In my previous blog, I discussed how many B+Tree searches MySQL performs when inserting a record, detailing the process for inserting into both the primary index and unique secondary indexes.
I believe there is room for optimization in the unique secondary index insertion process. In my previous post, I already reported one such optimization, which has since been verified by the MySQL team. In this post, I’d like to discuss another optimization I recently proposed.
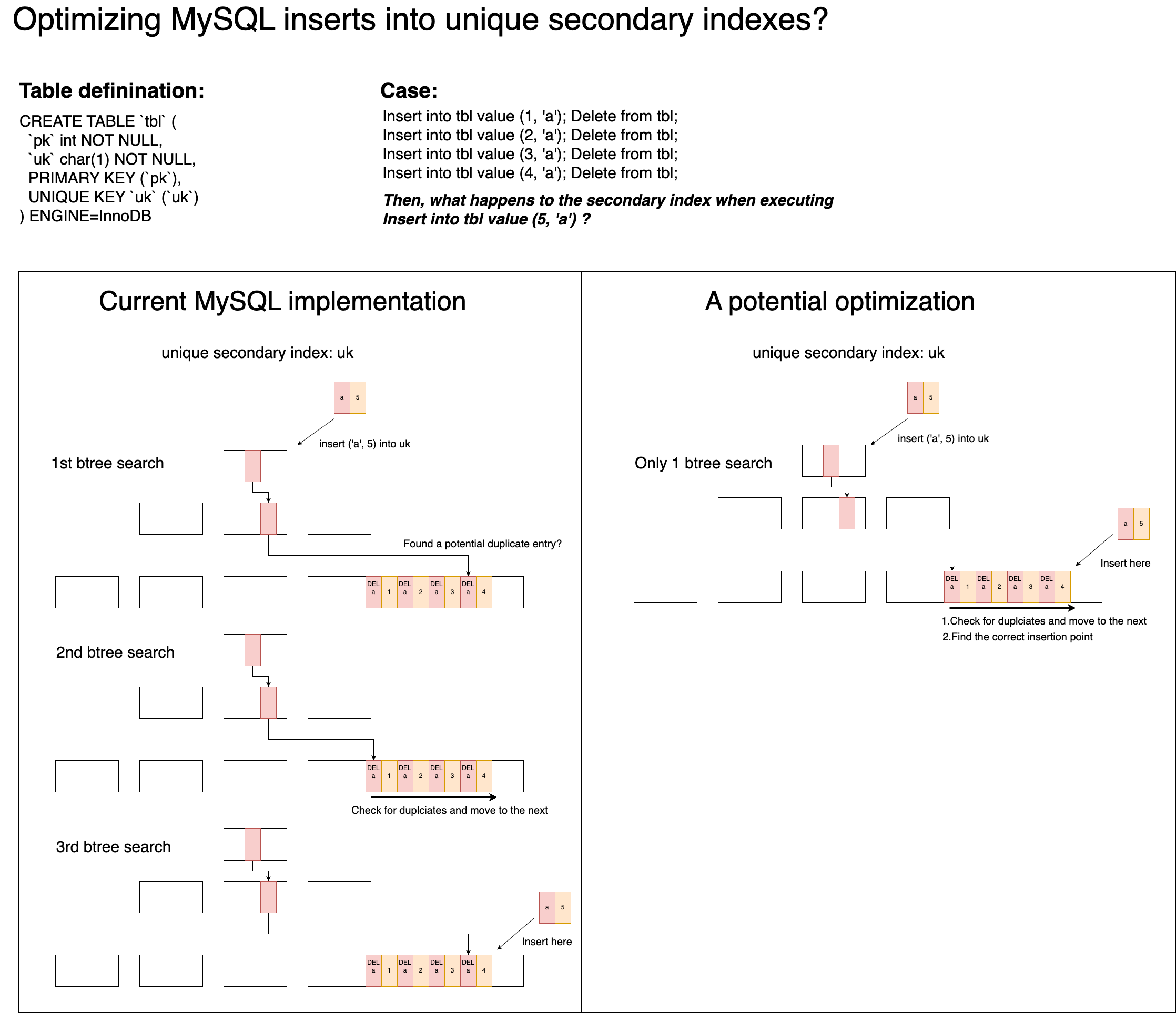
Currently, when inserting an entry into a unique secondary index, MySQL performs the following steps:
- It first does a B+Tree search using all columns of the entry to locate the leaf page insertion point. If it finds a record with matching index columns, it suggests a potential duplicate, so it proceeds to the next step.
- It does another B+Tree search using only the index columns to locate the first record with matching index columns. It then iterates (using
next) to check for actual duplicates, considering that records marked as deleted don’t count as duplicates. If no duplicate is found, it continues to the next step. - It performs a final B+Tree search using all columns of the entry to find the insertion point and then inserts the entry.
As you can see, this process involves 3 separate B+Tree searches. This is mainly because unique secondary indexes in InnoDB cannot be updated in place; they rely on a delete-mark and insert approach. Since multiple records can share the same index column values (including deleted-marked ones), MySQL has to perform these extra checks to ensure uniqueness.
Each of these B+Tree searches acquires at least one page latch at each tree level, which can become a concurrency bottleneck, especially during page splits or merges.
How can we optimize this?
I believe we can reduce the number of B+Tree searches for unique secondary indexes. Specifically, we could skip the initial B+Tree search that uses all columns as the search pattern. The revised process would be:
- Use a B+Tree search with only the index columns to locate the first record with matching index columns. Then iterate (using
next) through subsequent records to confirm whether an actual duplicate exists, while also identifying the final insertion point (including comparing the full entry columns when needed). If no duplicate is found, we can directly insert the entry at the determined insertion point.
This approach would reduce the number of B+Tree searches from 3 to 1, significantly reducing the chances of concurrency conflicts. All duplicate checks would happen within one or just a few adjacent leaf pages, making the lock granularity much smaller. Importantly, even in the worst case, the number of entry-record comparisons wouldn’t exceed what the current implementation requires.
I’ve already submitted a report with this idea to the MySQL team. I’m hoping it can generate some interesting discussions around this optimization.