最近打算搞pika的跨机房同步,主要解决公司多机房实例相互同步的问题,其实比较关键的点就是解决多机房写入时序问题及网络故障和中心服务挂掉的容灾问题,这两天搞了一个设计方案,后续应该会在这上面改进
一. 设计目标
- 支持多机房写入,自动同步给其他机房
- 支持容灾(网络故障恢复断点续传,Hub故障切换)
- 自动修复由于网络异常带来的同步命令乱序问题
注: 如果多机房同一时刻对同一个key做了写入,则以Hub收到的第一个命令为主保证一致,其他忽略
二. 详细设计
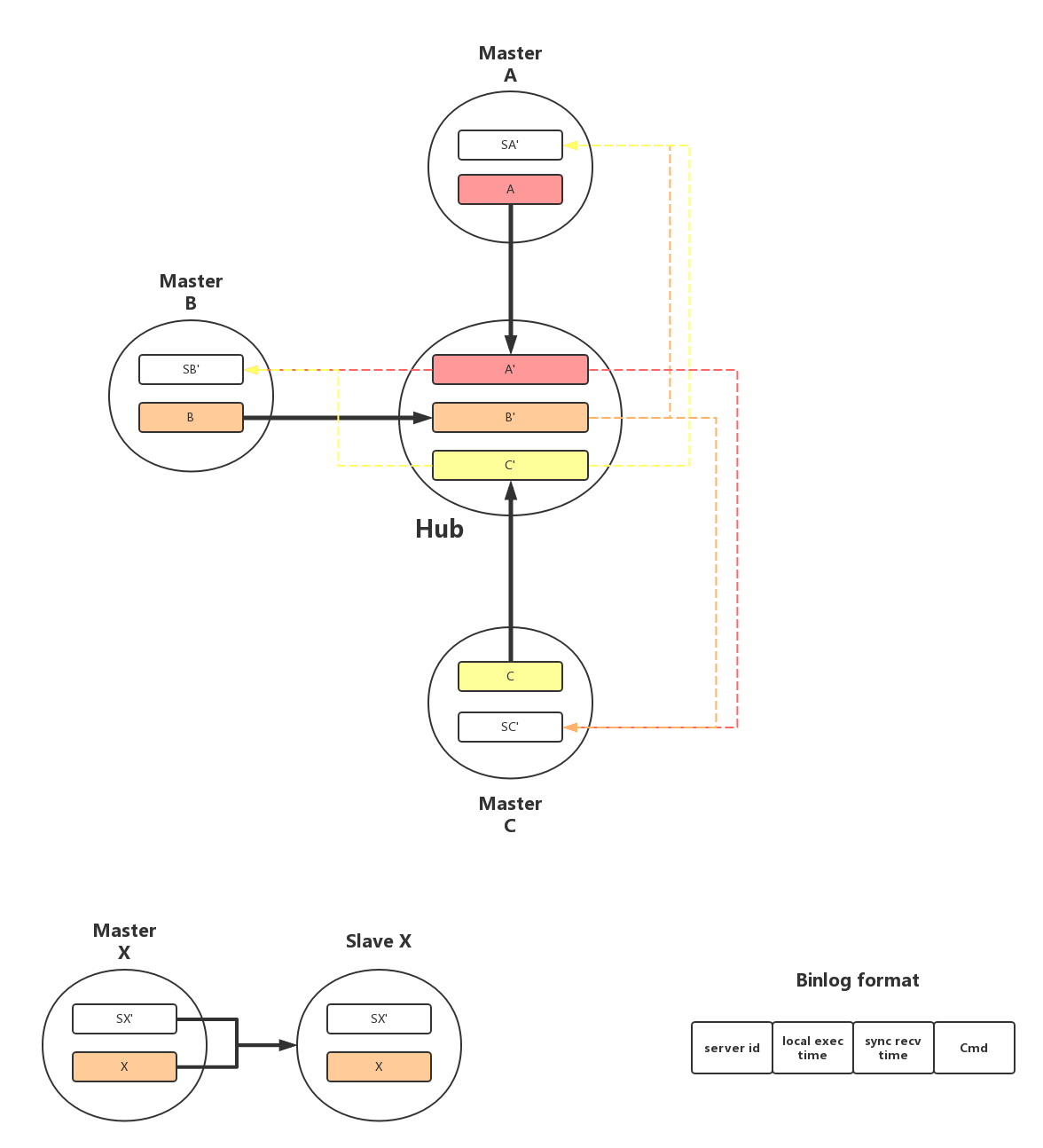
1. 整体结构
2. binlog格式
server id:每个机房唯一,用以区分命令来源
local exec time:记录命令在源端执行时刻的时间戳
sync recv time:记录命令在Hub端收到并记录日志时刻的时间戳
Cmd:同步命令
3. 跨机房同步流程
Hub是转发服务,它以特殊的slave身份同时连接到A,B,C三个机房作为他们的slave,接收对端BinlogSender发来的同步命令,并且在本地记录到对应的binlog中,如上图 A’,B’,C’;
Hub对应每一个机房都有一个线程HubSender专门负责转发其他机房的命令,以A机房为例,其在Hub对应的HubSenderA线程不断的扫描B’和C’,根据命令的sync recv time进行merge从小到大将命令发送给A,A在收到命令后在本地执行并记录到SA’中
Hub记录每个机房对应的HubSender当前已同步的Binlog偏移,当与某个机房故障恢复后通过记录的偏移量在本地Binlog A’,B’,C’中进行定位,开始断点续传
4. 主从同步流程
以A机房为例,Master的Binlog Sender扫描Binlog A和A’,根据sync recv time进行merge从小到大将命令发送给Slave即可
如果Slave为Hub,则BinlogSender仅需扫描Binlog A进行增量发送,不需要关注A’
Master收到slave的trysync命令,附带slave的偏移量(4个值),在本地进行定位,开始续传
5. 冲突检测
Hub的Binlog Receiver在收到同步命令并追加写A’,B’,C’时,会将命令对应的key的local sync time及server id缓存起来,如果这条key的local sync time大于已缓存的值,则更新,如果小于则忽略,如果server id不同但local sync time与缓存值相等,则代表用户向多个机房同时写入同一个key,不更新缓存,此时记录该行为
以机房A为例,Hub的HubSender会扫描B’,C’并将命令发送给机房A,不过在发送每一条命令之前, 将命令里的key机器local sync time与缓存的值进行比较,如果小于则忽略,如果相等并且serverid与缓存相等则发送,否则忽略
6. 故障恢复
- 网络长时间断开:上述方案已经可以解决网络长时间断开而导致的时序性问题
- Hub宕机:Hub通过floyd定时更新每一个机房对应HubSender当前的发送偏移量,并通过网络持续给follower同步A’,B’,C’,如果发生Hub宕机,则通过raft自动选出新的leader,新的leader通过Apply本地的binlog,恢复出最近一段时间内(如1小时)的缓存(key->local sync time + server id),恢复结束后,开始继续服务
三. 总结
这两年通过搞pika,zeppelin,zgw,发现主要精力往往不是在正常功能的实现,而是对各种异常情况下的处理考量,评价一个server好不好,不能只看所谓的性能,还要看运维是否友好,容灾容错是否完善。