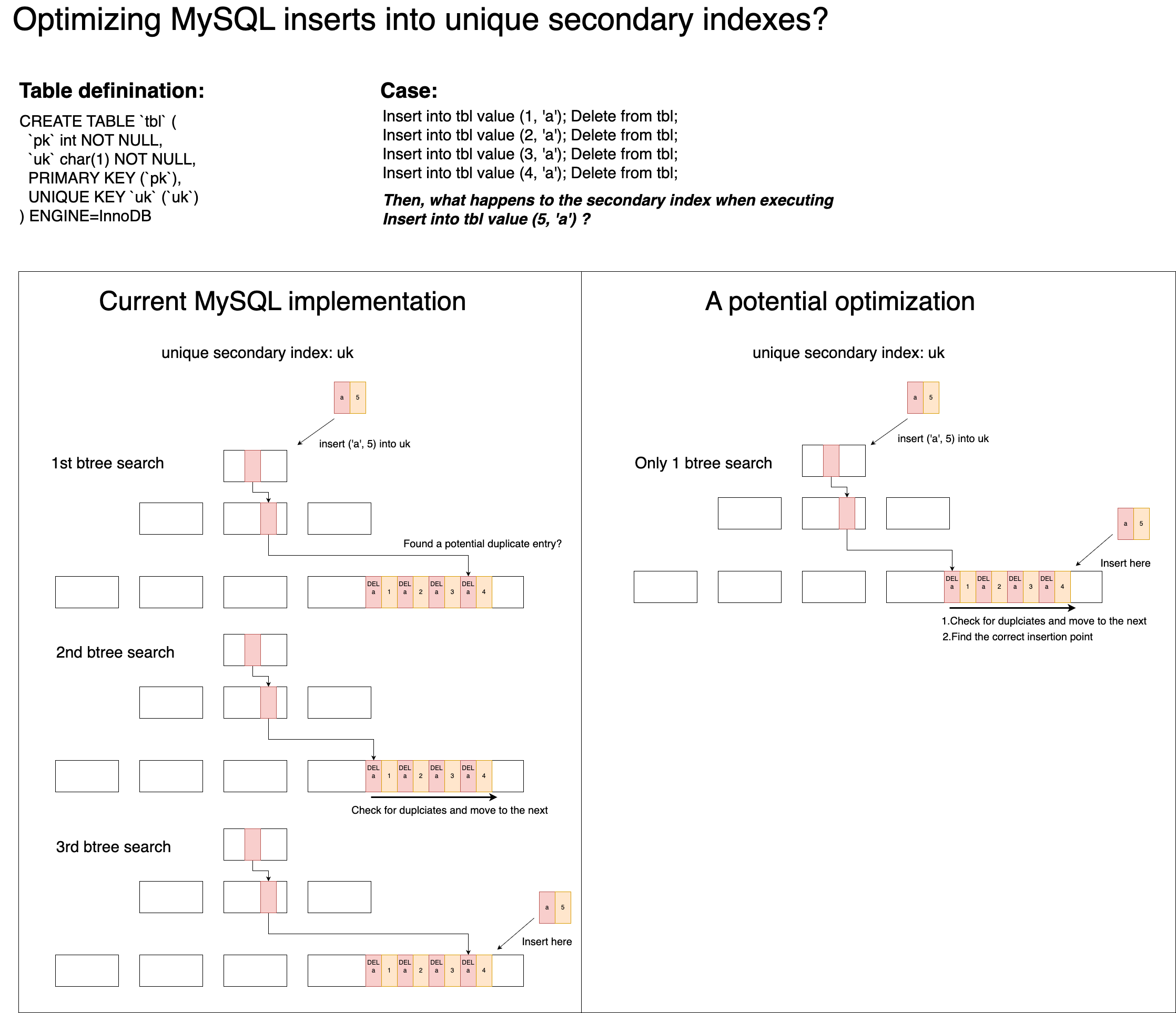
A few months ago, I wrote a post about a possible optimization in MySQL’s unique index insertion path. As illustrated there, the idea is to reduce the current 3 B+Tree searches into 1 B+Tree search plus a scan on the leaf page (or leaf level), in order to avoid the overhead of repeatedly traversing the tree. This weekend, I implemented a quick proof-of-concept on MySQL 8.0.45 and measure the effect.
1. Setup:
Table with 200K rows, a VARCHAR(700) unique key (latin1), creating a tall B-tree:
CREATE TABLE t1 (
id INT PRIMARY KEY AUTO_INCREMENT,
uk_col VARCHAR(700) NOT NULL,
UNIQUE KEY uk_idx (uk_col)
) ENGINE=InnoDB CHARACTER SET latin1;
2. Test procedure:
- Insert 100 TARGET rows with prefix “TARGET_ROW_”
- Start a blocker transaction (START TRANSACTION WITH CONSISTENT SNAPSHOT) to prevent purge
- Delete the 100 TARGET rows (creates delete-marked records)
- Re-insert the same 100 TARGET rows, this triggers the duplicate-check path, since delete-marked records with the same unique key exist
- Instrument row_ins_sec_index_entry_low() with timing around each B-tree search.
- Run the benchmark twice: once with the original path, reset metrics, then with the optimized path
3. Results:
Original path (3 B-tree searches):
- Search1: ~6,508 ns
- Search2: ~5,649 ns
- Search3: ~2,498 ns
- Total: ~14,656 ns
Optimized path (1 B-tree search + inline scan):
-
Search1: ~7,272 ns
-
Inline: ~3,118 ns
- Total: ~10,390 ns
Improvement: ~29.1% reduction in search-path time
This test focuses specifically on the unique index insertion path (row_ins_sec_index_entry_low()), comparing the cost of the original three searches with the optimized “one search + inline scan” approach. In this local scope, the saving is close to 30%, which matches the intuition of collapsing three tree traversals into one.
4. However, when evaluating the overall benefit, there are a few important considerations:
-
In a single-row insert, how large is this part relative to the whole insert path? If its share is small, the end-to-end gain will be diluted. In my tests, when measuring the full insert path, the improvement drops to single-digit percentages.
-
Under concurrent workloads, each of the three B-tree searches holds page latches. This is one of the key factors affecting scalability. Reducing this section by ~30% also shortens latch holding time, so the benefit may be more visible in parallel scenarios.
-
While implementing the POC, I also realized that this optimization is not a silver bullet. There are cases that still need to fall back to the original path, although there are ways to minimize how often that happens.
These are just the numbers from a quick POC. If this direction turns out to be meaningful, it would still require much more careful design, implementation, and testing.