In the previous post, I took a detailed look at how MySQL and PostgreSQL differ in their buffer pool design and implementation. In this post, I will continue with a detailed comparison of their MVCC implementations.
The Role of MVCC
MVCC (Multi-version Concurrency Control) is a common mechanism used in transactional databases to resolve read–write conflicts. The core idea is that when a transaction modifies data, it does not overwrite the original data directly. Instead, it preserves the previous version while creating a new version of the record. As a result, all historical versions of a record are retained in the database.
The key benefit is that read and write transactions on the same record no longer need to block each other. Even if a write transaction has modified a record but not yet committed, a read transaction can still directly read the version that is visible to it from the historical versions.
The simplified principle is illustrated below:
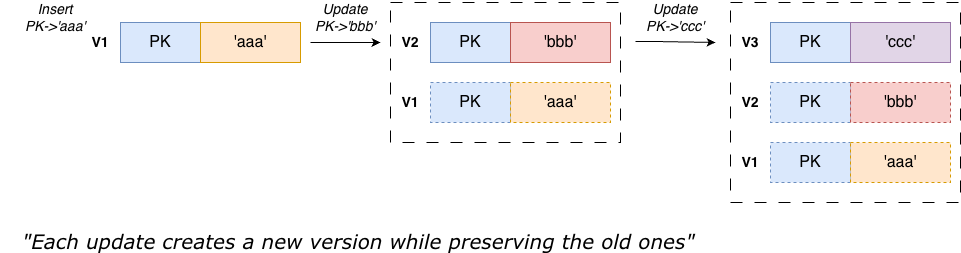
For three modifications to the record with PK, each modification creates a new version, so all historical versions of the record are retained in the database.
So what is the benefit of retaining all historical versions? Consider the following example:
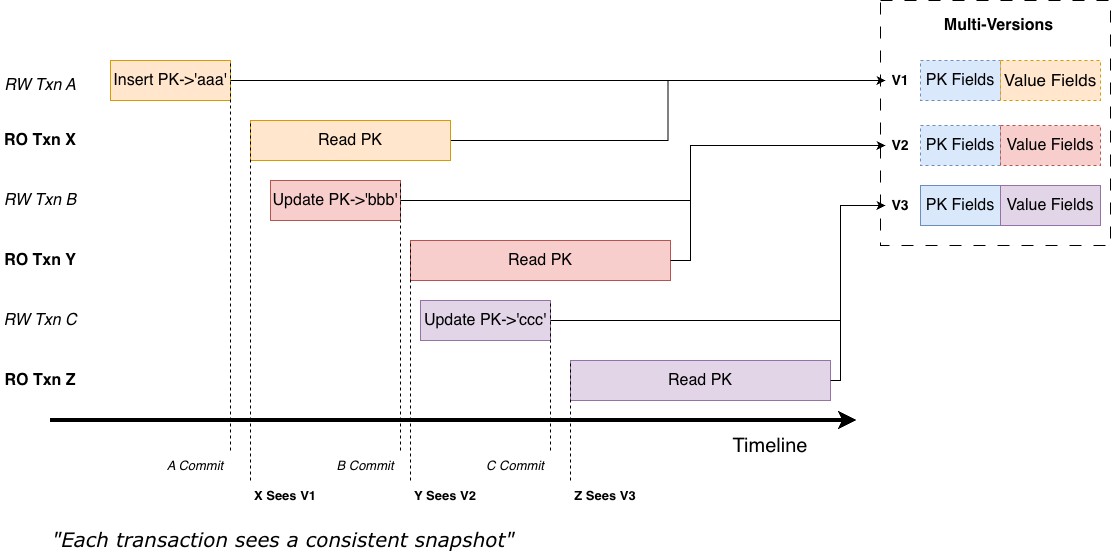
Three write transactions A, B, and C modify the same PK sequentially on the timeline, while three read transactions X, Y, and Z interleave with them and read the PK. Without MVCC, read transactions must block until write transactions commit and release locks. With MVCC, when read transaction X attempts to read the PK, the state of the PK is:
- Write transaction A inserted PK: ‘aaa’ and has committed
- Write transaction B modified it to PK: ‘bbb’ but has not yet committed
Under RC (Read Committed) and RR (Repeatable Read) isolation levels, PK: ‘bbb’ is not visible to transaction X. Because MVCC preserves the old version, transaction X can directly read the visible version PK: ‘aaa’ and ignore the currently running write transaction B. This greatly improves read–write concurrency.
As an essential capability of databases, MVCC is supported by both MySQL and PostgreSQL. Fundamentally, they both achieve the behavior described above, but their designs and implementations make different trade-offs.
In the following sections, I will compare their implementations in detail across three aspects:
- Organization of multiple versions
- Visibility checks for multiple versions
- Garbage collection of old versions
1. Organization of Multiple Versions
PostgreSQL
In PostgreSQL, a tuple and all its historical versions reside in the heap, as shown below:
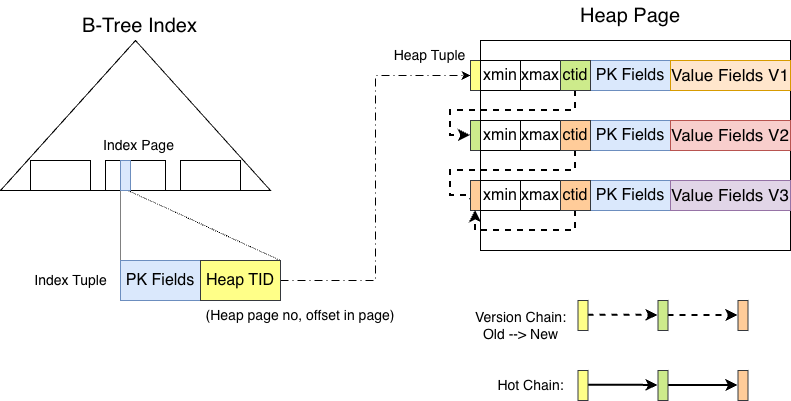
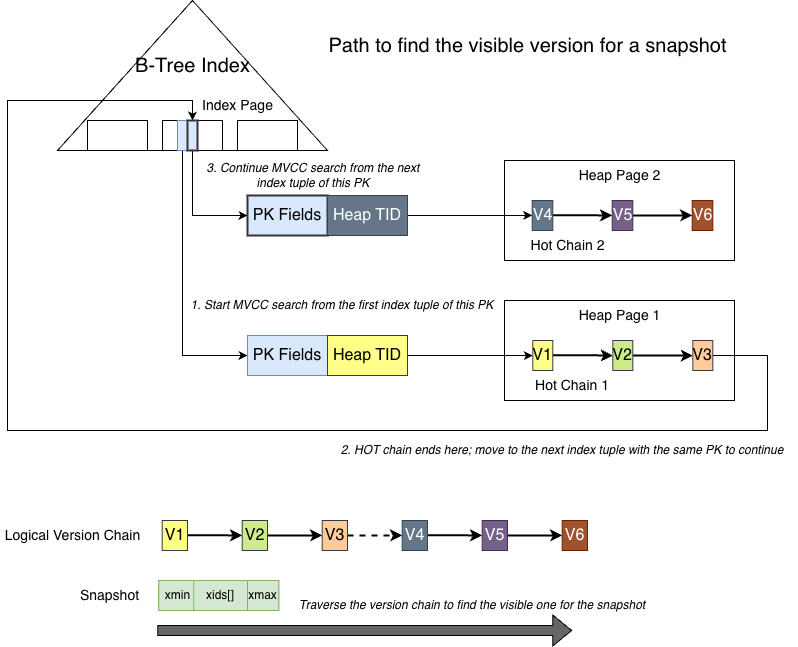
The leaf nodes of the nbtree index store the PK fields of the tuple and point to the actual location of the tuple in the heap (TID). Following the Heap TID leads to the tuple, which contains the full data including PK fields and value fields.
Each index tuple points to the oldest version in its corresponding HOT chain. When the tuple is modified, the old version is not changed. Instead, a new version is created with the same PK fields but different value fields. The ctid field of the old tuple points to the location of the next version. The latest version’s ctid points to itself.
In short, every version of a PostgreSQL tuple is a complete tuple containing all fields. Starting from the index tuple, the version chain is linked from old to new through the ctid field.
It is important to note that the version chain may become ‘broken’, as shown below:
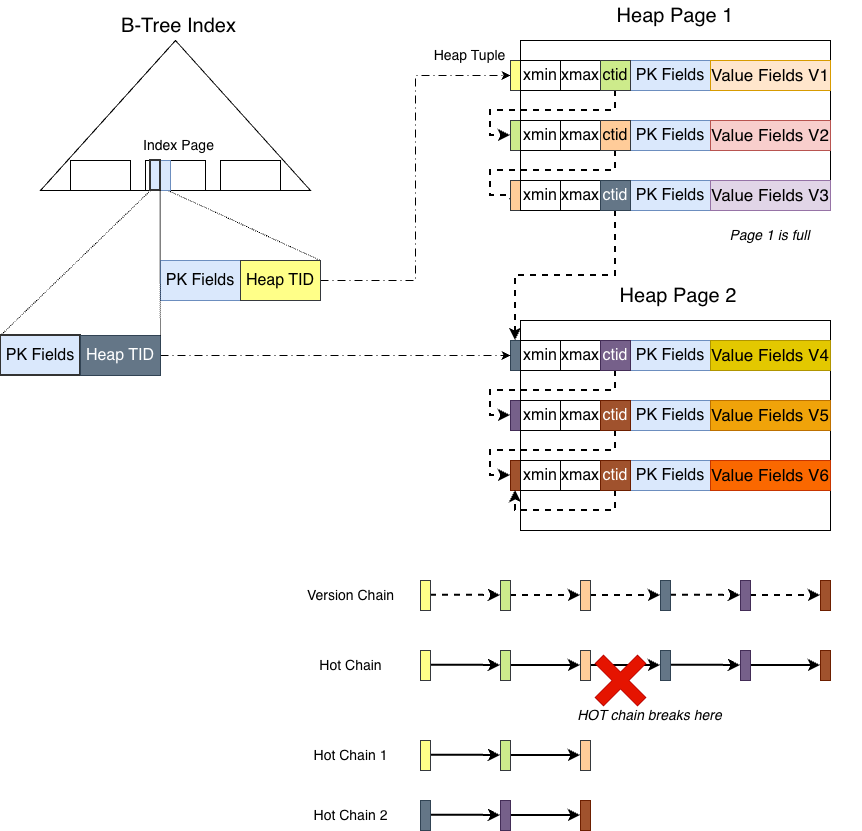
The PK fields remain unchanged, but the value fields are modified multiple times. Each modification generates a new full version stored in the same heap page as the old version, as shown for versions 1, 2, and 3. Because they reside in the same heap page, advancing through the chain via ctid is very cheap (no additional heap page lock is required). This is the type of chain that can be efficiently traversed for version lookups, known as a HOT chain in PostgreSQL.
A HOT chain requires two conditions:
- The new version can fit into the same heap page
- The modified columns do not include any indexed columns
If either condition is not met, the HOT chain breaks.
As modifications continue, starting from version 4, the original heap page (heap page 1) can no longer accommodate the new tuple. The new tuple is therefore stored in another page (heap page 2). Although version 3’s ctid still points to version 4, the HOT chain effectively ends at version 3.
When traversing a HOT chain, the reader will not follow ctid across heap pages. Instead, it stops at the end of the chain. The reason is that both the latest and historical versions of tuples reside in heap pages. If the reader followed ctid from page 1 to page 2, it would hold a read lock on heap page 1 and attempt to acquire a read lock on heap page 2. Because both pages are heap pages and there is no defined lock ordering between them, another backend might hold the lock on page 2 and attempt to acquire the lock on page 1, leading to a deadlock.
At this point, the HOT chain is considered broken.
How does PostgreSQL transition from version 3 to version 4 then?
The implementation is to insert a new index tuple into the nbtree index with the same PK fields pointing to version 4, starting a new HOT chain. If a read operation traverses the version chain and finds versions 1, 2, and 3 all invisible, it stops the current HOT chain traversal and returns to the index layer. It then proceeds to the next index tuple (the one pointing to version 4).
This design leads to an interesting and somewhat counterintuitive behavior: multiple index tuples with identical PK fields may coexist in the nbtree index.
MySQL
In MySQL, data is stored directly in the clustered index (B+Tree) leaf nodes. This is an important difference from PostgreSQL: MySQL does not have a heap.
The second difference is that the record stored in the clustered index and its historical versions reside in different places. Historical versions are not stored in the clustered index. Instead, old values are stored in undo records in the undo space. When needed, historical versions are reconstructed by applying the undo records to the current record.
The third difference is that an undo record does not store a full copy of the record. It only stores the old values of the columns modified in the operation.
The fourth difference is the direction of the version chain. In MySQL, the clustered index always stores the latest version. Before a record is modified, the old values of the columns being changed (together with the PK fields) are copied to the undo space, and the record is updated in place.
As shown below:
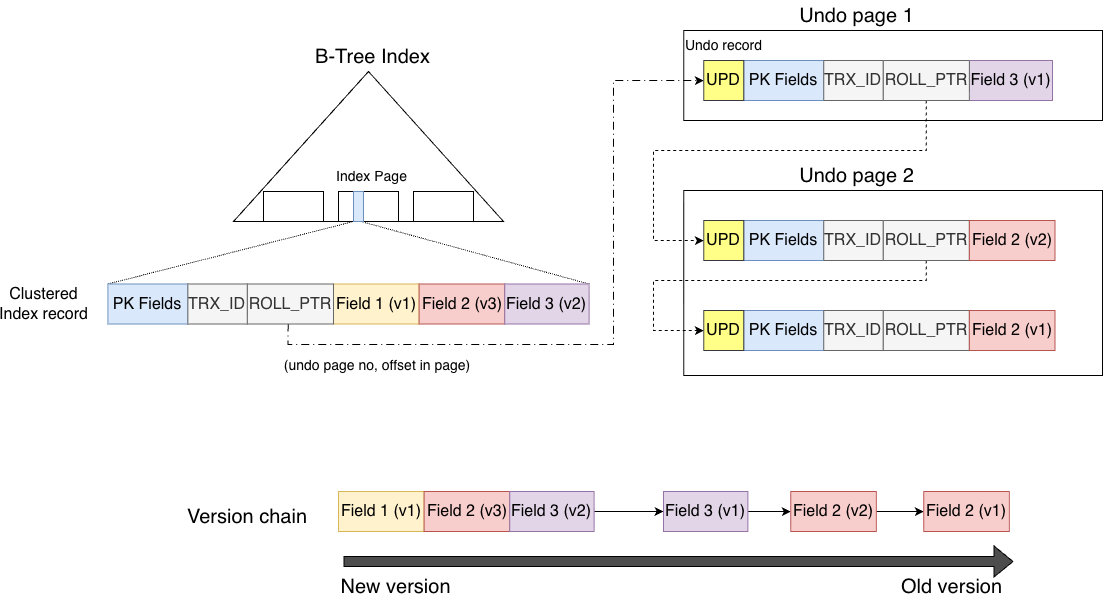
The clustered index record contains two system fields: TRX_ID and ROLL_PTR.
TRX_IDrecords the transaction ID that last modified the record and is used for MVCC visibility checks.ROLL_PTRlinks the version chain.
Similar to PostgreSQL’s ctid, ROLL_PTR links versions together, but the direction is opposite:
ctid points from old to new, while ROLL_PTR points from new to old.
In the figure, the record was modified three times:
- Field 2 was modified
- Field 2 was modified again
- Field 3 was modified
Therefore, the clustered index record stores the latest version after the three modifications. Through ROLL_PTR, it points to the previous version stored in the undo space (the version before Field 3 was modified), and so on.
Summary
The differences in version organization between PostgreSQL and MySQL can be summarized in three contrasts:
- Versions mixed together vs latest version and historical versions stored in different spaces
- Old versions contain full tuples vs old versions mainly store the primary key and old values of modified columns
- Version chain ordered from old to new vs from new to old
2. Visibility Checks for Multiple Versions
Once multiple versions exist, the next question is: how does a read transaction determine which version it should see?
This is the core of MVCC: visibility checks.
To determine visibility, the database must establish an order among transactions. Taking the RR isolation level as an example, when a transaction begins, it must know which write transactions are currently active in the system. All modifications produced by those active transactions are invisible to the read transaction. Only modifications from transactions that were already committed at that moment are visible.
Therefore, if the database can define an order among write transactions, it becomes straightforward to perform visibility checks.
Most databases achieve this by using a globally increasing transaction ID. When a write transaction is created, it obtains the current maximum transaction ID plus one. This naturally orders write transactions.
Once transaction IDs exist, each data modification can be tagged with the transaction ID that produced it. A read transaction, when created, obtains the list of currently active write transactions. Later, when reading data, it simply compares the transaction ID recorded on the data with this list and applies the visibility rules to determine whether the data is visible.
Both PostgreSQL and MySQL follow this approach.
PostgreSQL
As mentioned earlier, transaction IDs are critical. In PostgreSQL, the globally increasing transaction ID is called nextXid.
Each write transaction obtains the latest value when it starts.
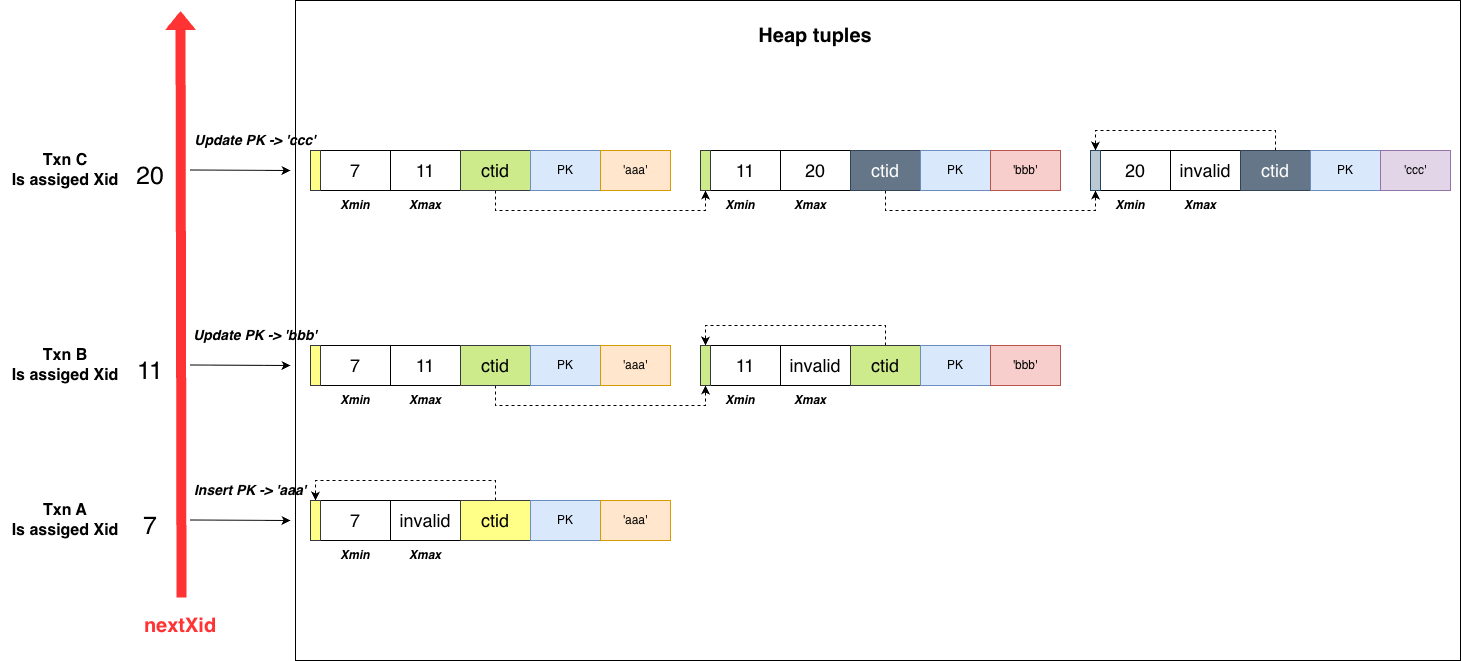
Transaction A is created first and obtains xid 7. It inserts PK: ‘aaa’. The tuple records this through the xmin field, which stores the inserter’s transaction ID (7).
After transaction A commits, transaction B is created and obtains xid 11. It updates the record to ‘bbb’. Following the multi-version rule, transaction B does not overwrite the tuple inserted by A. Instead, it creates a new version. The old tuple’s xmax is set to 11, indicating that transaction 11 has “deleted” this tuple version. The new tuple records xmin = 11. The old tuple’s ctid points to the new tuple.
Transaction C proceeds similarly.

Thus, each PostgreSQL tuple contains two fields recording the related transactions:
xmin: the inserterxmax: the deleter
With the global transaction ID (nextXid) and the transaction tags (xmin, xmax) on each tuple, the next requirement is the snapshot used by read transactions for visibility checks.
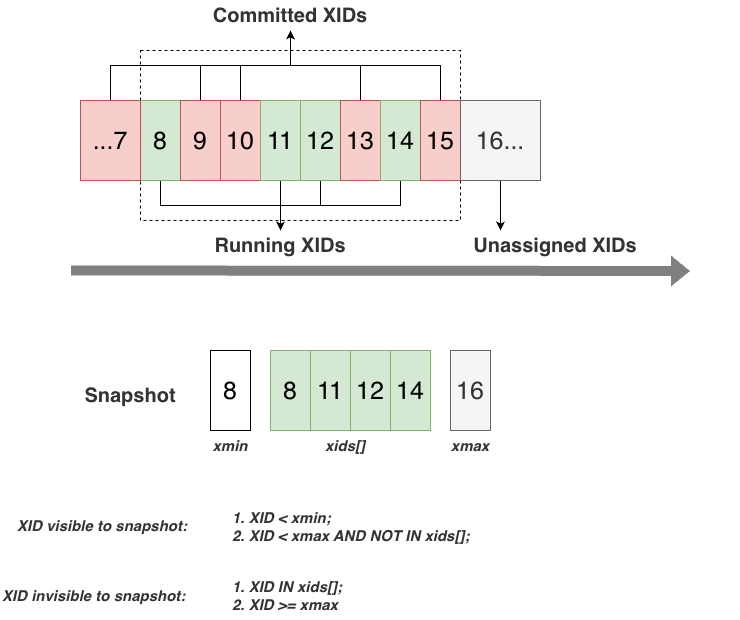
At the top of the figure are the globally increasing transaction IDs and the currently active write transactions. The next ID to allocate is 16. Among all assigned IDs, transactions ≤7 have already committed. Between 8 and 15, some have committed, and the currently active write transactions are 8, 11, 12, and 14.
If a read transaction starts now, it obtains a snapshot:
xmin: the smallest active transaction ID (8)xmax: the next transaction ID to allocate (16)xids[]: the list of active transactions
With this snapshot, it can determine whether a tuple’s transaction tag is visible. For example:
- If a tuple has
xmin = 7, it is visible to the snapshot. - If a tuple has
xmin = 14, it is not visible.
Now that we know how to determine the visibility of transaction tags, the final question is how to determine whether a tuple itself is visible, given that it has both xmin and xmax.
The core principle is:
A tuple is visible to a snapshot if its inserter (
xmin) is visible and its deleter (xmax) is not visible.
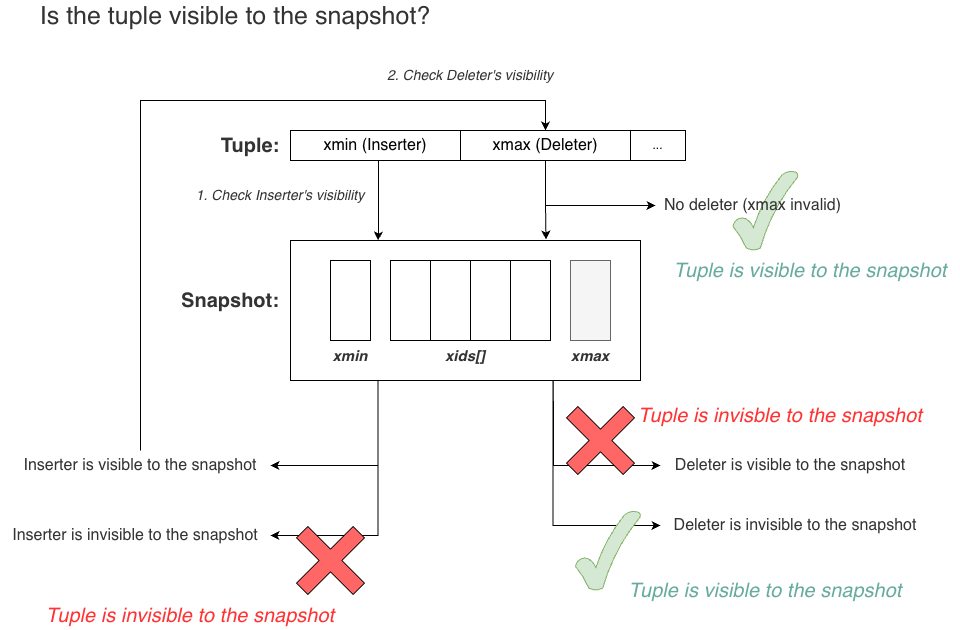
The process is:
- Check
xmin. Ifxminis not visible, the tuple is invisible. - If
xminis visible, checkxmax. - If
xmaxis also visible, the tuple has been deleted in the snapshot and is therefore invisible. - If
xmaxis not visible, the tuple is visible.
Finally, the following figure shows the process of locating a tuple visible to a snapshot starting from the nbtree index:
MySQL
MySQL also has a globally increasing transaction ID called next_trx_id_or_no.
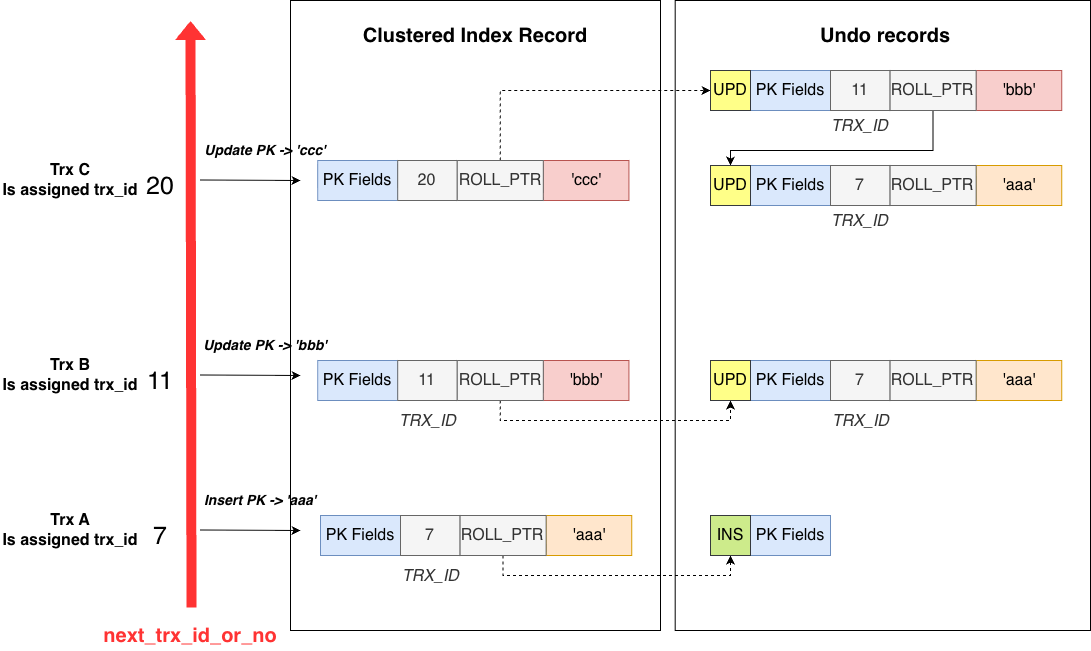
In the example, three transactions modify the same record three times. Both the clustered index record and the undo records contain a TRX_ID field. This field is the transaction tag used by MySQL. The TRX_ID records which transaction created that version of the record.
Unlike PostgreSQL, a record in MySQL has only one transaction tag, TRX_ID, rather than two. The reason will be explained later.
Next, consider the visibility check.
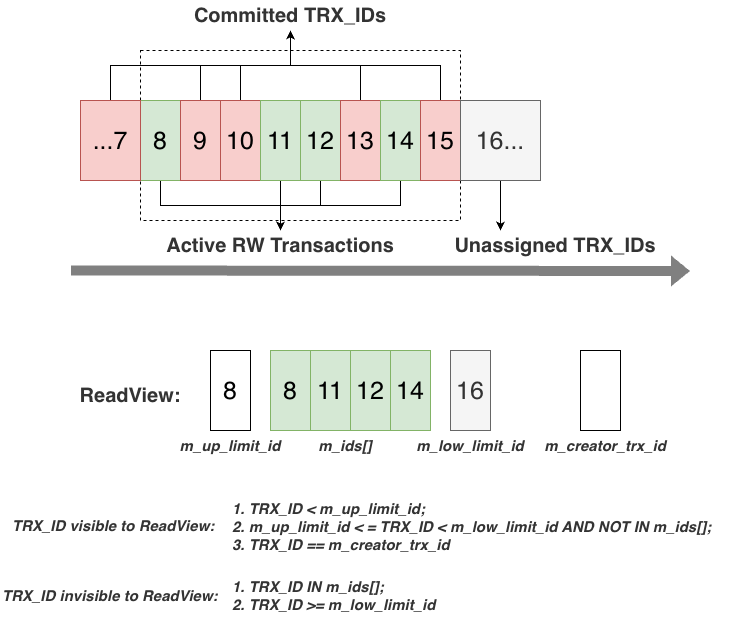
MySQL’s ReadView is extremely similar to PostgreSQL’s snapshot and serves the same purpose. The only difference is that MySQL’s ReadView contains an additional field: m_creator_trx_id.
This field is necessary because the transaction that creates the ReadView is itself included in m_ids[] (since it is an active transaction). Without m_creator_trx_id, the transaction would not be able to see its own modifications. It also handles cases where a read transaction is promoted to a write transaction.
Aside from this, the visibility rules are almost identical.
Given the visibility rules, determining whether a record is visible to a ReadView becomes straightforward:
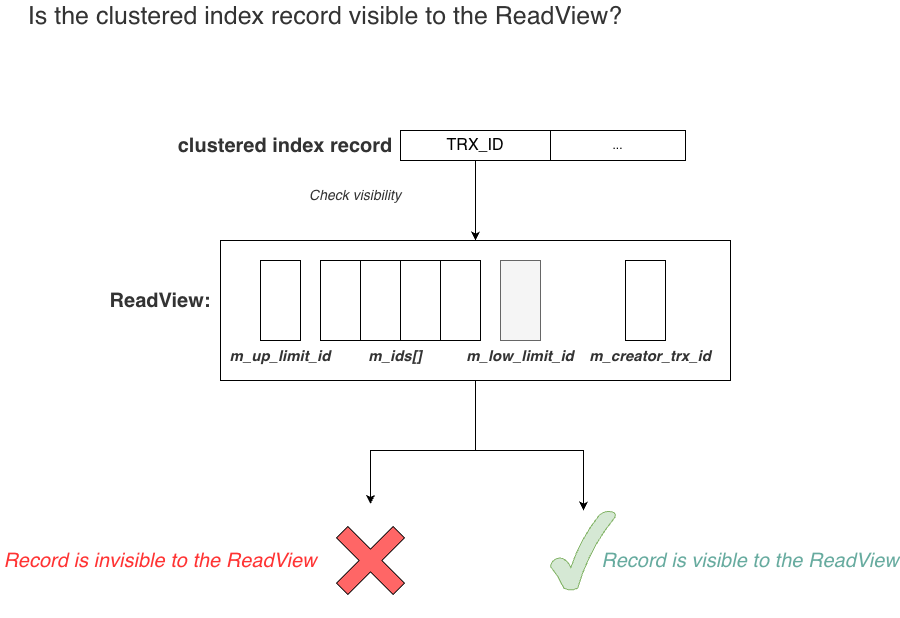
The process is simple: check whether the record’s TRX_ID is visible to the ReadView. Unlike PostgreSQL, MySQL does not need two separate checks for xmin and xmax.
Finally, the process of finding a version visible to a ReadView starting from the B+Tree is shown below:
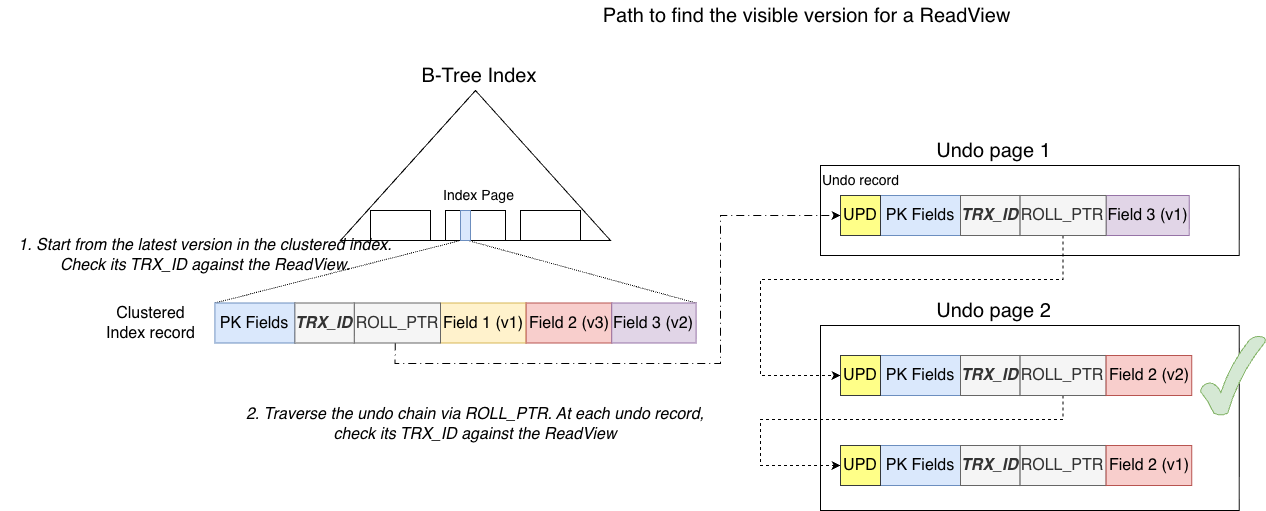
Summary
PostgreSQL and MySQL use highly similar visibility mechanisms. The primary difference is that PostgreSQL stores two transaction tags (xmin and xmax) on each tuple, requiring two checks. MySQL stores only one (TRX_ID), requiring only one check.
Why is this the case? The fundamental reason is the direction of the version chain:
- PostgreSQL’s version chain goes from old to new. In theory,
xminalone would be sufficient because it records the inserter. However, when traversing the chain, the reader cannot stop immediately after finding a visible insert because the next version might also be visible. The reader must continue until it finds the first version whose insert is invisible. The previous version is then the visible version. This means at least one extra step is required. PostgreSQL therefore stores the insert transaction of the next version as the deleter (xmax) of the current version, avoiding that extra traversal. Additionally,xmaxis required for DELETE operations where no next version exists. - MySQL’s version chain goes from new to old. Once the latest version is found to be invisible, the reader simply moves to the previous version until it finds the first visible one. No additional step is required.
3. Garbage Collection of Multiple Versions
The next core problem in MVCC is garbage collection of historical versions. Historical versions are not always needed.
Because global transaction IDs advance linearly, the snapshots (or ReadViews) of read transactions also move forward. A historical version can be safely purged when:
No active snapshot or ReadView in the system still needs that version (i.e., all snapshots can already see the newer version that replaced it).
This is where PostgreSQL and MySQL differ most significantly.
PostgreSQL
PostgreSQL reclaims historical versions through the Vacuum backend.
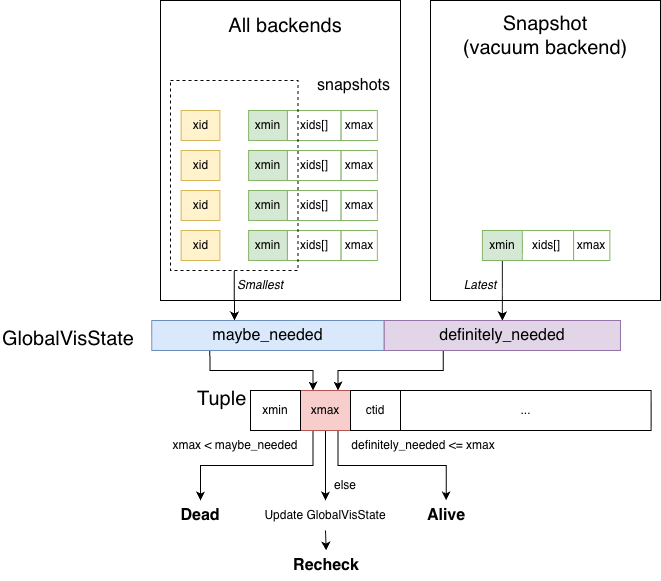
PostgreSQL uses GlobalVisState to track purge boundaries. It contains two variables:
maybe_needed
This is the minimum value among all backend transaction IDs and the xmin values of their snapshots. Backend transaction IDs must be considered because a backend may have started a write transaction and obtained an xid but not yet created a snapshot. That xid still forms a lower bound that cannot be crossed.
All tuple xmax values (deleters) are compared against maybe_needed. If xmax is smaller than maybe_needed, the deleter is visible to all backends and snapshots, meaning the tuple is globally deleted and can be safely purged.
definitely_needed
This is the xmin of the latest snapshot taken by the Vacuum backend. Any tuple whose xmax is greater than or equal to definitely_needed is invisible to the Vacuum backend and cannot be purged.
These two values define the continuous upper bound that can be purged and the lower bound that cannot. For tuples whose xmax falls between these bounds, Vacuum may need to refresh maybe_needed and re-evaluate, since the snapshot used by Vacuum might be outdated. Because refreshing is expensive, PostgreSQL optimizes this by checking whether RecentXmin has advanced. If it has not changed, refreshing is skipped.
With these rules, the workflow of the Vacuum backend is:
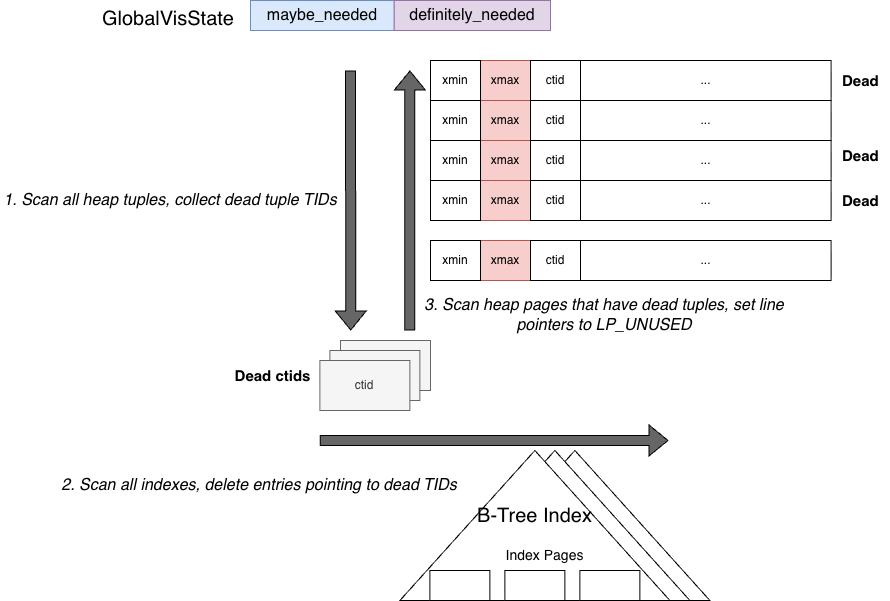
- Scan all heap tuples and determine whether they can be purged using
GlobalVisState. Collect purgable tuples into a set. - Scan all index tuples and check whether they reference heap tuples in the purge set. If so, delete those index tuples.
- Scan again all pages containing dead tuples collected in step 1 and reclaim them (setting their line pointers to
LP_UNUSED).
This process involves extensive scanning of both heap and index structures, which can be expensive. PostgreSQL mitigates this cost with several optimizations:
- Visibility map – allows the first scan to skip pages where all tuples are visible.
- HOT pruning – during normal reads of heap pages, PostgreSQL opportunistically removes dead tuples through
heap_page_prune(), reducing the workload of Vacuum. - LP_REDIRECT – when intermediate versions in a HOT chain are removed, the head line pointer is redirected to the surviving tuple instead of being marked unused, so existing index tuples can still locate the correct tuple without index updates.
MySQL
MySQL takes a different approach.
All undo records (historical versions) are grouped by the transactions that produced them. These transactions are then organized according to their global commit order (forming a min-heap).
With this ordering, MySQL can quickly identify the undo records belonging to the earliest committed transaction, which are typically the closest candidates for purging.
The purge thread compares the transaction number (trx_no) of the earliest transaction in the history list with m_low_limit_no from the purge view.
- If
trx_no < m_low_limit_no, all active ReadViews can see this transaction’s commit, so its undo records are no longer needed and can be safely purged. - Otherwise, it cannot be purged. Since it is the earliest transaction, later ones cannot be purged either, so the purge process stops and waits.
An important optimization is that transactions are ordered by commit order rather than creation order.
Sorting by creation order would be safe because the earliest transaction must be purged first. However, it has a drawback: if the earliest transaction does not commit for a long time, later transactions that have already committed cannot be purged even if they are no longer needed.
For example:
- Trx A is created and modifies record R1 from ‘111’ to ‘222’
- Trx B is created and modifies record R2 from ‘aaa’ to ‘bbb’
- Read-only Trx X starts. Since Trx B has not committed, X sees R2 as ‘aaa’
- Trx B commits
- Trx X commits
If transactions were ordered by creation time, Trx A would come before Trx B. Because Trx A has not committed, purge would be blocked and Trx B’s undo records could not be purged, even though no ReadView needs them anymore.
By ordering transactions by commit time instead, MySQL can purge Trx B’s undo records immediately after its commit.
This is an important optimization. Notably, trx_id and trx_no both come from the same global variable: next_trx_id_or_no.
The workflow is shown below:
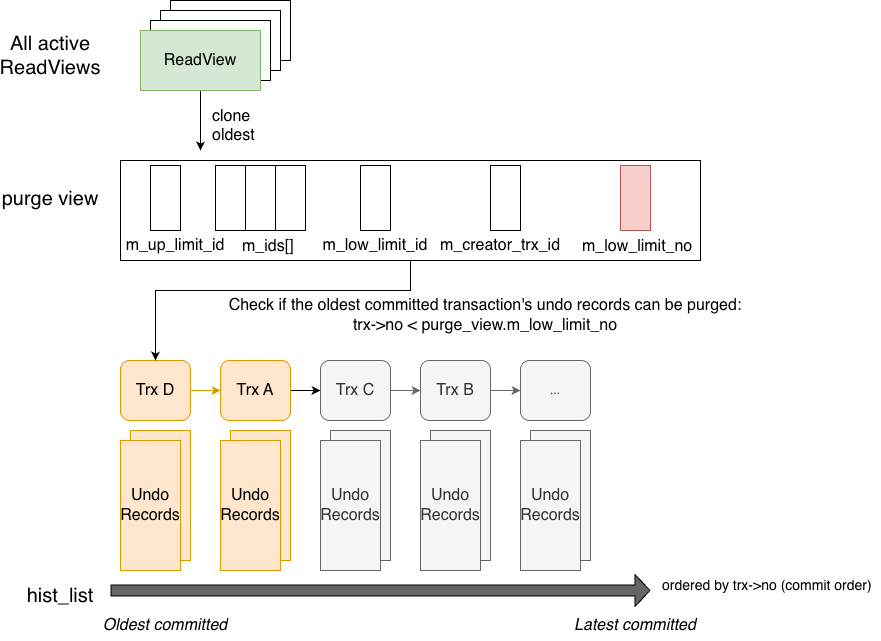
The purge thread first clones the oldest active ReadView in the system. The m_low_limit_no in this ReadView represents the smallest trx_no that was still committing when the view was created. All transactions with smaller trx_no values have already committed.
In the undo space, committed transactions’ undo records are linked together in the history list in commit order (ascending trx_no). The purge thread simply compares m_low_limit_no with the smallest trx_no in the history list to determine whether purging is possible.
Summary
Garbage collection of historical versions is a major implementation difference between PostgreSQL and MySQL.
In fact, it reflects their different design philosophies. This difference was already visible in the previous post discussing buffer pools.
MySQL tends to favor precise control and ordered structures, such as the LRU list and flush list, which allow it to quickly identify the oldest pages that can be evicted or flushed. Similarly, undo purge maintains ordered historical versions so that the oldest purgeable undo records can be quickly located.
PostgreSQL, on the other hand, tends to rely more on global scanning mechanisms, both in shared buffers and in Vacuum. In the buffer pool case, the cost of global scanning is relatively low because it scans descriptor arrays in memory. However, Vacuum must scan heap and index disk pages (although visibility maps can skip many all-visible pages). For frequently updated tables, the amount of scanning can still be substantial.