is copied into the undo space. At the same time, there is a ROLL_PTR field in the row that points to the exact location in the undo space where the old value (the undo log record) is stored.
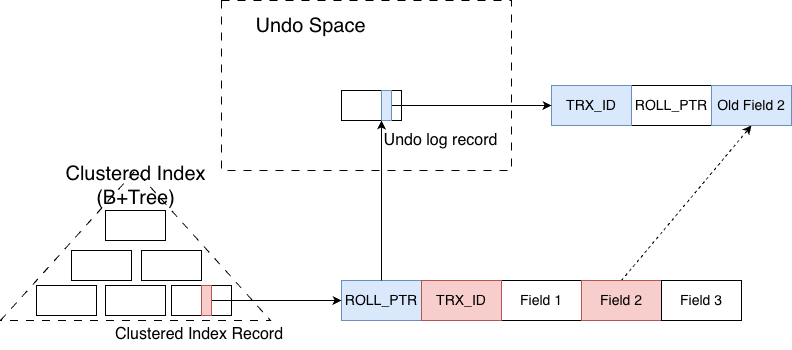
As shown in the figure above, there is a row in the primary key index that contains three fields. Suppose a write transaction is modifying Field 2. It will first copy the original value of Field 2 into the undo space, and then overwrite Field 2 directly in the row. After that, two important system fields of the row are updated:
- TRX_ID is set to the ID of the current write transaction and is used later by read transactions to determine visibility.
- ROLL_PTR points to the exact location in the undo space where the old value of the modified field is stored, and is used to reconstruct the previous version of the row when needed.
After the update is finished, if a previously existing read transaction reads this row again, it will find, based on the TRX_ID, that the row has been modified by a later write transaction. Therefore, the current version of the row is not visible to this read transaction. It must roll back to the previous version. At this point, it uses the ROLL_PTR to locate the old value in the undo space, applies it to the current row, and thus reconstructs the version that it is supposed to see.
2. Basic Implementation of MySQL BLOB
The primary key record in MySQL contains the values of all fields and is stored in the clustered index. However, BLOB columns are an exception. Since they are usually very large, MySQL stores their data in separate data pages called external pages.
A BLOB value is split into multiple parts and stored sequentially across multiple external pages. These pages are linked together in order, like a linked list. So how does the primary key record locate the corresponding BLOB data stored in those external pages? For each BLOB column, the clustered record stores a reference (lob::ref_t). This ref_t contains some metadata about the column and a pointer to the first external page where the BLOB data starts.
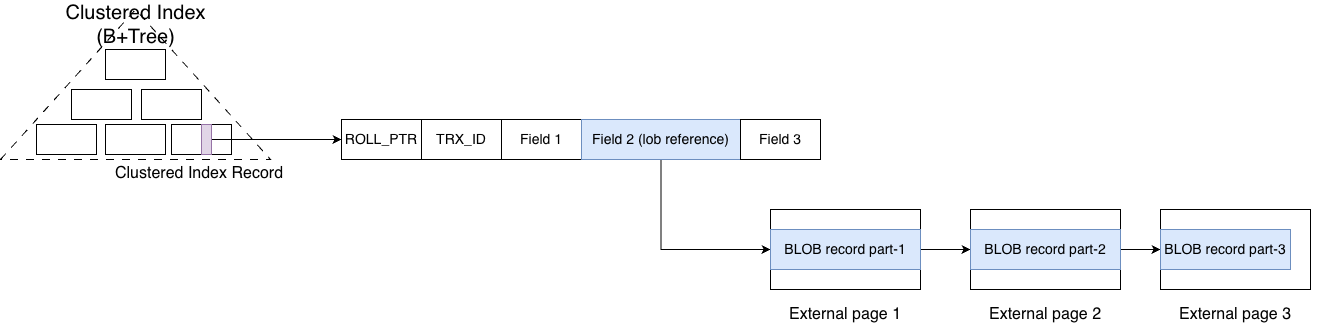
When reading the row, MySQL first locates the row via the primary key index, then follows this reference to find the external pages and reconstructs the full BLOB value by copying the data from those pages.
This is a very straightforward and intuitive design, simple and sufficient. It is also exactly how BLOB was implemented in older versions of MySQL.
3. A “Thought Exercise”
Based on the two points above, here is a question:
How is MVCC implemented for BLOB in MySQL?
The intuitive answer is as follows: the lob::ref_t stored in the primary key record follows the same MVCC rules. Every time a BLOB column is updated, the old BLOB value is read out, modified, and then the entire modified BLOB is written into newly allocated external pages. The corresponding lob::ref_t in the primary key record is overwritten with the new reference. At the same time, following the MVCC mechanism, the old lob::ref_t is copied into the undo space.
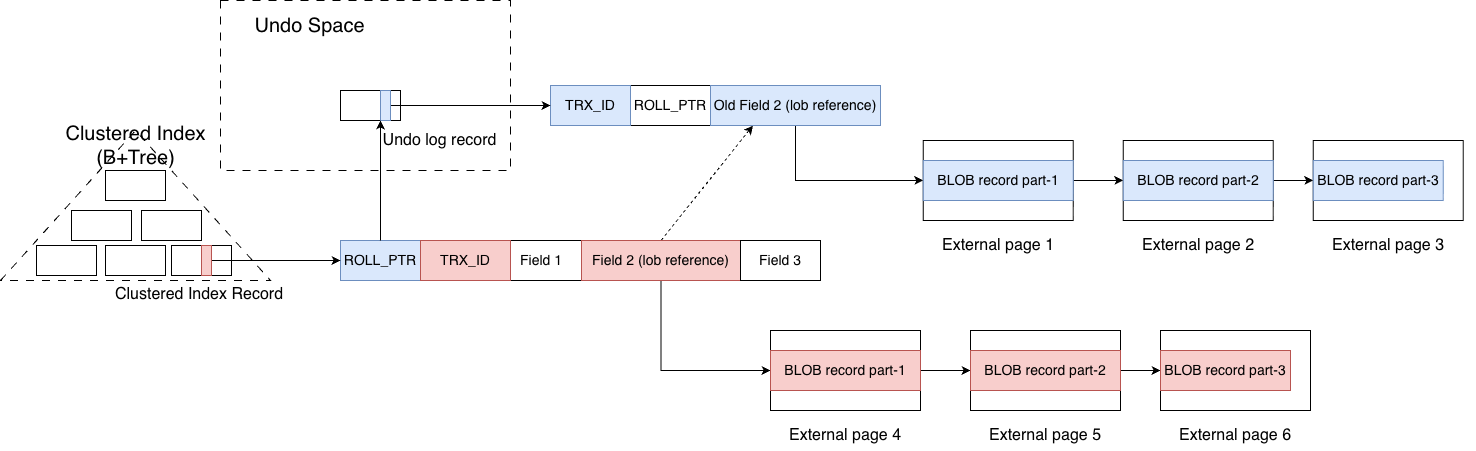
After the modification, the situation looks like this (as shown in the figure): the undo space stores the lob::ref_t that points to the old BLOB value, while the lob::ref_t in the primary key record points to the new value.
This is exactly how older versions of MySQL worked. The next question is:
What are the pros and cons of this design?
The advantage is that the undo log only needs to record the lob::ref_t, and it does not need to store the entire old BLOB value.
The disadvantage is that no matter how small the change to the BLOB is, even if only a single byte is modified, the entire modified BLOB still has to be written into newly allocated external pages. BLOB columns are usually very large, so if each update only changes a very small portion, this design introduces a lot of extra I/O and space overhead.
A typical example is JSON. Internally, MySQL stores JSON as BLOB. Usually, updates to JSON are local and small. However, with the old design, each small partial update still requires reading the entire JSON, modifying a part of it, and then inserting the whole value back again. This is obviously very heavy.
So how to solve this problem? MySQL introduced BLOB partial update to address it.
2. Implementation of BLOB Partial Update
MySQL optimized the format of the external pages used to store BLOB data and redesigned the original simple linked-list structure:

- Each external page now has a corresponding index entry.
- These index entries are organized as a linked list and stored in the BLOB first page. (If there are too many index entries to fit, they are stored in separate BLOB index pages.)
- Under normal circumstances, these index entries are linked together in order, just like the external pages in the old implementation.
- To support partial updates, MySQL changes the granularity of BLOB updates from the whole BLOB to individual external pages. Only the external pages involved in the current modification are updated. The modified external page is copied into a new page and updated there, while the other external pages remain unchanged.
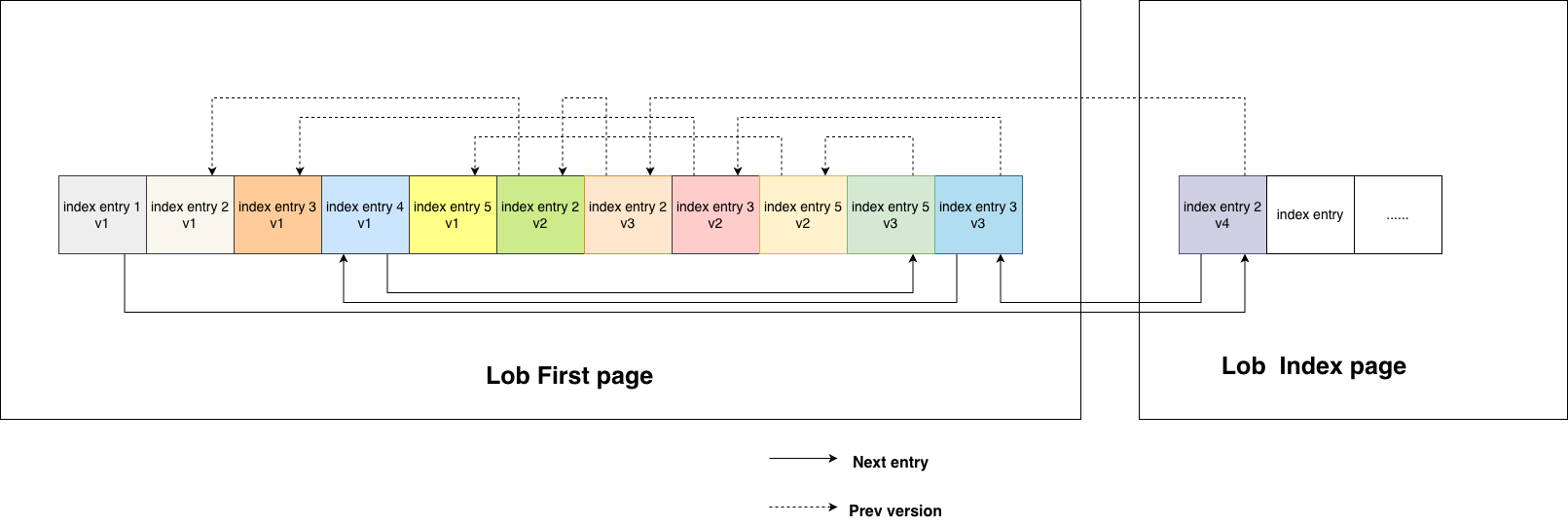
Then the question becomes: how can MySQL make sure that it can read the correct new and old BLOB values? The answer is that the new external page and the old external page share the same logical position in the index entry list. In other words, at this specific position in the list, there are now two versions, version 1 and version 2. Which one is used is determined by the version number recorded in the current lob::ref_t. The idea is illustrated in the figure below.
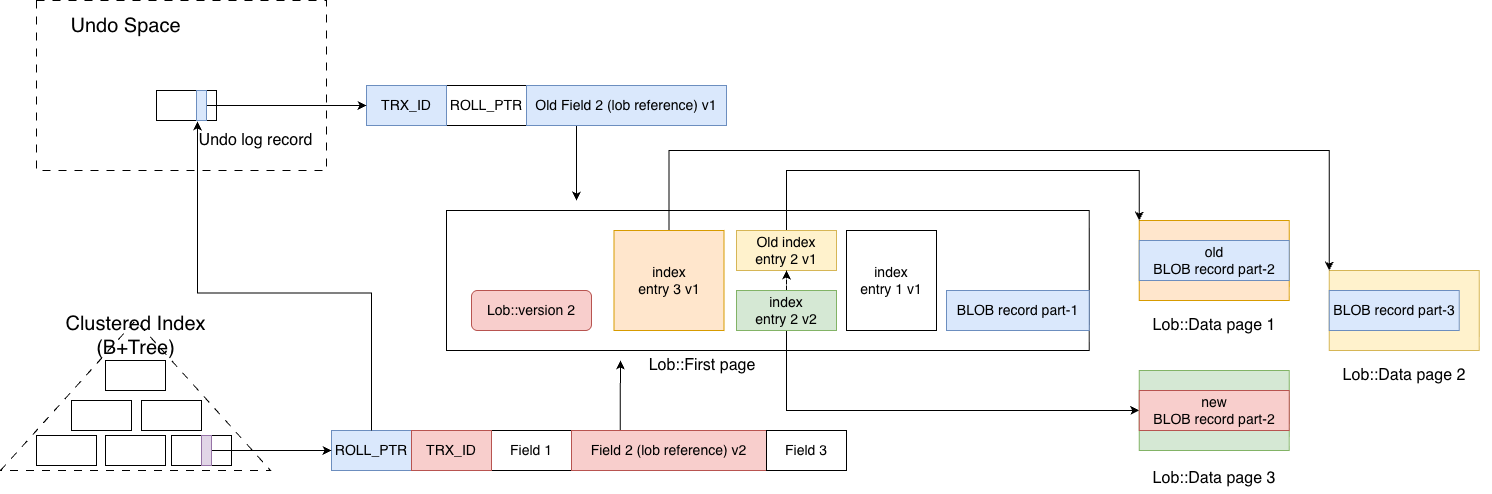
In summary, MySQL transforms the original external-page linked list into a linked list of index entries. For each index entry in this list, if the corresponding external page is modified, a new version of the index entry is created at the same horizontal position to point to the new version of that external page. Essentially, this introduces multi-versioning for external pages.
Special Case: BLOB Small Changes
The implementation described above is not the whole story. MySQL makes a practical trade-off between creating a new index entry (which requires copying the entire external page) and copying only the modified portion into the undo space.
For BLOB small-change scenarios, when the modification to a blob is smaller than 100 bytes, MySQL does not create a new index entry and link it into the version chain for that page. Instead, it modifies the page in place. Following MVCC principles, the portion to be modified is first written into the undo space before the in-place update happens.
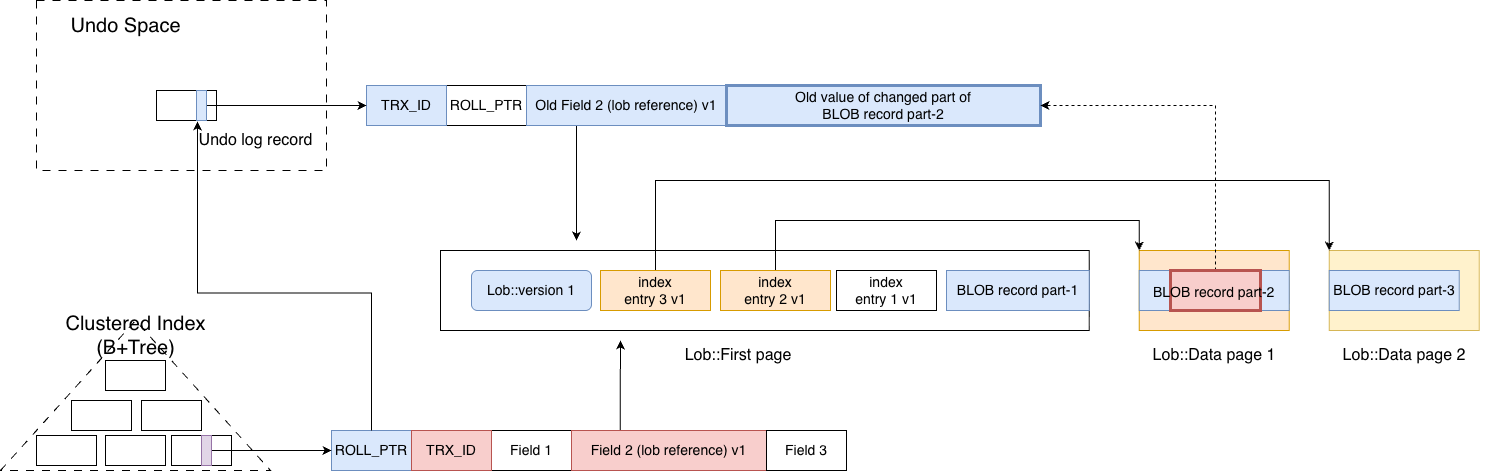
It is worth noting that in this case, the lob::ref_t stored in the primary key record does not advance its base version number. It shares the same base as the previous version. When a read transaction needs to read the previous version, it first constructs the latest BLOB value based on the lob::ref_t and the index entry list. Then, following the MVCC logic, it finds that the TRX_ID indicates that this version is not visible. At this point, it follows the ROLL_PTR to the undo space, where the old value of the modified external page is stored. By applying that old data back onto the current value, the complete and correct historical BLOB value can be reconstructed.
In this scenario, the recovery process is a combination of two steps:
- First, the version corresponding to the lob::ref_t is reconstructed via the index entry version chain.
- Then, the version visible to the current transaction is reconstructed via the ROLL_PTR chain.
Index Entry Details
Index entries are the key to the implementation of BLOB partial update. To make them easier to understand, I drew the following diagram to illustrate the logical relationships among index entries. It is a two-dimensional linked list. The horizontal dimension represents the sequential position when assembling the full BLOB value. The vertical dimension represents multiple versions at the same position. Each time the page at that position is modified, a new node is added vertically.
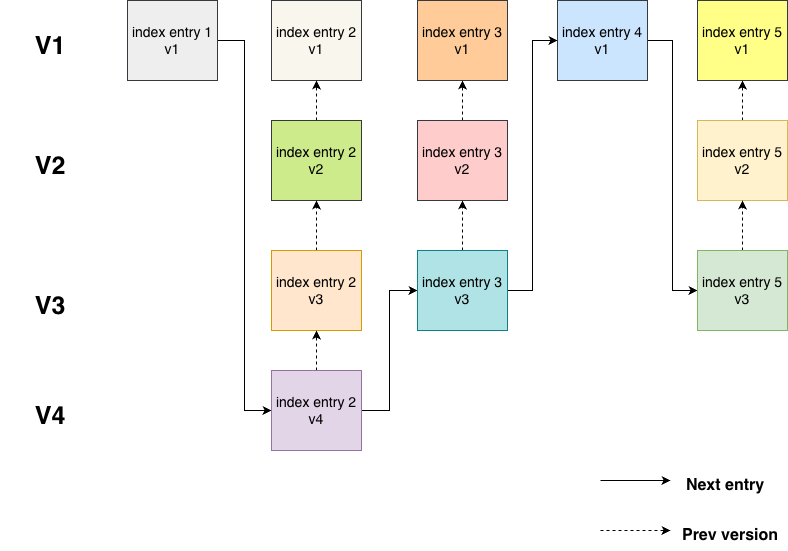
Of course, this is only a logical model. The physical layout is not organized exactly like this. Each BLOB has a BLOB first page. This page stores a portion of the BLOB data (the initial part) and 10 index entries. Each index entry corresponds to one BLOB data page. When all 10 index entries are used up, a new BLOB index page is allocated, and additional index entries are allocated from there. In reality, the index entries distributed across the BLOB first page and the BLOB index pages are linked together to form the logical structure shown in the diagram above.