This thought hit me on the way to work today: (The table ‘items’ has an HNSW index on the vector column ‘embedding’)
BEGIN;
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
……
Can we really say this SELECT is repeatable read safe❓
I used to assume pgvector, as a PostgreSQL extension, naturally inherits Postgres’s transactional guarantees — but after thinking it through, that might not be the case.
PostgreSQL MVCC relies on 3 assumptions:
- Indexes are append-only: Write operations only insert new index entries — never update or delete them.
- The heap stores version history: Each row’s versions are retained for snapshot-based visibility checks.
- VACUUM coordinates cleanup: It purges dead heap tuples and their corresponding index entries together.
This works well with native ordered index like nbtree. For example:
- A REPEATABLE READ transaction performs the same SELECT twice.
- Between them, a new row B is inserted.
- In the second SELECT, B appears in the index scan but is filtered out after a heap visibility check.
So, the query still returns the same results — consistent with REPEATABLE READ.
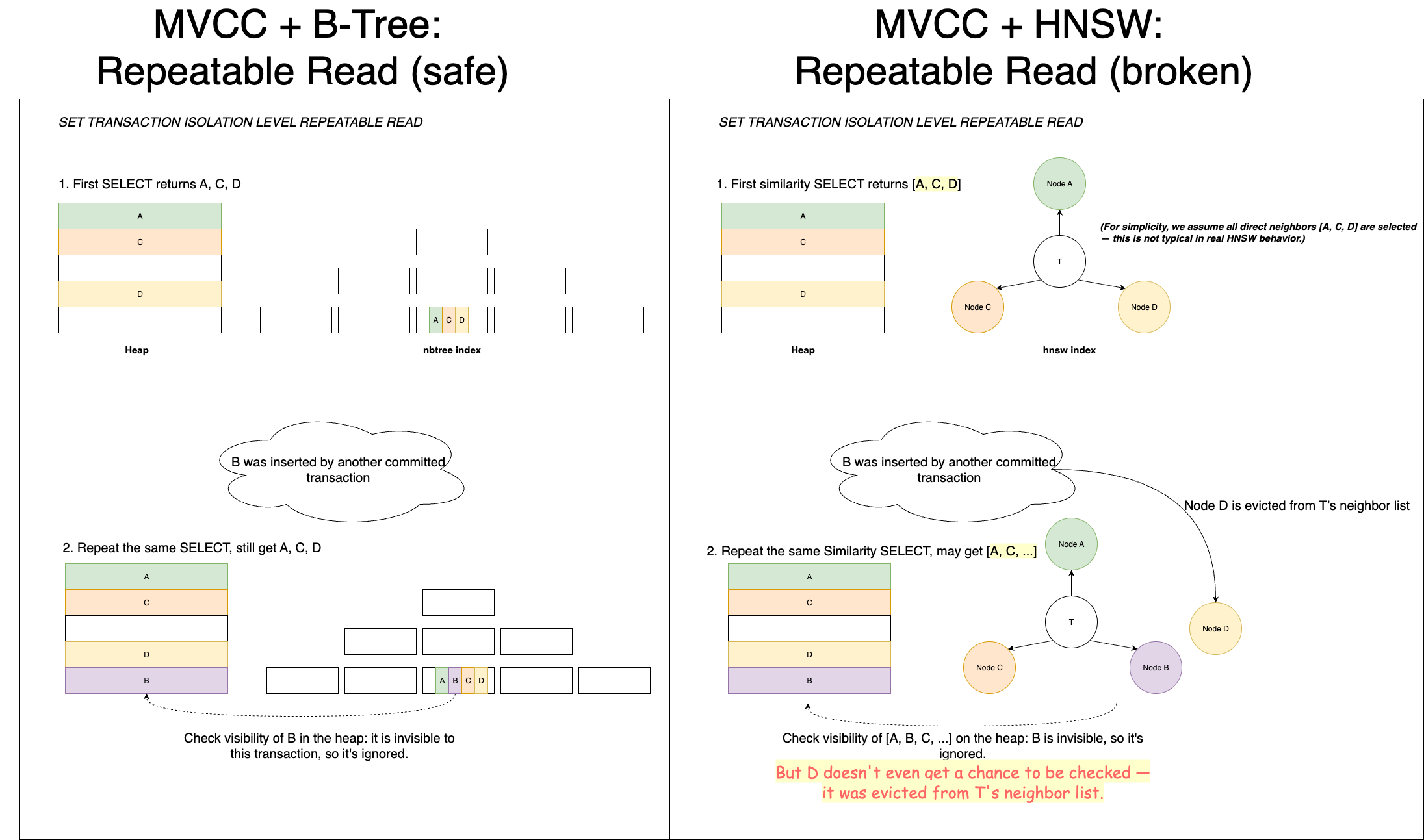
But HNSW behaves differently…
When inserting a new vector B:
- B searches the graph to find neighbors.
- Selected neighbors (say, T) update their neighbor lists to include B.
- If T’s list is full, HNSW re-selects top-k neighbors — possibly evicting an existing node like D.
Here’s the issue: T’s neighbor list is modified — breaking assumption #1. Now, suppose a REPEATABLE READ transaction had previously discovered D via T. In its second identical query, it may no longer reach D, simply because D was evicted from T’s neighbor list. At the same time, the newly inserted B is now reachable — but is correctly rejected due to heap visibility checks.
Root cause:
- The HNSW index breaks MVCC’s immutability assumption: It performs in-place modifications to graph nodes during insertions.
- No versioning in HNSW index: There’s no way to preserve historical neighbor lists for concurrent transactions. Even though I prefer pgvector’s low-level, native integration (at the same level as nbtree), MariaDB’s design may provide better transactional isolation here. Its HNSW index is implemented as a separate InnoDB table — which naturally supports MVCC, including versioned index “rows.”
This question came to mind today — I reached a tentative conclusion through some code review and thought experiments. Haven’t verified this with a test case yet, so feel free to correct me if I’m wrong.
🤔 BTW, lately, I’ve been comparing how vector search is implemented in transactional databases vs dedicated vector databases by reading through their code. It’s exciting to see traditional databases embracing new trends — but what do you think: Do transactions bring real value to vector search, or are they more of a burden in practice? And what about the other way around?
Discussion
This post has sparked some discussion on LinkedIn, with two main points being raised:
- HNSW is approximate search by nature, so strict Repeatable Read isn’t required.
- PostgreSQL doesn’t currently guarantee identical results in all cases anyway (e.g., non-unique indexes with
SELECT ... ORDER BY ... LIMIT ...), because different execution plans can produce different result orders.
I’m not convinced by either of these arguments:
- Approximate search is an inherent trade-off in the vector search domain. It’s unrelated to PostgreSQL’s ACID guarantees, and using vector search shouldn’t be a reason to compromise on them.
- The core issue here isn’t about result order — it’s about the result set itself. Query plan variability doesn’t explain this away, because even if we strictly control every runtime condition to ensure identical execution plans, HNSW can still produce different result sets (not just differently ordered sets) due to the root cause I described above.