Recently I have been tinkering with a question out of pure curiosity: what would PostgreSQL look like if it had a built-in page server? So I decided to try building one.
GitHub: pgStrata
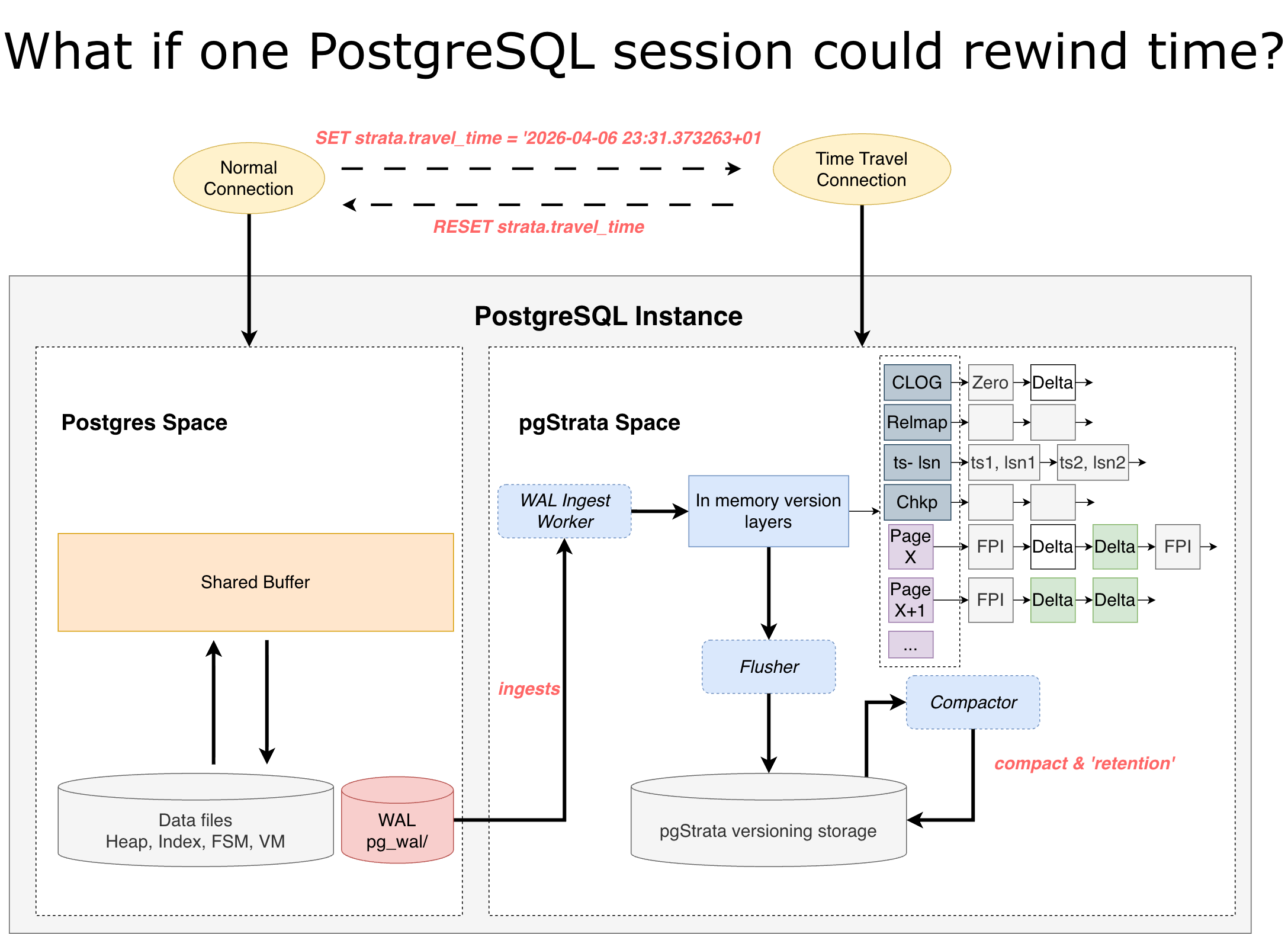
pgStrata runs inside a PostgreSQL instance. It asynchronously reads and parses WAL, then writes the information required for Time Travel: such as pages, CLOG, relmap, checkpoints, TS-LSN mappings, and more, into its own multi-version engine based on an LSM tree.
Under normal conditions, pgStrata exists as an in-instance hot standby for historical state. Regular backend reads still go through PostgreSQL’s own data files, and do not read from pgStrata.
But when a user session executes:
SET strata.travel_time = '2026-04-06 10:00:00+00';
that session switches into Time Travel mode.
In this mode, all reads bypass PostgreSQL’s current data files and go to pgStrata instead. pgStrata maps the session-specified timestamp to the corresponding LSN, then reconstructs the required data pages, transaction states, relmap, and other metadata from that point in time.
Because every read is based on the state of the entire PostgreSQL instance at that exact moment, even tables that have already been dropped in the current database state can become visible again.
And when the session executes:
RESET strata.travel_time;
it leaves Time Travel mode and returns to the latest PostgreSQL state.
Example↓
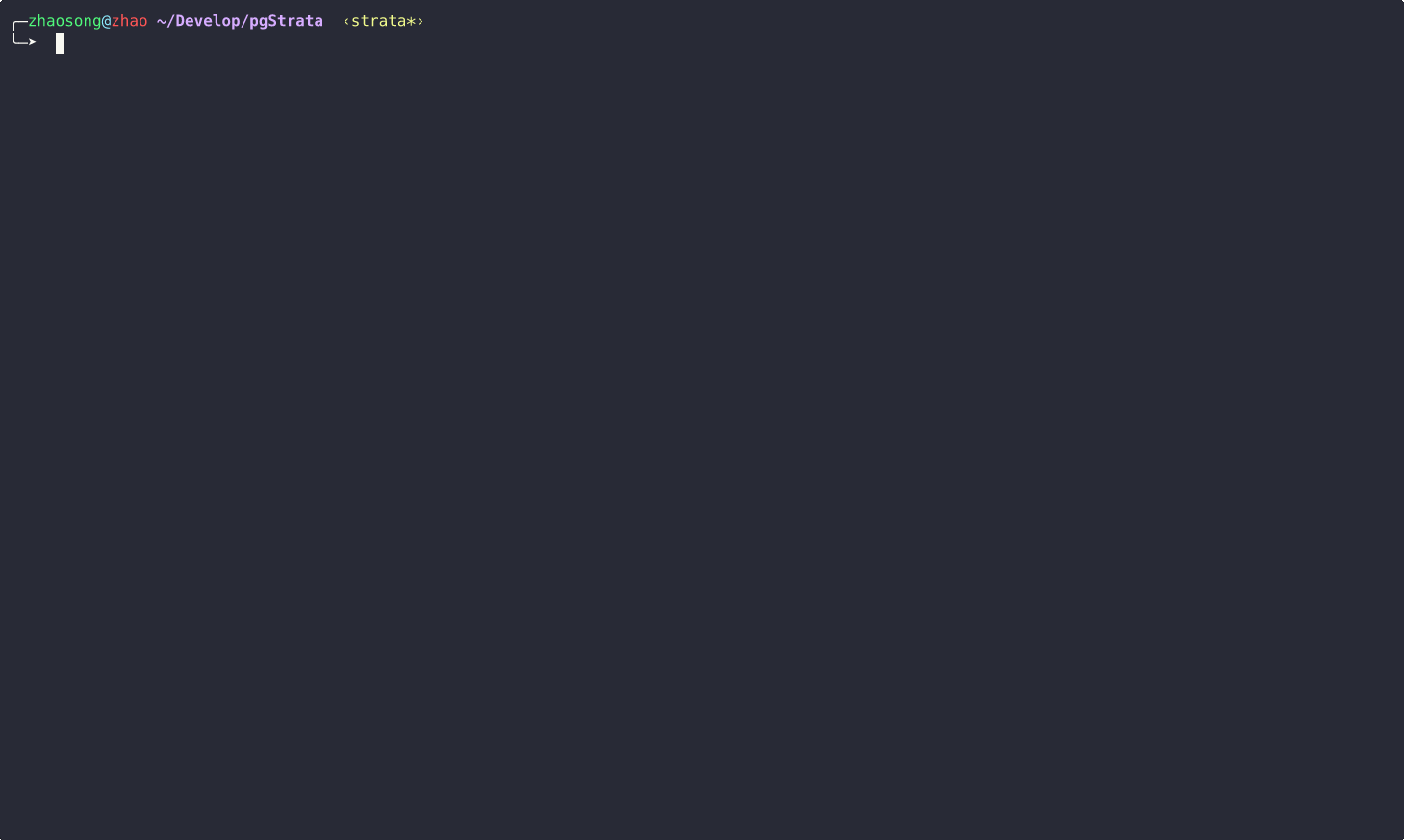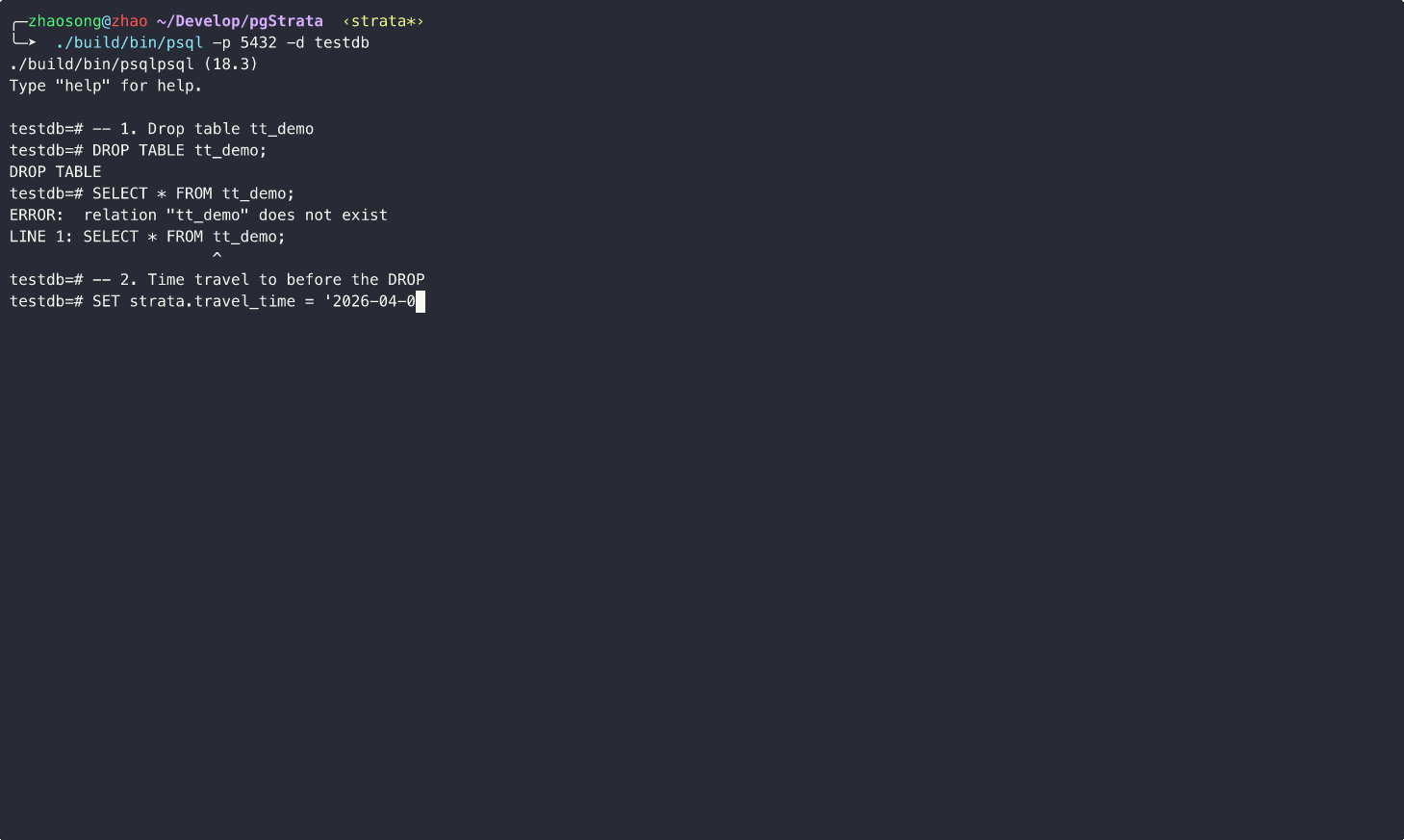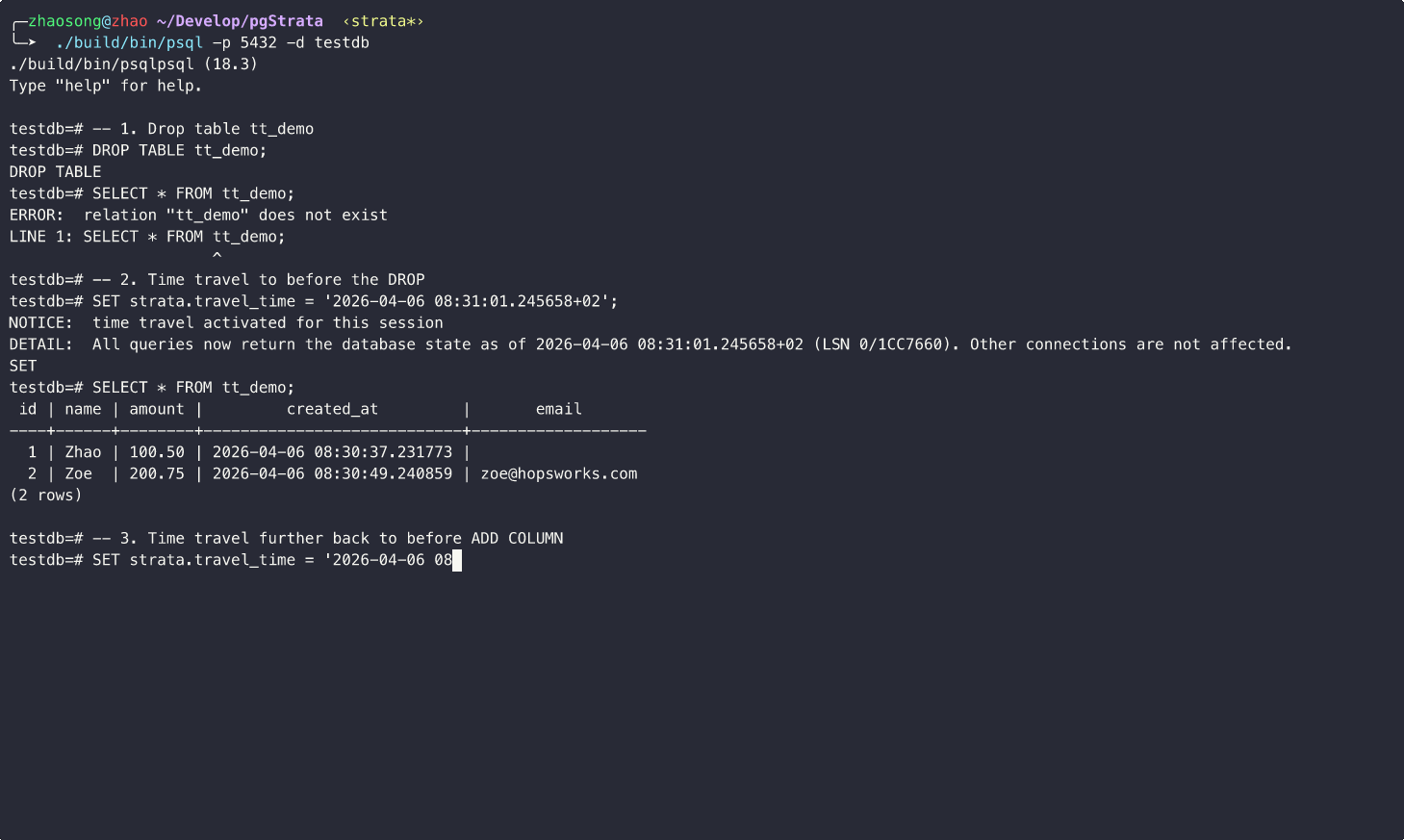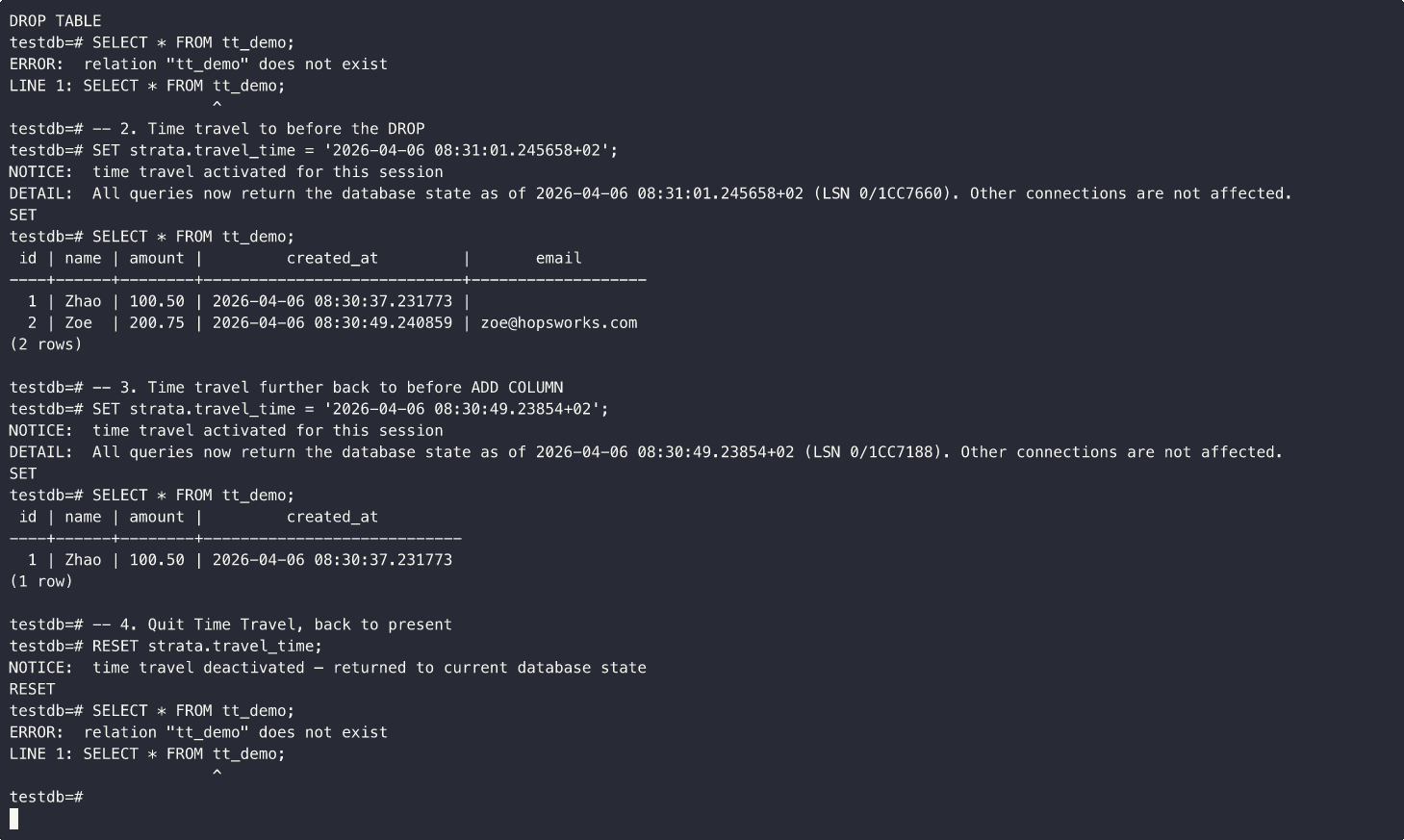
The basic idea is illustrated below:
Mainstream PostgreSQL Time Travel approaches today
The mainstream ways to do Time Travel in PostgreSQL today are roughly these:
1. Point-in-time restore
This works by spinning up a new database instance, restoring a backup, and replaying incremental WAL up to the target time.
The main problem is that recovery takes time, and it is not very friendly for scenarios where you want to switch back and forth across multiple timestamps for testing. In practice, it feels more like a one-shot or one-directional Time Travel workflow.
2. Cloud databases
In compute-storage separated architectures, a multi-version page server is naturally well suited for Time Travel. But even in systems like Neon, Time Travel still typically requires bringing up a new compute node.
For ordinary single-instance scenarios, if you just want simple Time Travel but have to move to the cloud for it, cost also becomes part of the discussion.
So I wanted to see what it would look like to give a standalone PostgreSQL instance a built-in page server.
What I am aiming for
With this design, simple Time Travel can happen directly inside a session.
The extra cost mainly comes from: disk space for historical versions, multi-version maintenance, CPU and I/O overhead when reconstructing historical versions.
It runs inside PostgreSQL, but stays loosely coupled. The goal is simple: do not get in the way of normal PostgreSQL operation.
I have already hacked together a basic version. Along the way, a few engineering challenges have shown up.
Engineering challenges so far
- pgStrata cannot rely on fallback reads from PostgreSQL data files. In principle, pgStrata should not fall back to PostgreSQL data files for I/O. That makes full tracking of database file state very important. It needs to maintain the full historical metadata of all relations, including the size of each data file over time, handling events such as file extension and truncation, so that the system is fully self-sufficient.
-
Reconstructing historical pages requires replaying WAL deltas on top of base FPIs. To build a historical page, pgStrata needs to take a base full-page image (FPI) and apply WAL deltas on top of it. This is the biggest piece of work. At the moment, it supports: RM_HEAP_ID, RM_HEAP2_ID, RM_BTREE_ID, RM_SEQ_ID. The rest still need to be implemented gradually.
-
Query performance after Time Travel can be slow on large datasets. I ran some basic stress tests, and for large datasets, queries after entering Time Travel mode can become slow when reconstructing historical pages. This depends heavily on how many usable FPIs exist along the version chain. One possible optimization is to insert reconstructed historical pages back into the version chain during compaction, or even during one-off reconstruction. That way, the more FPIs you accumulate, the faster future reconstruction becomes. But of course this is a trade-off between reconstruction speed and space usage.
-
The current LSM design is still very rough. Right now the LSM implementation only has three levels: in-memory, L0, L1. Compaction is also still very simple and brute-force. A key-value separation design would probably be much better here, because nearly all deltas are effectively non-deletable if arbitrary-point Time Travel is to remain supported. Otherwise, every compaction causes heavy write amplification. Separating keys and values should help a lot, but I have not implemented that yet.
- Space control is still unfinished. For space management, one possible approach is to configure either a retention window or a storage size limit, and then let compaction drop the oldest historical versions. But even that cannot be done by simply deleting old entries. Before dropping old history, the system would need to merge the FPI and deltas that are about to be removed into a new synthetic FPI and place it at the front of the version chain, so that reconstruction still remains correct. This part is also still not implemented.
Closing thoughts
I will keep improving it when I find the time.
That said, this feature may very well turn out to be a pseudo-demand after all… haha.